A Curriculum-style Self-training Approach for Source-Free Semantic Segmentation

0
🏋️
Sign in to get full access
Overview
- Source-free domain adaptation aims to adapt a well-trained source model to a target domain without access to the original source data.
- This is a challenging problem as many feature alignment techniques from prior domain adaptation methods are not feasible.
- The paper proposes a curriculum-style self-training approach to address source-free domain adaptive semantic segmentation.
Plain English Explanation
In source-free domain adaptation, the goal is to take a machine learning model that has been trained on one dataset (the "source" domain) and adapt it to work well on a different dataset (the "target" domain), without having access to the original source data. This could be useful for protecting privacy or intellectual property.
However, many of the techniques used in traditional domain adaptation, which involves access to both source and target data, don't work as well in this more constrained "source-free" setting. To address this, the researchers propose a "curriculum-style self-training" approach.
The key idea is to start by having the source model make "easy" predictions on the target data, and then gradually move to "harder" predictions, using a curriculum learning strategy. The easy predictions are used to generate "positive" pseudo-labels, while the harder, more uncertain predictions are used to generate "negative" pseudo-labels that indicate which classes are absent.
The model is then trained on this mix of positive and negative pseudo-labels, using a self-training approach. Additionally, the method employs an "information propagation" scheme to further reduce differences between samples within the target domain.
The researchers show that this curriculum-style self-training approach achieves state-of-the-art performance on source-free semantic segmentation tasks, even in challenging scenarios where only the source model's predictions are available (the "black-box" setting).
Technical Explanation
The paper proposes a curriculum-style self-training approach for source-free domain adaptive semantic segmentation. The key elements are:
-
Curriculum-style entropy minimization: The method starts by using the source model to make "easy" (high confidence) predictions on the target data, and gradually moves to "harder" (lower confidence) predictions. This exploits the implicit knowledge from the source model.
-
Complementary curriculum-style self-training: The model is trained using both "positive" pseudo-labels (from the high-confidence predictions) and "negative" pseudo-labels (from the low-confidence predictions). The negative labels indicate absent classes, which can provide useful information.
-
Information propagation: An additional step is used to further reduce the discrepancy between samples within the target domain, acting as a standard post-processing method for domain adaptation.
-
Black-box setting: The method is extended to the more challenging scenario where only the source model's predictions are available, without access to the source model itself (the "black-box" setting).
Extensive experiments show that this approach achieves state-of-the-art performance on source-free semantic segmentation tasks, for both synthetic-to-real and adverse condition datasets.
Critical Analysis
The paper presents a novel and effective approach to the challenging problem of source-free domain adaptation. The curriculum-style self-training method is a clever way to leverage the implicit knowledge in the source model, even when the source data is unavailable.
One potential limitation is that the negative pseudo-labels, while useful for indicating absent classes, may not be 100% accurate in terms of the specific class assignments. The paper acknowledges this and shows that the method is still effective despite this.
Another area for further research could be exploring ways to further improve the information propagation step, perhaps by incorporating more sophisticated techniques for reducing intra-domain discrepancies.
Overall, this paper presents a strong contribution to the field of source-free domain adaptation, with practical applications in areas where data privacy and intellectual property protection are important concerns.
Conclusion
This paper introduces a novel curriculum-style self-training approach for source-free domain adaptive semantic segmentation. By exploiting the implicit knowledge in the source model and using a mix of positive and negative pseudo-labels, the method achieves state-of-the-art performance, even in challenging "black-box" scenarios where only the source model's predictions are available.
