PiPa++: Towards Unification of Domain Adaptive Semantic Segmentation via Self-supervised Learning

0

Sign in to get full access
Overview
- The paper proposes PiPa++, a unified architecture for domain-adaptive semantic segmentation using self-supervised learning.
- It aims to address the challenge of adapting deep learning models to different domains without access to labeled target data.
- The key ideas are to leverage self-supervised pretraining and a modular network design to enable unified domain adaptation across diverse scenarios.
Plain English Explanation
The research paper presents a new approach called PiPa++ that helps machine learning models adapt to different real-world environments and situations. This is an important problem because AI models trained in one setting often struggle when applied to new, unfamiliar environments.
PiPa++ works by leveraging self-supervised learning. This means the model learns useful representations of the visual world on its own, without being explicitly told what everything is. It can then use this general knowledge to more easily adapt to new situations, rather than having to learn everything from scratch.
The paper also introduces a modular network design that makes it easier to adapt the model to different tasks and environments. Instead of a single, rigid model, PiPa++ is made up of smaller, interchangeable components that can be swapped in and out as needed.
Overall, the key insight is that combining self-supervised learning and modular architectures can enable AI systems to more seamlessly adapt to the real-world complexities they encounter, without requiring extensive retraining or manually labeled data for each new environment.
Technical Explanation
The authors of the paper propose a novel architecture called PiPa++ that aims to unify domain-adaptive semantic segmentation through self-supervised learning. The core idea is to leverage self-supervised pretraining and a modular network design to enable efficient adaptation to diverse target domains without access to labeled data.
The self-supervised pretraining stage allows the model to learn useful visual representations from unlabeled data. This general knowledge can then be transferred to the target domain, facilitating faster adaptation compared to training from scratch.
The modular network architecture of PiPa++ consists of several interchangeable components, including a shared backbone, domain-specific adapters, and task-specific heads. This design enables efficient adaptation by only fine-tuning the relevant modules for a given target domain, rather than the entire network.
The authors evaluate PiPa++ on several domain adaptation benchmarks and demonstrate its effectiveness in outperforming existing approaches, particularly in scenarios with limited target domain data.
Critical Analysis
The paper presents a compelling approach to the challenging problem of domain-adaptive semantic segmentation. The key strengths of the proposed PiPa++ system are its ability to leverage self-supervised learning and its modular architecture, which together enable efficient adaptation to diverse real-world environments.
However, the paper does not fully address potential limitations or caveats of the approach. For example, the extent to which the self-supervised pretraining can effectively capture the necessary visual knowledge for all possible target domains is not clearly demonstrated. Additionally, the paper does not discuss the computational and memory overhead associated with the modular architecture, which could be a concern for deployment in resource-constrained settings.
Further research could explore ways to improve the robustness and generalization capabilities of the self-supervised pretraining, as well as investigate more efficient modular network designs. Assessing the performance of PiPa++ on a wider range of domain adaptation scenarios, including more challenging or specialized tasks, would also help strengthen the claims and potential impact of this work.
Conclusion
The PiPa++ framework presented in this paper represents a promising step towards unifying domain-adaptive semantic segmentation through the use of self-supervised learning and modular network architectures. By leveraging these techniques, the approach demonstrates the ability to adapt deep learning models to diverse real-world environments more efficiently than previous methods.
While the paper leaves room for further refinement and exploration, the core ideas of PiPa++ have the potential to enhance the flexibility and deployability of AI systems in a wide range of applications, from autonomous vehicles to robotic assistants. As the field of domain adaptation continues to evolve, this work contributes valuable insights and a strong foundation for future research in this important area of machine learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
PiPa++: Towards Unification of Domain Adaptive Semantic Segmentation via Self-supervised Learning
Mu Chen, Zhedong Zheng, Yi Yang
Unsupervised domain adaptive segmentation aims to improve the segmentation accuracy of models on target domains without relying on labeled data from those domains. This approach is crucial when labeled target domain data is scarce or unavailable. It seeks to align the feature representations of the source domain (where labeled data is available) and the target domain (where only unlabeled data is present), thus enabling the model to generalize well to the target domain. Current image- and video-level domain adaptation have been addressed using different and specialized frameworks, training strategies and optimizations despite their underlying connections. In this paper, we propose a unified framework PiPa++, which leverages the core idea of ``comparing'' to (1) explicitly encourage learning of discriminative pixel-wise features with intraclass compactness and inter-class separability, (2) promote the robust feature learning of the identical patch against different contexts or fluctuations, and (3) enable the learning of temporal continuity under dynamic environments. With the designed task-smart contrastive sampling strategy, PiPa++ enables the mining of more informative training samples according to the task demand. Extensive experiments demonstrate the effectiveness of our method on both image-level and video-level domain adaption benchmarks. Moreover, the proposed method is compatible with other UDA approaches to further improve the performance without introducing extra parameters.
