Customizing Text-to-Image Diffusion with Camera Viewpoint Control
2404.12333
0
1
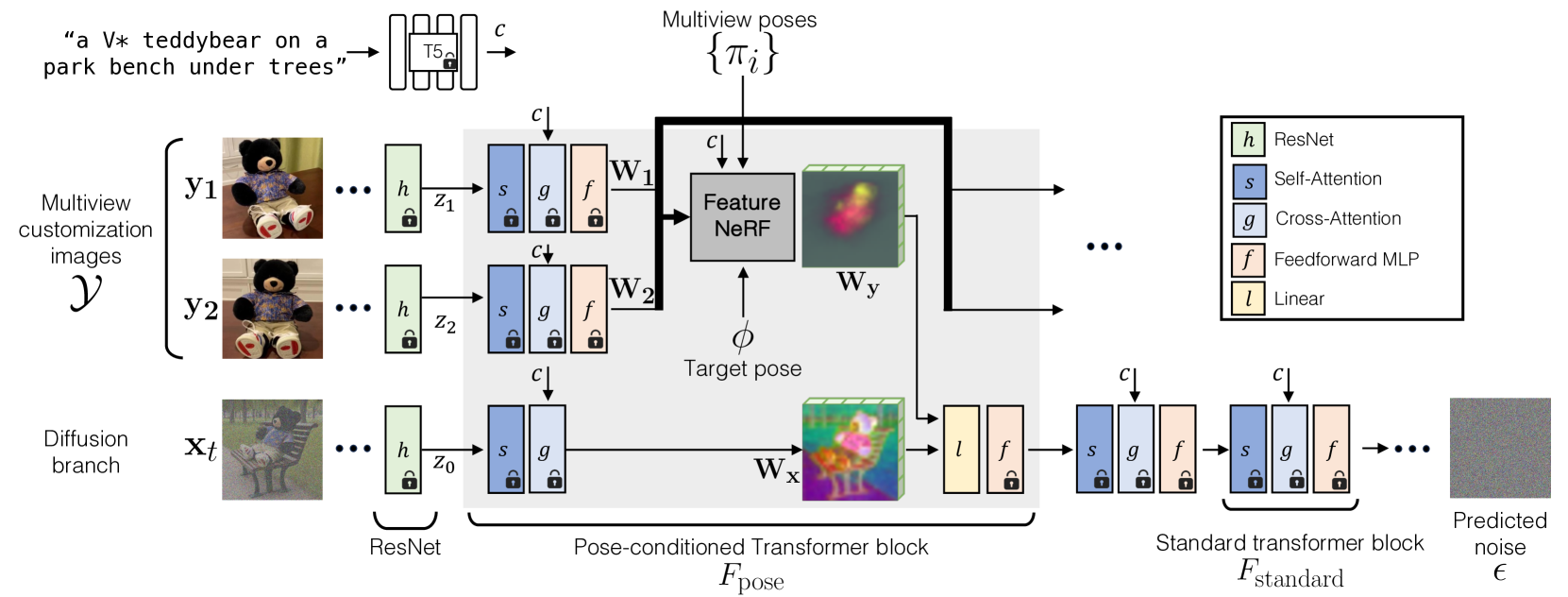
Abstract
Model customization introduces new concepts to existing text-to-image models, enabling the generation of the new concept in novel contexts. However, such methods lack accurate camera view control w.r.t the object, and users must resort to prompt engineering (e.g., adding top-view) to achieve coarse view control. In this work, we introduce a new task -- enabling explicit control of camera viewpoint for model customization. This allows us to modify object properties amongst various background scenes via text prompts, all while incorporating the target camera pose as additional control. This new task presents significant challenges in merging a 3D representation from the multi-view images of the new concept with a general, 2D text-to-image model. To bridge this gap, we propose to condition the 2D diffusion process on rendered, view-dependent features of the new object. During training, we jointly adapt the 2D diffusion modules and 3D feature predictions to reconstruct the object's appearance and geometry while reducing overfitting to the input multi-view images. Our method outperforms existing image editing and model personalization baselines in preserving the custom object's identity while following the input text prompt and the object's camera pose.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper explores a method for customizing text-to-image diffusion models to enable camera viewpoint control.
- The proposed approach allows users to specify the desired viewpoint or camera angle when generating images from text prompts.
