Still-Moving: Customized Video Generation without Customized Video Data

0

Sign in to get full access
Overview
- This paper presents "Still-Moving", a novel method for generating customized videos without the need for customized video data.
- The approach leverages pre-trained text-to-image and image-to-video models to enable generation of personalized animated videos from text prompts.
- The system combines recent advancements in text-to-video synthesis and zero-shot image-to-video generation to create a powerful video generation framework.
Plain English Explanation
The paper introduces a new way to create custom videos without having to collect a lot of specialized video data. Instead, it uses pre-existing text-to-image and image-to-video models to generate personalized animated videos from just a text description.
The key idea is to first use a text-to-image model to generate an image that matches the description. Then, an image-to-video model is used to animate that image, creating a short, customized video clip. This allows users to generate unique videos without needing to provide extensive training data.
The authors show that their "Still-Moving" approach can create high-quality, personalized videos that capture the intent of the original text prompt. This makes video content creation more accessible and flexible for a wide range of applications.
Technical Explanation
The "Still-Moving" framework consists of two main components:
-
Text-to-Image Generation: The system first uses a pre-trained text-to-image model, such as DALL-E or Imagen, to generate an image that matches the input text prompt.
-
Image-to-Video Animation: The generated image is then passed to a pre-trained image-to-video model, such as i2v-Adapter or LateManNet, which animates the image to create a short video clip.
The authors evaluate their approach on a variety of text prompts and show that "Still-Moving" can generate high-quality, customized videos that closely match the semantic content of the input text.
Critical Analysis
The paper presents a compelling approach to video generation that addresses the challenge of acquiring large, diverse video datasets for training. By leveraging pre-trained models, the "Still-Moving" system provides a flexible and scalable solution.
However, the authors acknowledge that the quality and consistency of the generated videos are still limited by the capabilities of the underlying text-to-image and image-to-video models. Improvements in these foundational models will be necessary to further enhance the realism and coherence of the generated video content.
Additionally, the paper does not explore potential biases or limitations in the pre-trained models, which could be inherited by the "Still-Moving" system. Evaluating the ethical implications and addressing potential biases would be an important next step for this line of research.
Conclusion
The "Still-Moving" framework presents a novel approach to video generation that enables the creation of customized video content without the need for large, specialized video datasets. By leveraging advancements in text-to-image and image-to-video synthesis, the system offers a flexible and scalable solution for generating personalized video content.
While the current limitations of the underlying models present challenges, the paper demonstrates the potential of this approach to make video creation more accessible and inclusive. As the field of generative AI continues to evolve, techniques like "Still-Moving" may become increasingly important for democratizing media production and expanding creative possibilities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Still-Moving: Customized Video Generation without Customized Video Data
Hila Chefer, Shiran Zada, Roni Paiss, Ariel Ephrat, Omer Tov, Michael Rubinstein, Lior Wolf, Tali Dekel, Tomer Michaeli, Inbar Mosseri
Customizing text-to-image (T2I) models has seen tremendous progress recently, particularly in areas such as personalization, stylization, and conditional generation. However, expanding this progress to video generation is still in its infancy, primarily due to the lack of customized video data. In this work, we introduce Still-Moving, a novel generic framework for customizing a text-to-video (T2V) model, without requiring any customized video data. The framework applies to the prominent T2V design where the video model is built over a text-to-image (T2I) model (e.g., via inflation). We assume access to a customized version of the T2I model, trained only on still image data (e.g., using DreamBooth or StyleDrop). Naively plugging in the weights of the customized T2I model into the T2V model often leads to significant artifacts or insufficient adherence to the customization data. To overcome this issue, we train lightweight $textit{Spatial Adapters}$ that adjust the features produced by the injected T2I layers. Importantly, our adapters are trained on $textit{frozen videos}$ (i.e., repeated images), constructed from image samples generated by the customized T2I model. This training is facilitated by a novel $textit{Motion Adapter}$ module, which allows us to train on such static videos while preserving the motion prior of the video model. At test time, we remove the Motion Adapter modules and leave in only the trained Spatial Adapters. This restores the motion prior of the T2V model while adhering to the spatial prior of the customized T2I model. We demonstrate the effectiveness of our approach on diverse tasks including personalized, stylized, and conditional generation. In all evaluated scenarios, our method seamlessly integrates the spatial prior of the customized T2I model with a motion prior supplied by the T2V model.