Read more7/25/2024

0
Language-Guided Instance-Aware Domain-Adaptive Panoptic Segmentation
Elham Amin Mansour, Ozan Unal, Suman Saha, Benjamin Bejar, Luc Van Gool
The increasing relevance of panoptic segmentation is tied to the advancements in autonomous driving and AR/VR applications. However, the deployment of such models has been limited due to the expensive nature of dense data annotation, giving rise to unsupervised domain adaptation (UDA). A key challenge in panoptic UDA is reducing the domain gap between a labeled source and an unlabeled target domain while harmonizing the subtasks of semantic and instance segmentation to limit catastrophic interference. While considerable progress has been achieved, existing approaches mainly focus on the adaptation of semantic segmentation. In this work, we focus on incorporating instance-level adaptation via a novel instance-aware cross-domain mixing strategy IMix. IMix significantly enhances the panoptic quality by improving instance segmentation performance. Specifically, we propose inserting high-confidence predicted instances from the target domain onto source images, retaining the exhaustiveness of the resulting pseudo-labels while reducing the injected confirmation bias. Nevertheless, such an enhancement comes at the cost of degraded semantic performance, attributed to catastrophic forgetting. To mitigate this issue, we regularize our semantic branch by employing CLIP-based domain alignment (CDA), exploiting the domain-robustness of natural language prompts. Finally, we present an end-to-end model incorporating these two mechanisms called LIDAPS, achieving state-of-the-art results on all popular panoptic UDA benchmarks.
Read more4/8/2024
📈
0
Unified Domain Adaptive Semantic Segmentation
Zhe Zhang, Gaochang Wu, Jing Zhang, Xiatian Zhu, Dacheng Tao, Tianyou Chai
Unsupervised Domain Adaptive Semantic Segmentation (UDA-SS) aims to transfer the supervision from a labeled source domain to an unlabeled target domain. The majority of existing UDA-SS works typically consider images whilst recent attempts have extended further to tackle videos by modeling the temporal dimension. Although the two lines of research share the major challenges -- overcoming the underlying domain distribution shift, their studies are largely independent, resulting in fragmented insights, a lack of holistic understanding, and missed opportunities for cross-pollination of ideas. This fragmentation prevents the unification of methods, leading to redundant efforts and suboptimal knowledge transfer across image and video domains. Under this observation, we advocate unifying the study of UDA-SS across video and image scenarios, enabling a more comprehensive understanding, synergistic advancements, and efficient knowledge sharing. To that end, we explore the unified UDA-SS from a general data augmentation perspective, serving as a unifying conceptual framework, enabling improved generalization, and potential for cross-pollination of ideas, ultimately contributing to the overall progress and practical impact of this field of research. Specifically, we propose a Quad-directional Mixup (QuadMix) method, characterized by tackling distinct point attributes and feature inconsistencies through four-directional paths for intra- and inter-domain mixing in a feature space. To deal with temporal shifts with videos, we incorporate optical flow-guided feature aggregation across spatial and temporal dimensions for fine-grained domain alignment. Extensive experiments show that our method outperforms the state-of-the-art works by large margins on four challenging UDA-SS benchmarks. Our source code and models will be released at url{https://github.com/ZHE-SAPI/UDASS}.
