Customize-A-Video: One-Shot Motion Customization of Text-to-Video Diffusion Models

0

Sign in to get full access
Overview
- One-shot motion customization of text-to-video diffusion models
- Allows users to customize video outputs by providing a single reference motion clip
- Leverages a text-to-video diffusion model as the base for generating customized video
Plain English Explanation
Text-to-video diffusion models are AI systems that can generate video clips from text prompts. Customize-A-Video builds on these models, giving users the ability to customize the motion of the generated videos using a single reference clip.
The key idea is that users provide a short video clip showing the desired motion, and the system then adapts the text-to-video generation to match that motion. This allows users to control aspects like the movement, pose, and style of the characters or objects in the generated video, beyond what the original text prompt specifies.
By using a one-shot approach - just a single reference clip - the customization process is efficient and convenient for users. The system is able to extract the core motion information from the reference and apply it to the text-driven video generation, creating a final output that combines the user's desired motion with the content suggested by the text prompt.
This capability could be useful for a variety of applications, such as creating personalized animation, generating promotional videos, or customizing video game characters and environments. The one-shot approach makes it accessible for users without extensive video editing skills.
Technical Explanation
Customize-A-Video builds on recent text-to-video diffusion models like EVCG and MotionInversion. It introduces a one-shot motion customization technique that allows users to provide a single reference video clip to customize the motion of the generated output.
The core architecture consists of three main components:
- A text-to-video diffusion model that generates the initial video based on the text prompt.
- A motion encoder that extracts the key motion information from the reference clip.
- A motion adaptation module that blends the motion from the reference into the generated video.
During inference, the user provides both a text prompt and a short reference video clip. The motion encoder first analyzes the reference clip to capture its essential motion characteristics. The text-to-video diffusion model then generates an initial video based on the text prompt. Finally, the motion adaptation module seamlessly integrates the user's desired motion into the generated video.
The authors demonstrate that this one-shot customization approach outperforms methods that require multiple reference clips or extensive fine-tuning. It achieves high-quality customized video outputs while maintaining the flexibility and efficiency of the underlying text-to-video diffusion framework.
Critical Analysis
The Customize-A-Video approach addresses an important limitation of existing text-to-video models - the lack of user control over the motion and dynamics of the generated content. By enabling one-shot motion customization, it empowers users to tailor the video outputs to their specific needs and preferences.
However, the paper does not extensively explore the limits of this customization capability. For example, it's unclear how well the system would handle reference clips with complex or unusual motion patterns, or how much the customization can deviate from the original text-driven content without introducing significant artifacts or inconsistencies.
Additionally, the paper focuses on a single type of motion customization (i.e., blending the reference motion into the generated video). Exploring other customization modalities, such as allowing users to specify the motion of individual elements or characters, could further expand the system's versatility and usefulness.
Finally, the authors mention the potential for real-world applications, but do not provide a detailed discussion of the societal implications or ethical considerations around the use of such customizable video generation tools. As these technologies become more accessible, it will be important to carefully consider their impact and potential misuse.
Conclusion
Customize-A-Video presents an innovative approach to empowering users in the realm of text-to-video generation. By enabling one-shot motion customization, it allows users to tailor the dynamics and movement of generated video outputs to their specific needs and preferences.
This capability could have far-reaching applications in fields such as entertainment, marketing, and education, where customized video content is in high demand. The efficient, one-shot customization process makes the technology accessible to a wide range of users, regardless of their video editing expertise.
As text-to-video generation models continue to advance, the ability to seamlessly integrate user-specified motion and other customization features will be crucial for unlocking the full potential of these systems. The Customize-A-Video approach represents an important step in this direction, paving the way for more personalized and expressive video generation experiences.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Customize-A-Video: One-Shot Motion Customization of Text-to-Video Diffusion Models
Yixuan Ren, Yang Zhou, Jimei Yang, Jing Shi, Difan Liu, Feng Liu, Mingi Kwon, Abhinav Shrivastava
Image customization has been extensively studied in text-to-image (T2I) diffusion models, leading to impressive outcomes and applications. With the emergence of text-to-video (T2V) diffusion models, its temporal counterpart, motion customization, has not yet been well investigated. To address the challenge of one-shot video motion customization, we propose Customize-A-Video that models the motion from a single reference video and adapts it to new subjects and scenes with both spatial and temporal varieties. It leverages low-rank adaptation (LoRA) on temporal attention layers to tailor the pre-trained T2V diffusion model for specific motion modeling. To disentangle the spatial and temporal information during training, we introduce a novel concept of appearance absorbers that detach the original appearance from the reference video prior to motion learning. The proposed modules are trained in a staged pipeline and inferred in a plug-and-play fashion, enabling easy extensions to various downstream tasks such as custom video generation and editing, video appearance customization and multiple motion combination. Our project page can be found at https://customize-a-video.github.io.