Read more7/12/2024

0
Customize-A-Video: One-Shot Motion Customization of Text-to-Video Diffusion Models
Yixuan Ren, Yang Zhou, Jimei Yang, Jing Shi, Difan Liu, Feng Liu, Mingi Kwon, Abhinav Shrivastava
Image customization has been extensively studied in text-to-image (T2I) diffusion models, leading to impressive outcomes and applications. With the emergence of text-to-video (T2V) diffusion models, its temporal counterpart, motion customization, has not yet been well investigated. To address the challenge of one-shot video motion customization, we propose Customize-A-Video that models the motion from a single reference video and adapts it to new subjects and scenes with both spatial and temporal varieties. It leverages low-rank adaptation (LoRA) on temporal attention layers to tailor the pre-trained T2V diffusion model for specific motion modeling. To disentangle the spatial and temporal information during training, we introduce a novel concept of appearance absorbers that detach the original appearance from the reference video prior to motion learning. The proposed modules are trained in a staged pipeline and inferred in a plug-and-play fashion, enabling easy extensions to various downstream tasks such as custom video generation and editing, video appearance customization and multiple motion combination. Our project page can be found at https://customize-a-video.github.io.
Read more8/29/2024
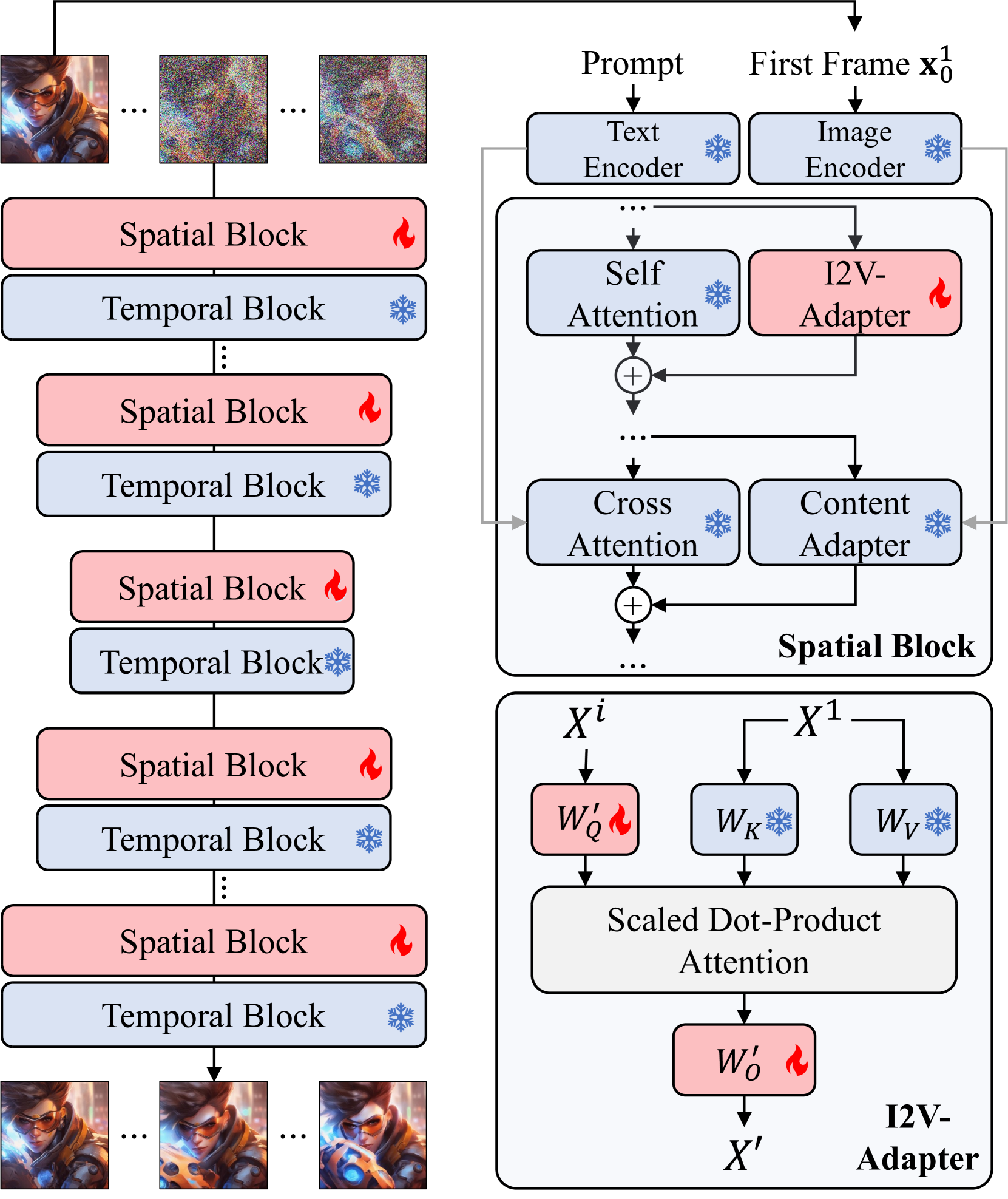
0
I2V-Adapter: A General Image-to-Video Adapter for Diffusion Models
Xun Guo, Mingwu Zheng, Liang Hou, Yuan Gao, Yufan Deng, Pengfei Wan, Di Zhang, Yufan Liu, Weiming Hu, Zhengjun Zha, Haibin Huang, Chongyang Ma
Text-guided image-to-video (I2V) generation aims to generate a coherent video that preserves the identity of the input image and semantically aligns with the input prompt. Existing methods typically augment pretrained text-to-video (T2V) models by either concatenating the image with noised video frames channel-wise before being fed into the model or injecting the image embedding produced by pretrained image encoders in cross-attention modules. However, the former approach often necessitates altering the fundamental weights of pretrained T2V models, thus restricting the model's compatibility within the open-source communities and disrupting the model's prior knowledge. Meanwhile, the latter typically fails to preserve the identity of the input image. We present I2V-Adapter to overcome such limitations. I2V-Adapter adeptly propagates the