Read more9/14/2024
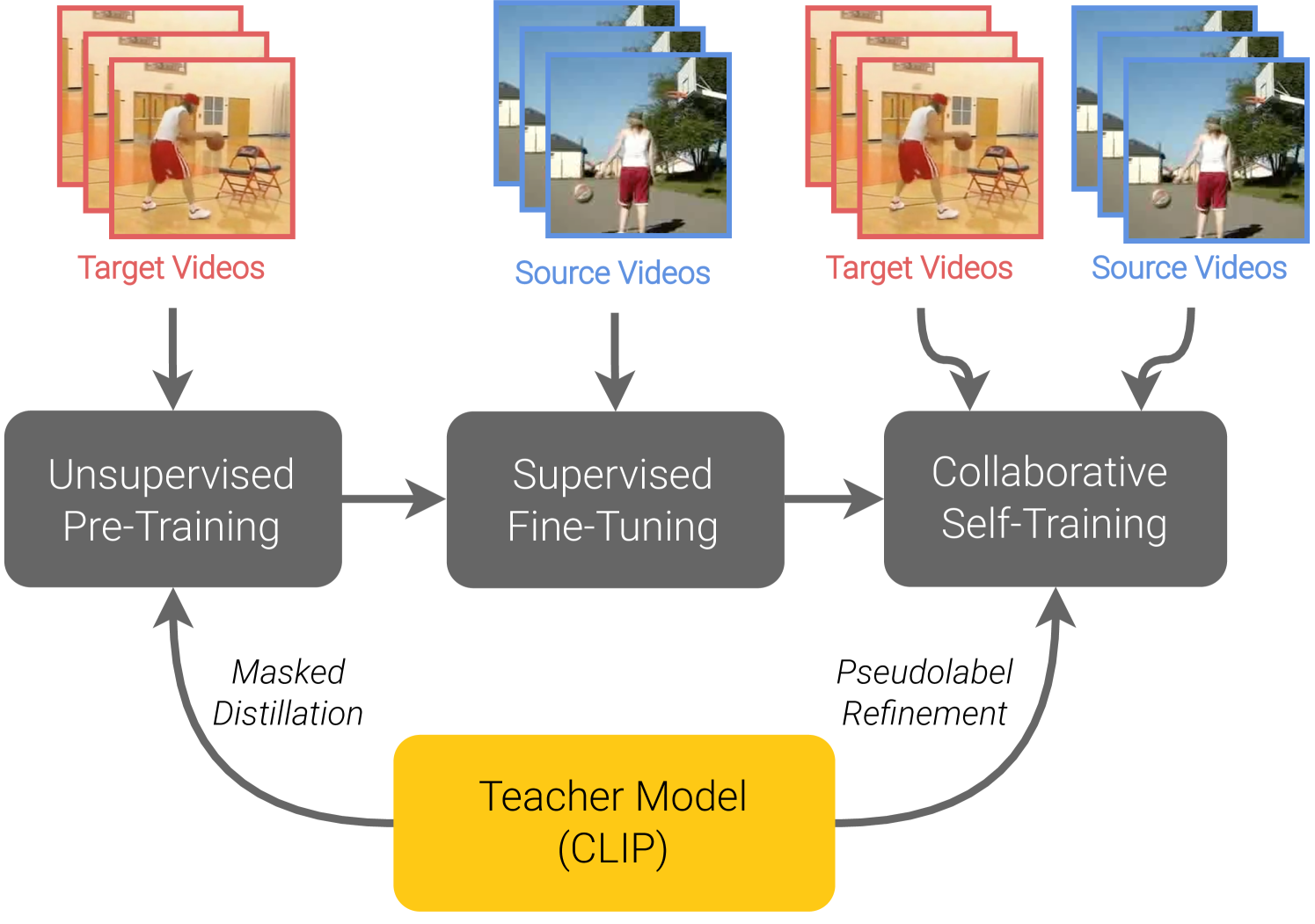
0
Unsupervised Video Domain Adaptation with Masked Pre-Training and Collaborative Self-Training
Arun Reddy, William Paul, Corban Rivera, Ketul Shah, Celso M. de Melo, Rama Chellappa
In this work, we tackle the problem of unsupervised domain adaptation (UDA) for video action recognition. Our approach, which we call UNITE, uses an image teacher model to adapt a video student model to the target domain. UNITE first employs self-supervised pre-training to promote discriminative feature learning on target domain videos using a teacher-guided masked distillation objective. We then perform self-training on masked target data, using the video student model and image teacher model together to generate improved pseudolabels for unlabeled target videos. Our self-training process successfully leverages the strengths of both models to achieve strong transfer performance across domains. We evaluate our approach on multiple video domain adaptation benchmarks and observe significant improvements upon previously reported results.
Read more4/23/2024