Read more8/29/2024

0
Still-Moving: Customized Video Generation without Customized Video Data
Hila Chefer, Shiran Zada, Roni Paiss, Ariel Ephrat, Omer Tov, Michael Rubinstein, Lior Wolf, Tali Dekel, Tomer Michaeli, Inbar Mosseri
Customizing text-to-image (T2I) models has seen tremendous progress recently, particularly in areas such as personalization, stylization, and conditional generation. However, expanding this progress to video generation is still in its infancy, primarily due to the lack of customized video data. In this work, we introduce Still-Moving, a novel generic framework for customizing a text-to-video (T2V) model, without requiring any customized video data. The framework applies to the prominent T2V design where the video model is built over a text-to-image (T2I) model (e.g., via inflation). We assume access to a customized version of the T2I model, trained only on still image data (e.g., using DreamBooth or StyleDrop). Naively plugging in the weights of the customized T2I model into the T2V model often leads to significant artifacts or insufficient adherence to the customization data. To overcome this issue, we train lightweight $textit{Spatial Adapters}$ that adjust the features produced by the injected T2I layers. Importantly, our adapters are trained on $textit{frozen videos}$ (i.e., repeated images), constructed from image samples generated by the customized T2I model. This training is facilitated by a novel $textit{Motion Adapter}$ module, which allows us to train on such static videos while preserving the motion prior of the video model. At test time, we remove the Motion Adapter modules and leave in only the trained Spatial Adapters. This restores the motion prior of the T2V model while adhering to the spatial prior of the customized T2I model. We demonstrate the effectiveness of our approach on diverse tasks including personalized, stylized, and conditional generation. In all evaluated scenarios, our method seamlessly integrates the spatial prior of the customized T2I model with a motion prior supplied by the T2V model.
Read more7/12/2024
📶
0
Control-A-Video: Controllable Text-to-Video Diffusion Models with Motion Prior and Reward Feedback Learning
Weifeng Chen, Yatai Ji, Jie Wu, Hefeng Wu, Pan Xie, Jiashi Li, Xin Xia, Xuefeng Xiao, Liang Lin
