CycleSAM: One-Shot Surgical Scene Segmentation using Cycle-Consistent Feature Matching to Prompt SAM

0

Sign in to get full access
Overview
- This paper presents CycleSAM, a one-shot surgical scene segmentation method that uses cycle-consistent feature matching to prompt the Segment Anything Model (SAM).
- CycleSAM aims to address the challenge of performing accurate surgical scene segmentation with limited training data by leveraging pre-trained computer vision models.
- The approach involves aligning features between a reference image and the target surgical scene, and then using this alignment to guide the SAM model to segment the target image.
Plain English Explanation
CycleSAM is a new technique for automatically identifying and separating different elements within surgical images, such as instruments, tissues, and anatomical structures. It's designed to work well even when only a single example image is available, which is often the case in medical imaging tasks.
The key idea behind CycleSAM is to take advantage of a powerful pre-trained model called Segment Anything Model (SAM) that can segment images into different components. However, SAM is a general-purpose model and may not work perfectly for specialized medical images right out of the box.
To improve its performance, CycleSAM first aligns the features in a reference surgical image to those in the target image that needs to be segmented. This "cycle-consistent feature matching" ensures that the same visual elements in the two images are properly matched up. The aligned features are then used to guide and prompt the SAM model to segment the target image more accurately.
This approach allows CycleSAM to perform one-shot surgical scene segmentation - it can segment a new surgical image using just a single reference example, without needing to retrain the entire SAM model from scratch. This makes it a practical and efficient solution for medical imaging tasks with limited training data available.
Technical Explanation
CycleSAM builds on previous work such as SAM, SimSAM, ProtoSAM, and Pathological Primitive Segmentation to enable one-shot surgical scene segmentation.
The key components of CycleSAM are:
-
Feature Extraction: CycleSAM uses a pre-trained feature extraction network to encode the reference surgical image and the target image into feature representations.
-
Cycle-Consistent Feature Matching: CycleSAM aligns the features between the reference and target images using a cycle-consistency loss, which ensures that the feature correspondence is bidirectional and reliable.
-
SAM Prompting: The aligned features from the previous step are used to prompt the pre-trained SAM model to segment the target surgical image. The prompts guide SAM to focus on the relevant regions and structures.
The authors evaluate CycleSAM on surgical scene segmentation tasks and show that it outperforms previous one-shot and few-shot learning approaches, while also achieving performance comparable to fully supervised methods that require much more training data.
Critical Analysis
The paper presents a novel and promising approach for one-shot surgical scene segmentation. The use of cycle-consistent feature matching to guide a pre-trained segmentation model is an interesting and potentially powerful idea. However, the authors do not discuss the limitations or potential downsides of this approach in depth.
For example, the reliance on a pre-trained feature extraction network and SAM model means that CycleSAM may not generalize well to surgical scenes or modalities that differ significantly from the data used to train those underlying models. Additionally, the computational complexity of the feature alignment step could be a practical concern, especially for real-time applications.
The authors also do not address potential biases or issues with the underlying datasets used to evaluate CycleSAM. Medical imaging datasets can often suffer from demographic biases, which could impact the fairness and robustness of the segmentation results.
Further research is needed to better understand the strengths, weaknesses, and appropriate use cases of the CycleSAM approach. Comparisons to other one-shot or few-shot learning techniques beyond the ones mentioned, as well as analyses of the model's generalization capabilities, would help provide a more comprehensive assessment of the method.
Conclusion
In summary, the CycleSAM paper presents an innovative approach for performing one-shot surgical scene segmentation by leveraging cycle-consistent feature matching to guide a pre-trained Segment Anything Model. This technique aims to address the challenge of limited training data in medical imaging tasks and shows promising results compared to previous one-shot and few-shot learning methods.
While the paper introduces an interesting and potentially useful idea, further research is needed to fully understand the strengths, limitations, and appropriate use cases of the CycleSAM approach. Addressing issues of model generalization, computational efficiency, and dataset biases could help strengthen the practical applicability of this technique in real-world medical imaging scenarios.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
CycleSAM: One-Shot Surgical Scene Segmentation using Cycle-Consistent Feature Matching to Prompt SAM
Aditya Murali, Pietro Mascagni, Didier Mutter, Nicolas Padoy
The recently introduced Segment-Anything Model (SAM) has the potential to greatly accelerate the development of segmentation models. However, directly applying SAM to surgical images has key limitations including (1) the requirement of image-specific prompts at test-time, thereby preventing fully automated segmentation, and (2) ineffectiveness due to substantial domain gap between natural and surgical images. In this work, we propose CycleSAM, an approach for one-shot surgical scene segmentation that uses the training image-mask pair at test-time to automatically identify points in the test images that correspond to each object class, which can then be used to prompt SAM to produce object masks. To produce high-fidelity matches, we introduce a novel spatial cycle-consistency constraint that enforces point proposals in the test image to rematch to points within the object foreground region in the training image. Then, to address the domain gap, rather than directly using the visual features from SAM, we employ a ResNet50 encoder pretrained on surgical images in a self-supervised fashion, thereby maintaining high label-efficiency. We evaluate CycleSAM for one-shot segmentation on two diverse surgical semantic segmentation datasets, comprehensively outperforming baseline approaches and reaching up to 50% of fully-supervised performance.
