DANCE: Dual-View Distribution Alignment for Dataset Condensation

0

Sign in to get full access
Overview
- This paper presents a novel method called DANCE (Dual-view Distribution Alignment for dataset Condensation) for condensing large datasets into smaller, more efficient datasets.
- The key idea is to align the distributions of the original and condensed datasets in two different views, which helps preserve the important information in the original data.
- DANCE outperforms previous dataset condensation methods on several benchmark tasks, demonstrating its effectiveness at creating high-quality compressed datasets.
Plain English Explanation
DANCE: Dual-View Distribution Alignment for Dataset Condensation is a new technique for taking a large dataset and creating a much smaller version of it that still captures the key information. This can be useful when you have a very large dataset that is slow or expensive to work with, and you want to distill it down to the most essential elements.
The core insight behind DANCE is that you can preserve the important characteristics of the original data by aligning the distributions, or statistical properties, of the original and condensed datasets in two different "views" or perspectives. This helps ensure the condensed dataset retains the essential patterns and relationships present in the full dataset.
Compared to previous methods for dataset condensation or dataset distillation, DANCE is able to create smaller datasets that still perform very well on the same machine learning tasks as the original, much larger dataset. This makes it a powerful tool for speeding up machine learning workflows and enabling more efficient model training.
Technical Explanation
DANCE: Dual-View Distribution Alignment for Dataset Condensation introduces a new dataset condensation method that aligns the distributions of the original and condensed datasets in two complementary views.
The first view is the standard data distribution, capturing the overall statistics and relationships in the data. The second view is the representation distribution, which looks at the internal feature representations learned by a neural network trained on the data.
By matching both the data and representation distributions between the original and condensed datasets, DANCE is able to preserve the essential information and structure of the full dataset in the smaller, compressed version. This is achieved through a carefully designed optimization objective and training procedure.
The authors evaluate DANCE on several standard computer vision benchmarks, including CIFAR-10, CIFAR-100, and ImageNet. Compared to prior dataset condensation and dataset distillation methods, DANCE is able to produce condensed datasets that lead to higher accuracy when used to train machine learning models.
Critical Analysis
The DANCE paper provides a well-designed and thorough evaluation of its dataset condensation approach. The authors clearly articulate the motivations and intuitions behind the method, and the technical details are explained with sufficient rigor.
That said, the paper does not address some potential limitations or edge cases of the DANCE algorithm. For example, it is unclear how DANCE would perform on highly heterogeneous datasets, or whether the method is robust to dataset shift or distribution mismatch between the original and target domains.
Additionally, the computational complexity and training time of DANCE is not compared to alternative condensation techniques, which could be an important practical consideration in some applications.
Overall, DANCE represents a valuable contribution to the growing body of work on dataset condensation and dataset distillation. Further research exploring the method's limitations and ways to improve its efficiency would be a promising direction for future work.
Conclusion
DANCE: Dual-View Distribution Alignment for Dataset Condensation introduces a novel dataset condensation technique that aligns the distributions of the original and condensed datasets in two complementary views. By preserving both the data and representation distributions, DANCE is able to create smaller datasets that still perform well on machine learning tasks.
This work represents an important advance in the field of dataset condensation, with the potential to significantly speed up model training and enable more efficient use of large-scale datasets. As machine learning models continue to grow in size and complexity, techniques like DANCE will become increasingly valuable for managing the computational demands of modern AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
DANCE: Dual-View Distribution Alignment for Dataset Condensation
Hansong Zhang, Shikun Li, Fanzhao Lin, Weiping Wang, Zhenxing Qian, Shiming Ge
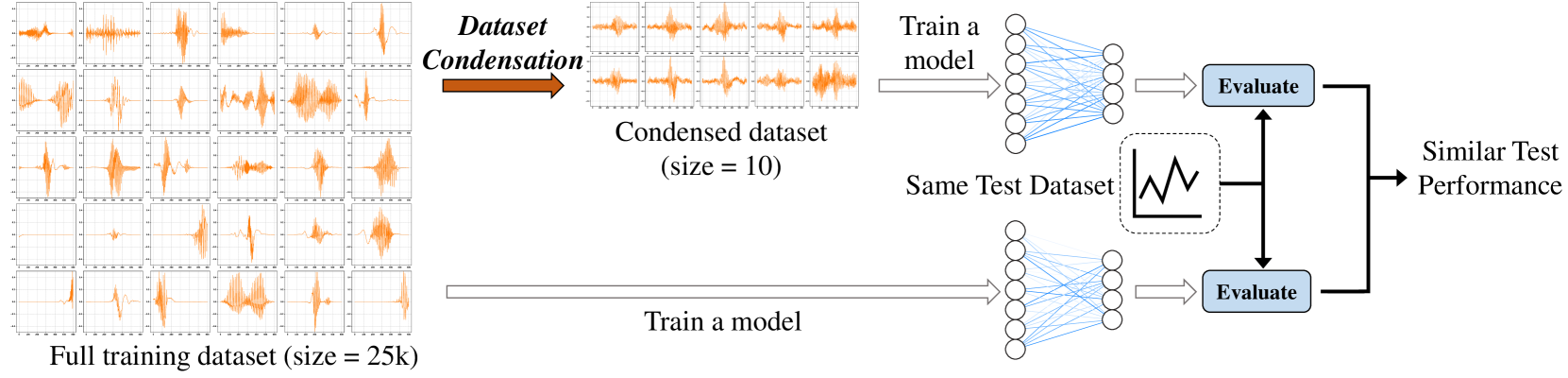
Dataset condensation addresses the problem of data burden by learning a small synthetic training set that preserves essential knowledge from the larger real training set. To date, the state-of-the-art (SOTA) results are often yielded by optimization-oriented methods, but their inefficiency hinders their application to realistic datasets. On the other hand, the Distribution-Matching (DM) methods show remarkable efficiency but sub-optimal results compared to optimization-oriented methods. In this paper, we reveal the limitations of current DM-based methods from the inner-class and inter-class views, i.e., Persistent Training and Distribution Shift. To address these problems, we propose a new DM-based method named Dual-view distribution AligNment for dataset CondEnsation (DANCE), which exploits a few pre-trained models to improve DM from both inner-class and inter-class views. Specifically, from the inner-class view, we construct multiple middle encoders to perform pseudo long-term distribution alignment, making the condensed set a good proxy of the real one during the whole training process; while from the inter-class view, we use the expert models to perform distribution calibration, ensuring the synthetic data remains in the real class region during condensing. Experiments demonstrate the proposed method achieves a SOTA performance while maintaining comparable efficiency with the original DM across various scenarios. Source codes are available at https://github.com/Hansong-Zhang/DANCE.
Read more6/4/2024
0
Dataset Condensation for Time Series Classification via Dual Domain Matching
Zhanyu Liu, Ke Hao, Guanjie Zheng, Yanwei Yu
Time series data has been demonstrated to be crucial in various research fields. The management of large quantities of time series data presents challenges in terms of deep learning tasks, particularly for training a deep neural network. Recently, a technique named textit{Dataset Condensation} has emerged as a solution to this problem. This technique generates a smaller synthetic dataset that has comparable performance to the full real dataset in downstream tasks such as classification. However, previous methods are primarily designed for image and graph datasets, and directly adapting them to the time series dataset leads to suboptimal performance due to their inability to effectively leverage the rich information inherent in time series data, particularly in the frequency domain. In this paper, we propose a novel framework named Dataset textit{textbf{Cond}}ensation for textit{textbf{T}}ime textit{textbf{S}}eries textit{textbf{C}}lassification via Dual Domain Matching (textbf{CondTSC}) which focuses on the time series classification dataset condensation task. Different from previous methods, our proposed framework aims to generate a condensed dataset that matches the surrogate objectives in both the time and frequency domains. Specifically, CondTSC incorporates multi-view data augmentation, dual domain training, and dual surrogate objectives to enhance the dataset condensation process in the time and frequency domains. Through extensive experiments, we demonstrate the effectiveness of our proposed framework, which outperforms other baselines and learns a condensed synthetic dataset that exhibits desirable characteristics such as conforming to the distribution of the original data.
Read more6/11/2024

