CUS3D :CLIP-based Unsupervised 3D Segmentation via Object-level Denoise

0

Sign in to get full access
Overview
- The paper presents CUS3D, a novel approach for unsupervised 3D object segmentation using CLIP (Contrastive Language-Image Pretraining).
- CUS3D leverages CLIP's object-level understanding to denoise 3D point clouds and obtain high-quality segmentation masks without any labeled data.
- The method achieves state-of-the-art performance on several 3D segmentation benchmarks.
Plain English Explanation
CUS3D: CLIP-based Unsupervised 3D Segmentation via Object-level Denoise is a new technique for automatically separating 3D scans of objects into their individual components without using any labeled training data.
The key idea is to use a powerful AI model called CLIP that has been trained to understand the relationship between images and language. CLIP can recognize objects in 2D images and describe them using words. The researchers found a way to apply CLIP's object-level understanding to 3D point clouds, allowing it to identify the different objects present and remove any background noise or clutter.
By leveraging CLIP's capabilities, CUS3D can segment 3D scans into individual objects without needing any human-labeled training data. This is valuable because collecting and annotating 3D data is time-consuming and expensive. CUS3D's unsupervised approach sidesteps this challenge, making 3D segmentation more accessible.
The paper shows that CUS3D outperforms other state-of-the-art unsupervised 3D segmentation methods on several benchmark datasets. This suggests the approach is a promising direction for enabling automated understanding and analysis of 3D environments.
Technical Explanation
The CUS3D method works by first using CLIP to obtain a semantic embedding for each 3D point in the input point cloud. These embeddings capture CLIP's understanding of the object-level semantics present.
CUS3D then applies an object-level denoising step that leverages the CLIP embeddings to filter out background clutter and isolate the individual objects. This is done by clustering the CLIP embeddings and removing any clusters that are deemed to be noise based on their size and compactness.
The final segmentation masks are obtained by grouping the remaining denoised points based on their proximity in 3D space. This simple yet effective approach allows CUS3D to achieve high-quality 3D object segmentation without any labeled training data.
Critical Analysis
The paper provides a thorough evaluation of CUS3D on several 3D segmentation benchmarks, demonstrating its state-of-the-art performance compared to other unsupervised methods. However, the authors acknowledge that CUS3D may struggle in scenarios with heavy occlusion or complex object arrangements, as the CLIP-based denoising step could inadvertently remove important object details.
Additionally, while the use of CLIP provides a powerful way to leverage semantic understanding, the method is still dependent on the capabilities and biases present in the CLIP model itself. Further research is needed to understand how CUS3D's performance may be affected by updates or variations to the underlying CLIP architecture.
Overall, CUS3D represents an exciting step forward in unsupervised 3D segmentation, showcasing how large language models like CLIP can be effectively applied to 3D perception tasks. The method's strong results and conceptual simplicity make it a promising direction for future work in this area.
Conclusion
CUS3D presents a novel unsupervised approach for 3D object segmentation that leverages the powerful semantic understanding of the CLIP model. By using CLIP's object-level embeddings to denoise 3D point clouds, CUS3D can achieve high-quality segmentation results without requiring any labeled training data.