Read more7/10/2024

0
CC-SAM: SAM with Cross-feature Attention and Context for Ultrasound Image Segmentation
Shreyank N Gowda, David A. Clifton
The Segment Anything Model (SAM) has achieved remarkable successes in the realm of natural image segmentation, but its deployment in the medical imaging sphere has encountered challenges. Specifically, the model struggles with medical images that feature low contrast, faint boundaries, intricate morphologies, and small-sized objects. To address these challenges and enhance SAM's performance in the medical domain, we introduce a comprehensive modification. Firstly, we incorporate a frozen Convolutional Neural Network (CNN) branch as an image encoder, which synergizes with SAM's original Vision Transformer (ViT) encoder through a novel variational attention fusion module. This integration bolsters the model's capability to capture local spatial information, which is often paramount in medical imagery. Moreover, to further optimize SAM for medical imaging, we introduce feature and position adapters within the ViT branch, refining the encoder's representations. We see that compared to current prompting strategies to fine-tune SAM for ultrasound medical segmentation, the use of text descriptions that serve as text prompts for SAM helps significantly improve the performance. Leveraging ChatGPT's natural language understanding capabilities, we generate prompts that offer contextual information and guidance to SAM, enabling it to better understand the nuances of ultrasound medical images and improve its segmentation accuracy. Our method, in its entirety, represents a significant stride towards making universal image segmentation models more adaptable and efficient in the medical domain.
Read more8/2/2024
0
SimSAM: Zero-shot Medical Image Segmentation via Simulated Interaction
Benjamin Towle, Xin Chen, Ke Zhou
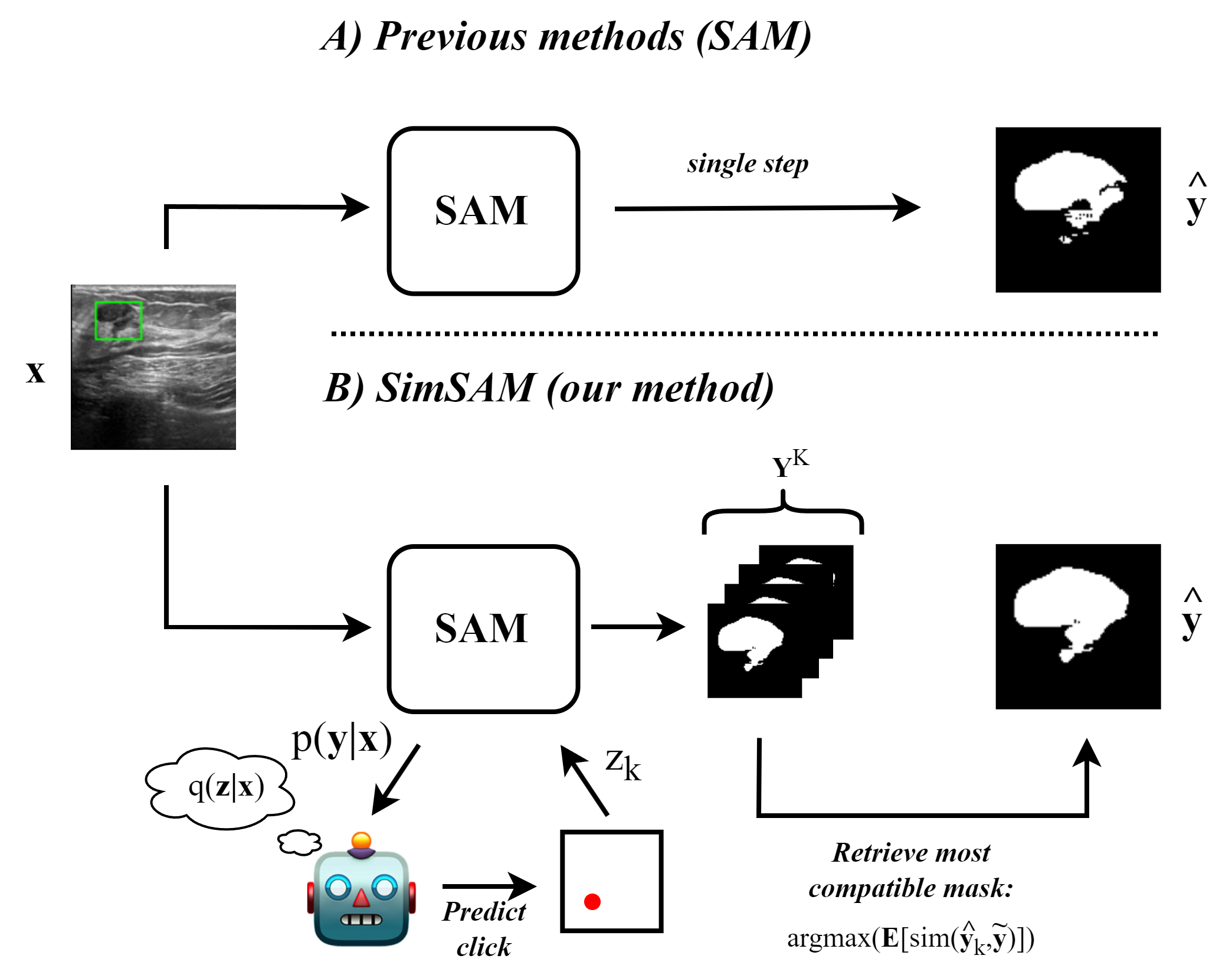
The recently released Segment Anything Model (SAM) has shown powerful zero-shot segmentation capabilities through a semi-automatic annotation setup in which the user can provide a prompt in the form of clicks or bounding boxes. There is growing interest around applying this to medical imaging, where the cost of obtaining expert annotations is high, privacy restrictions may limit sharing of patient data, and model generalisation is often poor. However, there are large amounts of inherent uncertainty in medical images, due to unclear object boundaries, low-contrast media, and differences in expert labelling style. Currently, SAM is known to struggle in a zero-shot setting to adequately annotate the contours of the structure of interest in medical