Recent advances in text-to-image (T2I) diffusion models have enabled impressive image generation capabilities guided by text prompts. However, extending these techniques to video generation remains challenging, with existing text-to-video (T2V) methods often struggling to produce high-quality and motion-consistent videos. In this work, we introduce Control-A-Video, a controllable T2V diffusion model that can generate videos conditioned on text prompts and reference control maps like edge and depth maps. To tackle video quality and motion consistency issues, we propose novel strategies to incorporate content prior and motion prior into the diffusion-based generation process. Specifically, we employ a first-frame condition scheme to transfer video generation from the image domain. Additionally, we introduce residual-based and optical flow-based noise initialization to infuse motion priors from reference videos, promoting relevance among frame latents for reduced flickering. Furthermore, we present a Spatio-Temporal Reward Feedback Learning (ST-ReFL) algorithm that optimizes the video diffusion model using multiple reward models for video quality and motion consistency, leading to superior outputs. Comprehensive experiments demonstrate that our framework generates higher-quality, more consistent videos compared to existing state-of-the-art methods in controllable text-to-video generation
Read more8/13/2024
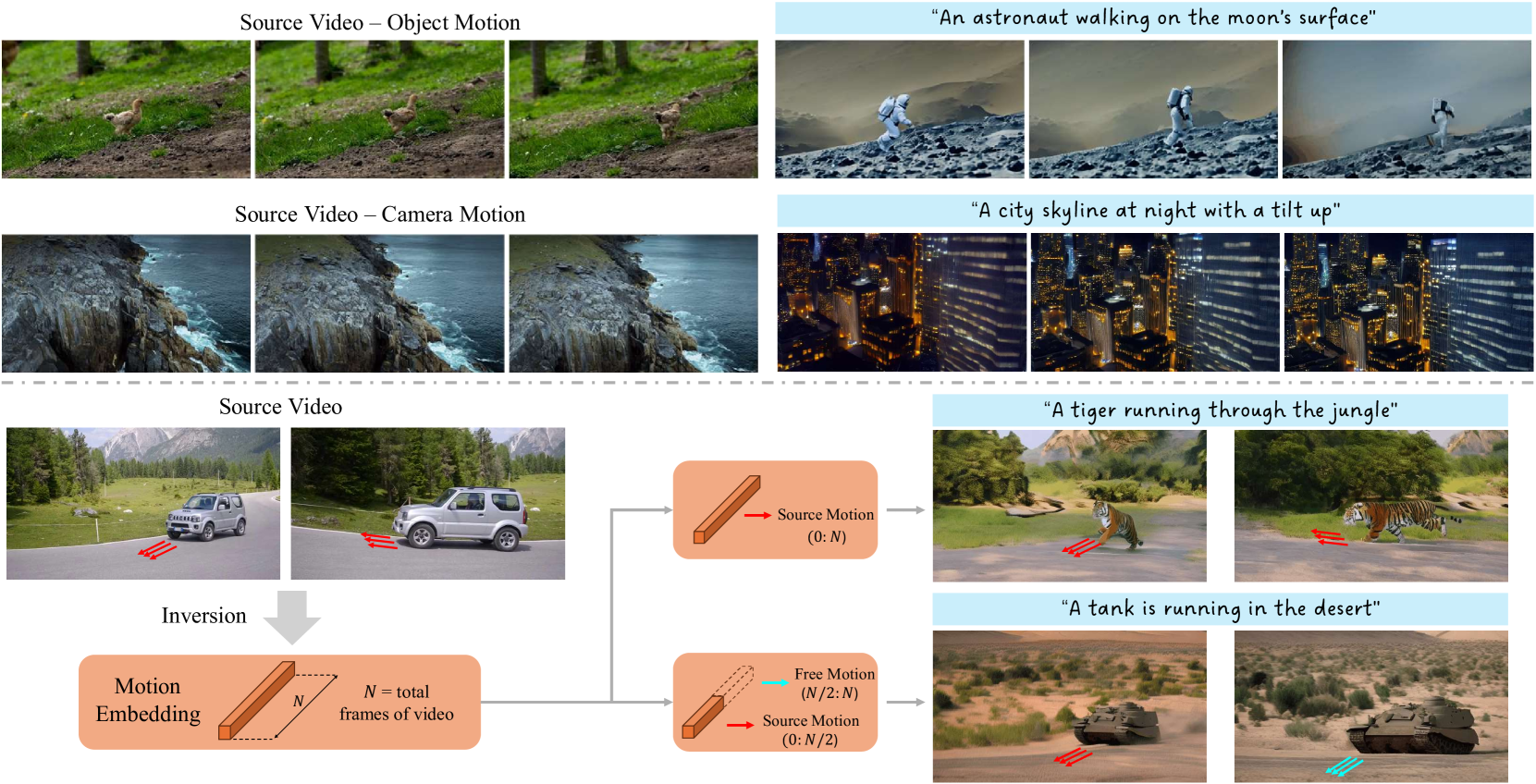
0
Motion Inversion for Video Customization
Luozhou Wang, Guibao Shen, Yixun Liang, Xin Tao, Pengfei Wan, Di Zhang, Yijun Li, Yingcong Chen
In this research, we present a novel approach to motion customization in video generation, addressing the widespread gap in the thorough exploration of motion representation within video generative models. Recognizing the unique challenges posed by video's spatiotemporal nature, our method introduces Motion Embeddings, a set of explicit, temporally coherent one-dimensional embeddings derived from a given video. These embeddings are designed to integrate seamlessly with the temporal transformer modules of video diffusion models, modulating self-attention computations across frames without compromising spatial integrity. Our approach offers a compact and efficient solution to motion representation and enables complex manipulations of motion characteristics through vector arithmetic in the embedding space. Furthermore, we identify the Temporal Discrepancy in video generative models, which refers to variations in how different motion modules process temporal relationships between frames. We leverage this understanding to optimize the integration of our motion embeddings. Our contributions include the introduction of a tailored motion embedding for customization tasks, insights into the temporal processing differences in video models, and a demonstration of the practical advantages and effectiveness of our method through extensive experiments.
Read more4/1/2024