The paper's findings demonstrate the potential of large language models to enable new breakthroughs in 3D perception and scene understanding. As 3D data becomes increasingly ubiquitous, techniques like CUS3D will be crucial for making sense of these complex environments in an automated and scalable way.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
CUS3D :CLIP-based Unsupervised 3D Segmentation via Object-level Denoise
Fuyang Yu, Runze Tian, Zhen Wang, Xiaochuan Wang, Xiaohui Liang
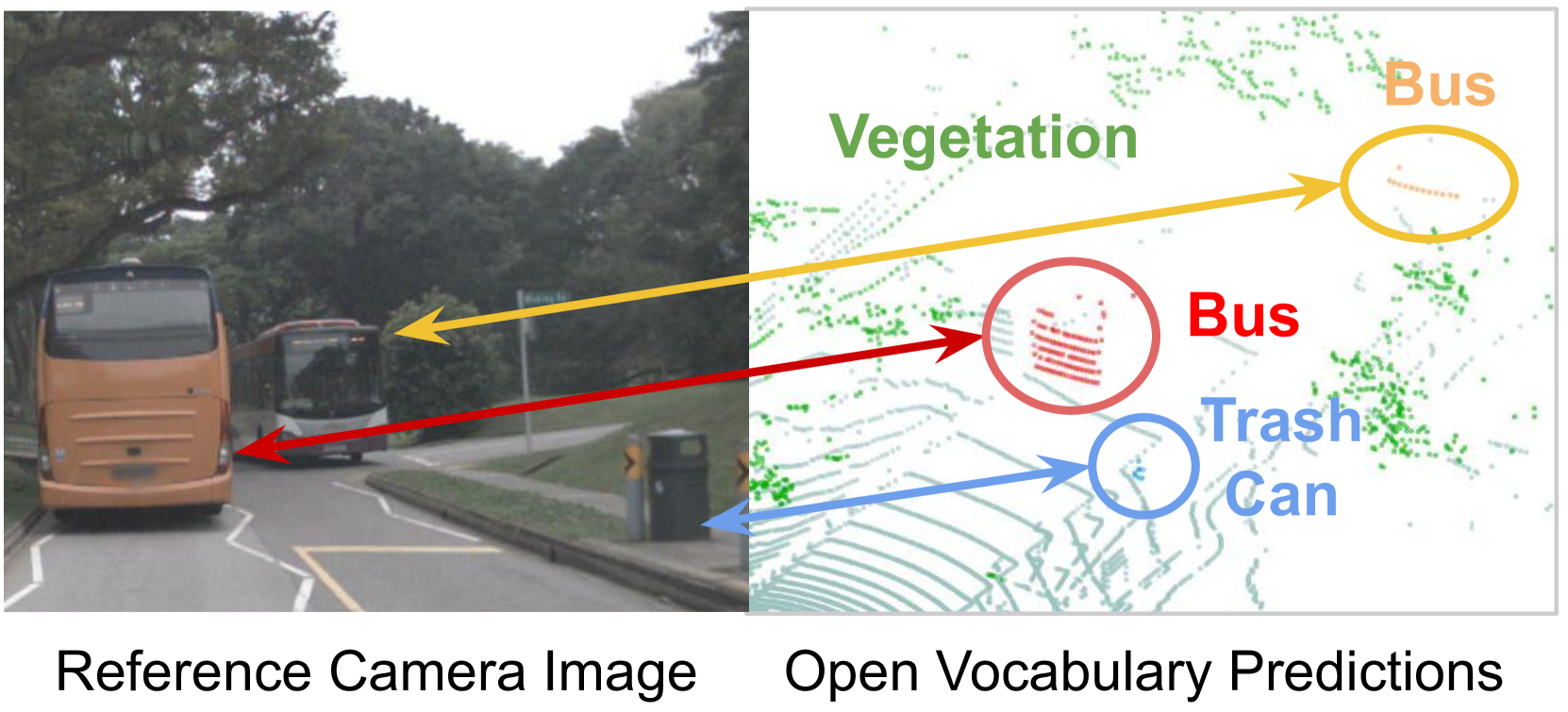
To ease the difficulty of acquiring annotation labels in 3D data, a common method is using unsupervised and open-vocabulary semantic segmentation, which leverage 2D CLIP semantic knowledge. In this paper, unlike previous research that ignores the ``noise'' raised during feature projection from 2D to 3D, we propose a novel distillation learning framework named CUS3D. In our approach, an object-level denosing projection module is designed to screen out the ``noise'' and ensure more accurate 3D feature. Based on the obtained features, a multimodal distillation learning module is designed to align the 3D feature with CLIP semantic feature space with object-centered constrains to achieve advanced unsupervised semantic segmentation. We conduct comprehensive experiments in both unsupervised and open-vocabulary segmentation, and the results consistently showcase the superiority of our model in achieving advanced unsupervised segmentation results and its effectiveness in open-vocabulary segmentation.