images, where the uncertainty is often greatest, thus requiring significant manual correction. To mitigate this, we introduce textbf{Sim}ulated Interaction for textbf{S}egment textbf{A}nything textbf{M}odel (textsc{textbf{SimSAM}}), an approach that leverages simulated user interaction to generate an arbitrary number of candidate masks, and uses a novel aggregation approach to output the most compatible mask. Crucially, our method can be used during inference directly on top of SAM, without any additional training requirement. Quantitatively, we evaluate our method across three publicly available medical imaging datasets, and find that our approach leads to up to a 15.5% improvement in contour segmentation accuracy compared to zero-shot SAM. Our code is available at url{https://github.com/BenjaminTowle/SimSAM}.
Read more6/4/2024
0
SAM Fewshot Finetuning for Anatomical Segmentation in Medical Images
Weiyi Xie, Nathalie Willems, Shubham Patil, Yang Li, Mayank Kumar
We propose a straightforward yet highly effective few-shot fine-tuning strategy for adapting the Segment Anything (SAM) to anatomical segmentation tasks in medical images. Our novel approach revolves around reformulating the mask decoder within SAM, leveraging few-shot embeddings derived from a limited set of labeled images (few-shot collection) as prompts for querying anatomical objects captured in image embeddings. This innovative reformulation greatly reduces the need for time-consuming online user interactions for labeling volumetric images, such as exhaustively marking points and bounding boxes to provide prompts slice by slice. With our method, users can manually segment a few 2D slices offline, and the embeddings of these annotated image regions serve as effective prompts for online segmentation tasks. Our method prioritizes the efficiency of the fine-tuning process by exclusively training the mask decoder through caching mechanisms while keeping the image encoder frozen. Importantly, this approach is not limited to volumetric medical images, but can generically be applied to any 2D/3D segmentation task. To thoroughly evaluate our method, we conducted extensive validation on four datasets, covering six anatomical segmentation tasks across two modalities. Furthermore, we conducted a comparative analysis of different prompting options within SAM and the fully-supervised nnU-Net. The results demonstrate the superior performance of our method compared to SAM employing only point prompts (approximately 50% improvement in IoU) and performs on-par with fully supervised methods whilst reducing the requirement of labeled data by at least an order of magnitude.
Read more7/8/2024