- The method leverages camera-specific text embeddings and a viewpoint-aware diffusion model to generate images that match the specified viewpoint.
Plain English Explanation
Text-to-image diffusion models have become increasingly powerful, allowing users to generate photorealistic images from simple text descriptions. However, these models typically generate images from a neutral, static viewpoint. Customizing Text-to-Image Diffusion with Camera Viewpoint Control introduces a novel technique to give users more control over the camera angle or viewpoint of the generated images.
The key idea is to train the diffusion model to understand not just the textual content, but also the desired camera viewpoint. This is achieved by incorporating camera-specific text embeddings into the diffusion process. The model learns to associate certain textual cues with specific camera angles, allowing users to specify the desired viewpoint when generating images.
For example, a user could prompt the model to "generate a scenic landscape from a bird's eye view" or "create a close-up shot of a person's face." The model would then generate an image that matches the requested viewpoint, rather than a generic, neutral perspective.
This approach builds on prior work that has explored camera control in text-to-video models, and extends similar ideas to the text-to-image domain. By giving users more control over the camera viewpoint, this method can enable the creation of more diverse, personalized, and visually compelling images.
Technical Explanation
Customizing Text-to-Image Diffusion with Camera Viewpoint Control presents a novel approach for incorporating camera viewpoint control into text-to-image diffusion models. The key technical components of the proposed method are:
-
Camera-Specific Text Embeddings: The researchers train a language model to generate camera-specific text embeddings, which capture the unique linguistic patterns associated with different camera angles (e.g., "bird's eye view," "close-up"). These embeddings are then used as additional input to the diffusion model.
-
Viewpoint-Aware Diffusion Model: The diffusion model is trained to generate images that match the specified camera viewpoint, by conditioning the diffusion process on both the text prompt and the camera-specific text embeddings. This allows the model to learn the relationship between textual cues and desired camera angles.
-
Viewpoint Control Mechanism: During inference, users can specify the desired camera viewpoint by providing a text prompt that includes relevant keywords (e.g., "from above," "close-up"). The model then uses the camera-specific text embeddings to generate an image that matches the requested viewpoint.
The researchers evaluate their method on various text-to-image benchmarks, demonstrating that it can generate images with high fidelity while allowing for effective camera viewpoint control. This builds on previous work on view selection for 3D captioning and generating images with 3D annotations, further enhancing the 3D fidelity of text-to-3D generation.
Critical Analysis
The paper presents a compelling approach for enabling camera viewpoint control in text-to-image diffusion models, which is a valuable addition to the field. The authors have thoughtfully designed the technical components and demonstrated the effectiveness of their method on standard benchmarks.
One potential limitation is the reliance on camera-specific text embeddings, which may require a significant amount of data and preprocessing to train effectively. The authors acknowledge that the quality and breadth of the camera-specific language model could be a key factor in the performance of their approach.
Additionally, while the paper showcases impressive results in terms of viewpoint control and image fidelity, it would be interesting to see further exploration of the model's ability to handle more complex or unconventional camera angles, such as extreme close-ups, unusual perspectives, or dynamic camera movements.
Moreover, the paper does not delve into potential social or ethical implications of this technology, such as the potential for misuse or unintended consequences. As text-to-image models become more powerful and expressive, it is essential to consider these broader implications and how the research community can proactively address them.
Conclusion
Customizing Text-to-Image Diffusion with Camera Viewpoint Control presents a novel approach that extends the capabilities of text-to-image diffusion models by enabling users to specify the desired camera viewpoint. This work represents an important step forward in enhancing the expressiveness and personalization of generative AI systems, potentially leading to more diverse and visually compelling image creation.