This work advances the field of source-free domain adaptation, which is an important problem for practical applications where data privacy and intellectual property protection are key concerns. The proposed techniques could have significant impact in real-world settings where machine learning models need to be adapted to new domains without access to the original training data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏋️
0
A Curriculum-style Self-training Approach for Source-Free Semantic Segmentation
Yuxi Wang, Jian Liang, Zhaoxiang Zhang
Source-free domain adaptation has developed rapidly in recent years, where the well-trained source model is adapted to the target domain instead of the source data, offering the potential for privacy concerns and intellectual property protection. However, a number of feature alignment techniques in prior domain adaptation methods are not feasible in this challenging problem setting. Thereby, we resort to probing inherent domain-invariant feature learning and propose a curriculum-style self-training approach for source-free domain adaptive semantic segmentation. In particular, we introduce a curriculum-style entropy minimization method to explore the implicit knowledge from the source model, which fits the trained source model to the target data using certain information from easy-to-hard predictions. We then train the segmentation network by the proposed complementary curriculum-style self-training, which utilizes the negative and positive pseudo labels following the curriculum-learning manner. Although negative pseudo-labels with high uncertainty cannot be identified with the correct labels, they can definitely indicate absent classes. Moreover, we employ an information propagation scheme to further reduce the intra-domain discrepancy within the target domain, which could act as a standard post-processing method for the domain adaptation field. Furthermore, we extend the proposed method to a more challenging black-box source model scenario where only the source model's predictions are available. Extensive experiments validate that our method yields state-of-the-art performance on source-free semantic segmentation tasks for both synthetic-to-real and adverse conditions datasets. The code and corresponding trained models are released at url{https://github.com/yxiwang/ATP}.
Read more7/22/2024
🏋️
0
Self-training via Metric Learning for Source-Free Domain Adaptation of Semantic Segmentation
Ibrahim Batuhan Akkaya, Ugur Halici
Unsupervised source-free domain adaptation methods aim to train a model for the target domain utilizing a pretrained source-domain model and unlabeled target-domain data, particularly when accessibility to source data is restricted due to intellectual property or privacy concerns. Traditional methods usually use self-training with pseudo-labeling, which is often subjected to thresholding based on prediction confidence. However, such thresholding limits the effectiveness of self-training due to insufficient supervision. This issue becomes more severe in a source-free setting, where supervision comes solely from the predictions of the pre-trained source model. In this study, we propose a novel approach by incorporating a mean-teacher model, wherein the student network is trained using all predictions from the teacher network. Instead of employing thresholding on predictions, we introduce a method to weight the gradients calculated from pseudo-labels based on the reliability of the teacher's predictions. To assess reliability, we introduce a novel approach using proxy-based metric learning. Our method is evaluated in synthetic-to-real and cross-city scenarios, demonstrating superior performance compared to existing state-of-the-art methods.
Read more4/10/2024

0
PiPa++: Towards Unification of Domain Adaptive Semantic Segmentation via Self-supervised Learning
Mu Chen, Zhedong Zheng, Yi Yang
Unsupervised domain adaptive segmentation aims to improve the segmentation accuracy of models on target domains without relying on labeled data from those domains. This approach is crucial when labeled target domain data is scarce or unavailable. It seeks to align the feature representations of the source domain (where labeled data is available) and the target domain (where only unlabeled data is present), thus enabling the model to generalize well to the target domain. Current image- and video-level domain adaptation have been addressed using different and specialized frameworks, training strategies and optimizations despite their underlying connections. In this paper, we propose a unified framework PiPa++, which leverages the core idea of ``comparing'' to (1) explicitly encourage learning of discriminative pixel-wise features with intraclass compactness and inter-class separability, (2) promote the robust feature learning of the identical patch against different contexts or fluctuations, and (3) enable the learning of temporal continuity under dynamic environments. With the designed task-smart contrastive sampling strategy, PiPa++ enables the mining of more informative training samples according to the task demand. Extensive experiments demonstrate the effectiveness of our method on both image-level and video-level domain adaption benchmarks. Moreover, the proposed method is compatible with other UDA approaches to further improve the performance without introducing extra parameters.