0
Elucidating the Design Space of Dataset Condensation
Shitong Shao, Zikai Zhou, Huanran Chen, Zhiqiang Shen
Dataset condensation, a concept within data-centric learning, efficiently transfers critical attributes from an original dataset to a synthetic version, maintaining both diversity and realism. This approach significantly improves model training efficiency and is adaptable across multiple application areas. Previous methods in dataset condensation have faced challenges: some incur high computational costs which limit scalability to larger datasets (e.g., MTT, DREAM, and TESLA), while others are restricted to less optimal design spaces, which could hinder potential improvements, especially in smaller datasets (e.g., SRe2L, G-VBSM, and RDED). To address these limitations, we propose a comprehensive design framework that includes specific, effective strategies like implementing soft category-aware matching and adjusting the learning rate schedule. These strategies are grounded in empirical evidence and theoretical backing. Our resulting approach, Elucidate Dataset Condensation (EDC), establishes a benchmark for both small and large-scale dataset condensation. In our testing, EDC achieves state-of-the-art accuracy, reaching 48.6% on ImageNet-1k with a ResNet-18 model at an IPC of 10, which corresponds to a compression ratio of 0.78%. This performance exceeds those of SRe2L, G-VBSM, and RDED by margins of 27.3%, 17.2%, and 6.6%, respectively.
Read more5/7/2024

0
Towards Model-Agnostic Dataset Condensation by Heterogeneous Models
Jun-Yeong Moon, Jung Uk Kim, Gyeong-Moon Park
Abstract. The advancement of deep learning has coincided with the proliferation of both models and available data. The surge in dataset sizes and the subsequent surge in computational requirements have led to the development of the Dataset Condensation (DC). While prior studies have delved into generating synthetic images through methods like distribution alignment and training trajectory tracking for more efficient model training, a significant challenge arises when employing these condensed images practically. Notably, these condensed images tend to be specific to particular models, constraining their versatility and practicality. In response to this limitation, we introduce a novel method, Heterogeneous Model Dataset Condensation (HMDC), designed to produce universally applicable condensed images through cross-model interactions. To address the issues of gradient magnitude difference and semantic distance in models when utilizing heterogeneous models, we propose the Gradient Balance Module (GBM) and Mutual Distillation (MD) with the SpatialSemantic Decomposition method. By balancing the contribution of each model and maintaining their semantic meaning closely, our approach overcomes the limitations associated with model-specific condensed images and enhances the broader utility. The source code is available in https://github.com/KHU-AGI/HMDC.
Read more9/24/2024