unnoised input image to subsequent noised frames through a cross-frame attention mechanism, maintaining the identity of the input image without any changes to the pretrained T2V model. Notably, I2V-Adapter only introduces a few trainable parameters, significantly alleviating the training cost and also ensures compatibility with existing community-driven personalized models and control tools. Moreover, we propose a novel Frame Similarity Prior to balance the motion amplitude and the stability of generated videos through two adjustable control coefficients. Our experimental results demonstrate that I2V-Adapter is capable of producing high-quality videos. This performance, coupled with its agility and adaptability, represents a substantial advancement in the field of I2V, particularly for personalized and controllable applications.
Read more6/28/2024

0
FancyVideo: Towards Dynamic and Consistent Video Generation via Cross-frame Textual Guidance
Jiasong Feng, Ao Ma, Jing Wang, Bo Cheng, Xiaodan Liang, Dawei Leng, Yuhui Yin
Synthesizing motion-rich and temporally consistent videos remains a challenge in artificial intelligence, especially when dealing with extended durations. Existing text-to-video (T2V) models commonly employ spatial cross-attention for text control, equivalently guiding different frame generations without frame-specific textual guidance. Thus, the model's capacity to comprehend the temporal logic conveyed in prompts and generate videos with coherent motion is restricted. To tackle this limitation, we introduce FancyVideo, an innovative video generator that improves the existing text-control mechanism with the well-designed Cross-frame Textual Guidance Module (CTGM). Specifically, CTGM incorporates the Temporal Information Injector (TII), Temporal Affinity Refiner (TAR), and Temporal Feature Booster (TFB) at the beginning, middle, and end of cross-attention, respectively, to achieve frame-specific textual guidance. Firstly, TII injects frame-specific information from latent features into text conditions, thereby obtaining cross-frame textual conditions. Then, TAR refines the correlation matrix between cross-frame textual conditions and latent features along the time dimension. Lastly, TFB boosts the temporal consistency of latent features. Extensive experiments comprising both quantitative and qualitative evaluations demonstrate the effectiveness of FancyVideo. Our video demo, code and model are available at https://360cvgroup.github.io/FancyVideo/.
Read more8/19/2024