Read more7/25/2024
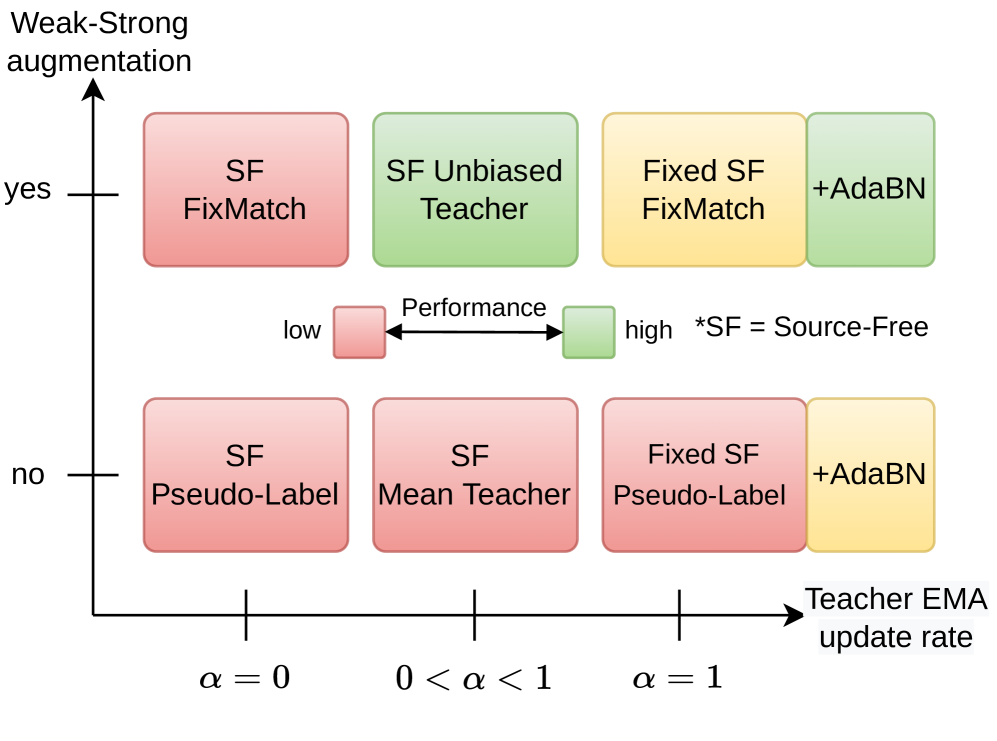
0
Simplifying Source-Free Domain Adaptation for Object Detection: Effective Self-Training Strategies and Performance Insights
Yan Hao, Florent Forest, Olga Fink
This paper focuses on source-free domain adaptation for object detection in computer vision. This task is challenging and of great practical interest, due to the cost of obtaining annotated data sets for every new domain. Recent research has proposed various solutions for Source-Free Object Detection (SFOD), most being variations of teacher-student architectures with diverse feature alignment, regularization and pseudo-label selection strategies. Our work investigates simpler approaches and their performance compared to more complex SFOD methods in several adaptation scenarios. We highlight the importance of batch normalization layers in the detector backbone, and show that adapting only the batch statistics is a strong baseline for SFOD. We propose a simple extension of a Mean Teacher with strong-weak augmentation in the source-free setting, Source-Free Unbiased Teacher (SF-UT), and show that it actually outperforms most of the previous SFOD methods. Additionally, we showcase that an even simpler strategy consisting in training on a fixed set of pseudo-labels can achieve similar performance to the more complex teacher-student mutual learning, while being computationally efficient and mitigating the major issue of teacher-student collapse. We conduct experiments on several adaptation tasks using benchmark driving datasets including (Foggy)Cityscapes, Sim10k and KITTI, and achieve a notable improvement of 4.7% AP50 on Cityscapes$rightarrow$Foggy-Cityscapes compared with the latest state-of-the-art in SFOD. Source code is available at https://github.com/EPFL-IMOS/simple-SFOD.
Read more7/11/2024