The researchers' technical insights, such as the incorporation of camera-specific text embeddings and the viewpoint-aware diffusion model, demonstrate the potential for further advancements in this area. As this technology continues to evolve, it will be crucial to consider the broader implications and ensure that it is developed and deployed in a responsible and ethical manner.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

DreamView: Injecting View-specific Text Guidance into Text-to-3D Generation
Junkai Yan, Yipeng Gao, Qize Yang, Xihan Wei, Xuansong Xie, Ancong Wu, Wei-Shi Zheng
0
0
Text-to-3D generation, which synthesizes 3D assets according to an overall text description, has significantly progressed. However, a challenge arises when the specific appearances need customizing at designated viewpoints but referring solely to the overall description for generating 3D objects. For instance, ambiguity easily occurs when producing a T-shirt with distinct patterns on its front and back using a single overall text guidance. In this work, we propose DreamView, a text-to-image approach enabling multi-view customization while maintaining overall consistency by adaptively injecting the view-specific and overall text guidance through a collaborative text guidance injection module, which can also be lifted to 3D generation via score distillation sampling. DreamView is trained with large-scale rendered multi-view images and their corresponding view-specific texts to learn to balance the separate content manipulation in each view and the global consistency of the overall object, resulting in a dual achievement of customization and consistency. Consequently, DreamView empowers artists to design 3D objects creatively, fostering the creation of more innovative and diverse 3D assets. Code and model will be released at https://github.com/iSEE-Laboratory/DreamView.
4/10/2024
🖼️
Integrating View Conditions for Image Synthesis
Jinbin Bai, Zhen Dong, Aosong Feng, Xiao Zhang, Tian Ye, Kaicheng Zhou
0
0
In the field of image processing, applying intricate semantic modifications within existing images remains an enduring challenge. This paper introduces a pioneering framework that integrates viewpoint information to enhance the control of image editing tasks, especially for interior design scenes. By surveying existing object editing methodologies, we distill three essential criteria -- consistency, controllability, and harmony -- that should be met for an image editing method. In contrast to previous approaches, our framework takes the lead in satisfying all three requirements for addressing the challenge of image synthesis. Through comprehensive experiments, encompassing both quantitative assessments and qualitative comparisons with contemporary state-of-the-art methods, we present compelling evidence of our framework's superior performance across multiple dimensions. This work establishes a promising avenue for advancing image synthesis techniques and empowering precise object modifications while preserving the visual coherence of the entire composition.
5/9/2024
💬
Pre-trained Text-to-Image Diffusion Models Are Versatile Representation Learners for Control
Gunshi Gupta, Karmesh Yadav, Yarin Gal, Dhruv Batra, Zsolt Kira, Cong Lu, Tim G. J. Rudner
0
0
Embodied AI agents require a fine-grained understanding of the physical world mediated through visual and language inputs. Such capabilities are difficult to learn solely from task-specific data. This has led to the emergence of pre-trained vision-language models as a tool for transferring representations learned from internet-scale data to downstream tasks and new domains. However, commonly used contrastively trained representations such as in CLIP have been shown to fail at enabling embodied agents to gain a sufficiently fine-grained scene understanding -- a capability vital for control. To address this shortcoming, we consider representations from pre-trained text-to-image diffusion models, which are explicitly optimized to generate images from text prompts and as such, contain text-conditioned representations that reflect highly fine-grained visuo-spatial information. Using pre-trained text-to-image diffusion models, we construct Stable Control Representations which allow learning downstream control policies that generalize to complex, open-ended environments. We show that policies learned using Stable Control Representations are competitive with state-of-the-art representation learning approaches across a broad range of simulated control settings, encompassing challenging manipulation and navigation tasks. Most notably, we show that Stable Control Representations enable learning policies that exhibit state-of-the-art performance on OVMM, a difficult open-vocabulary navigation benchmark.
5/10/2024

CameraCtrl: Enabling Camera Control for Text-to-Video Generation
Hao He, Yinghao Xu, Yuwei Guo, Gordon Wetzstein, Bo Dai, Hongsheng Li, Ceyuan Yang
0
0
Controllability plays a crucial role in video generation since it allows users to create desired content. However, existing models largely overlooked the precise control of camera pose that serves as a cinematic language to express deeper narrative nuances. To alleviate this issue, we introduce CameraCtrl, enabling accurate camera pose control for text-to-video(T2V) models. After precisely parameterizing the camera trajectory, a plug-and-play camera module is then trained on a T2V model, leaving others untouched. Additionally, a comprehensive study on the effect of various datasets is also conducted, suggesting that videos with diverse camera distribution and similar appearances indeed enhance controllability and generalization. Experimental results demonstrate the effectiveness of CameraCtrl in achieving precise and domain-adaptive camera control, marking a step forward in the pursuit of dynamic and customized video storytelling from textual and camera pose inputs. Our project website is at: https://hehao13.github.io/projects-CameraCtrl/.
4/3/2024