Read more9/24/2024
0
3D Open-Vocabulary Panoptic Segmentation with 2D-3D Vision-Language Distillation
Zihao Xiao, Longlong Jing, Shangxuan Wu, Alex Zihao Zhu, Jingwei Ji, Chiyu Max Jiang, Wei-Chih Hung, Thomas Funkhouser, Weicheng Kuo, Anelia Angelova, Yin Zhou, Shiwei Sheng
3D panoptic segmentation is a challenging perception task, especially in autonomous driving. It aims to predict both semantic and instance annotations for 3D points in a scene. Although prior 3D panoptic segmentation approaches have achieved great performance on closed-set benchmarks, generalizing these approaches to unseen things and unseen stuff categories remains an open problem. For unseen object categories, 2D open-vocabulary segmentation has achieved promising results that solely rely on frozen CLIP backbones and ensembling multiple classification outputs. However, we find that simply extending these 2D models to 3D does not guarantee good performance due to poor per-mask classification quality, especially for novel stuff categories. In this paper, we propose the first method to tackle 3D open-vocabulary panoptic segmentation. Our model takes advantage of the fusion between learnable LiDAR features and dense frozen vision CLIP features, using a single classification head to make predictions for both base and novel classes. To further improve the classification performance on novel classes and leverage the CLIP model, we propose two novel loss functions: object-level distillation loss and voxel-level distillation loss. Our experiments on the nuScenes and SemanticKITTI datasets show that our method outperforms the strong baseline by a large margin.
Read more4/4/2024
🤷
0
UnScene3D: Unsupervised 3D Instance Segmentation for Indoor Scenes
David Rozenberszki, Or Litany, Angela Dai
3D instance segmentation is fundamental to geometric understanding of the world around us. Existing methods for instance segmentation of 3D scenes rely on supervision from expensive, manual 3D annotations. We propose UnScene3D, the first fully unsupervised 3D learning approach for class-agnostic 3D instance segmentation of indoor scans. UnScene3D first generates pseudo masks by leveraging self-supervised color and geometry features to find potential object regions. We operate on a basis of geometric oversegmentation, enabling efficient representation and learning on high-resolution 3D data. The coarse proposals are then refined through self-training our model on its predictions. Our approach improves over state-of-the-art unsupervised 3D instance segmentation methods by more than 300% Average Precision score, demonstrating effective instance segmentation even in challenging, cluttered 3D scenes.
Read more5/1/2024

0
3D Unsupervised Learning by Distilling 2D Open-Vocabulary Segmentation Models for Autonomous Driving
Boyi Sun, Yuhang Liu, Xingxia Wang, Bin Tian, Long Chen, Fei-Yue Wang
Point cloud data labeling is considered a time-consuming and expensive task in autonomous driving, whereas unsupervised learning can avoid it by learning point cloud representations from unannotated data. In this paper, we propose UOV, a novel 3D Unsupervised framework assisted by 2D Open-Vocabulary segmentation models. It consists of two stages: In the first stage, we innovatively integrate high-quality textual and image features of 2D open-vocabulary models and propose the Tri-Modal contrastive Pre-training (TMP). In the second stage, spatial mapping between point clouds and images is utilized to generate pseudo-labels, enabling cross-modal knowledge distillation. Besides, we introduce the Approximate Flat Interaction (AFI) to address the noise during alignment and label confusion. To validate the superiority of UOV, extensive experiments are conducted on multiple related datasets. We achieved a record-breaking 47.73% mIoU on the annotation-free point cloud segmentation task in nuScenes, surpassing the previous best model by 10.70% mIoU. Meanwhile, the performance of fine-tuning with 1% data on nuScenes and SemanticKITTI reached a remarkable 51.75% mIoU and 48.14% mIoU, outperforming all previous pre-trained models.
Read more9/24/2024