Data-Centric AI in the Age of Large Language Models
2406.14473
0
0
Abstract
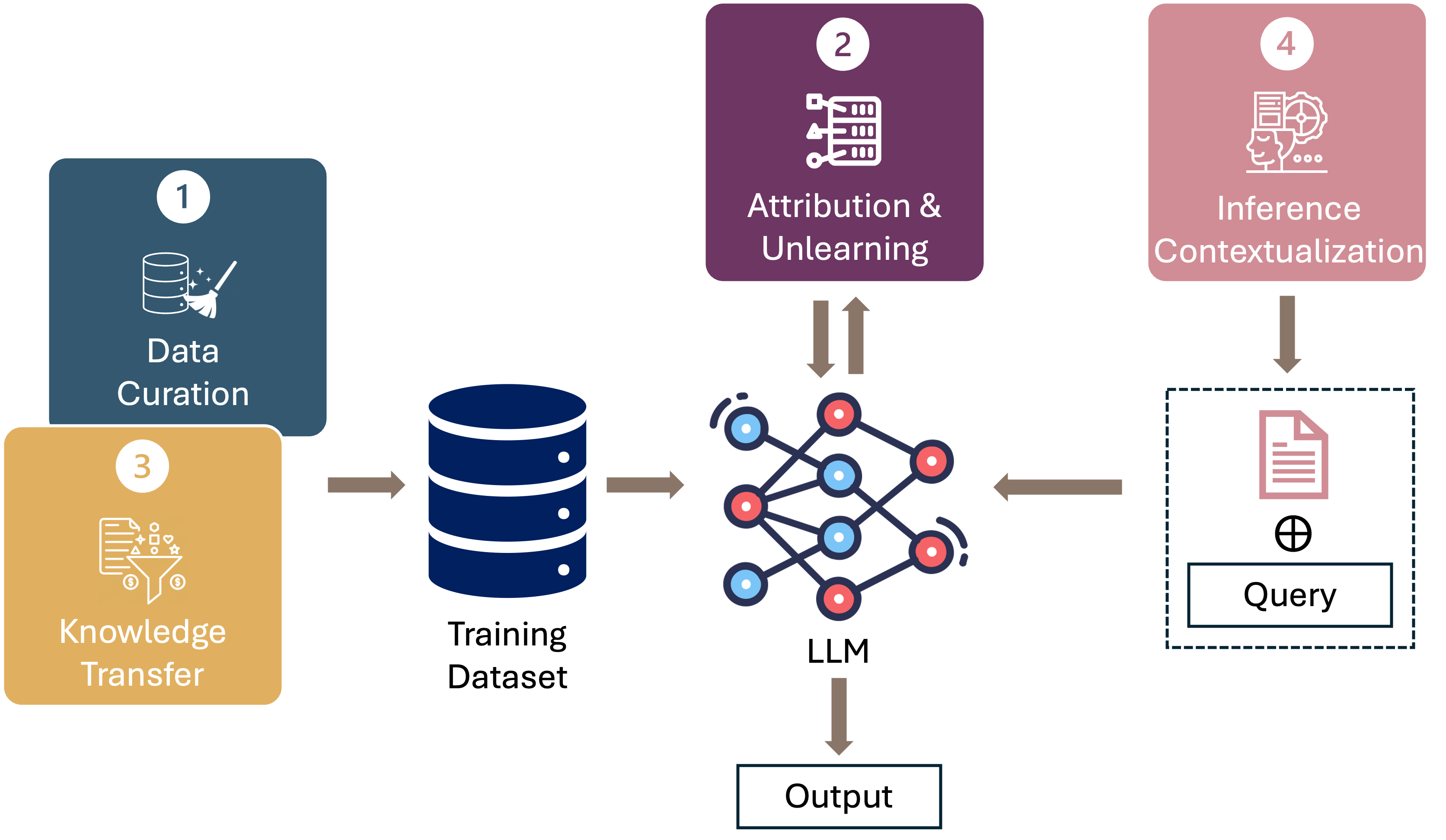
This position paper proposes a data-centric viewpoint of AI research, focusing on large language models (LLMs). We start by making the key observation that data is instrumental in the developmental (e.g., pretraining and fine-tuning) and inferential stages (e.g., in-context learning) of LLMs, and yet it receives disproportionally low attention from the research community. We identify four specific scenarios centered around data, covering data-centric benchmarks and data curation, data attribution, knowledge transfer, and inference contextualization. In each scenario, we underscore the importance of data, highlight promising research directions, and articulate the potential impacts on the research community and, where applicable, the society as a whole. For instance, we advocate for a suite of data-centric benchmarks tailored to the scale and complexity of data for LLMs. These benchmarks can be used to develop new data curation methods and document research efforts and results, which can help promote openness and transparency in AI and LLM research.
Create account to get full access
Overview
- Explores the role of data-centric AI in the era of large language models (LLMs)
- Discusses key challenges and opportunities in LLM training data curation and benchmark development
- Highlights the importance of strategic data ordering and efficient LLM architectures
Plain English Explanation
As large language models (LLMs) have become increasingly powerful, the focus in AI research has shifted towards the quality and curation of the training data used to develop these models. The paper examines how data-centric AI techniques can be leveraged to enhance the performance and capabilities of LLMs.
One crucial aspect is the development of appropriate benchmarks and training datasets. The paper discusses the importance of carefully curating and structuring the training data to ensure that LLMs learn the desired skills and knowledge. This includes considerations around data diversity, relevance, and potential biases.
Another key topic is the strategic ordering of training data, which can significantly impact the learning process of LLMs. The paper explores how the sequence in which training data is presented to LLMs can be optimized to accelerate learning and improve performance.
Finally, the paper also examines the design of efficient LLM architectures that can leverage training data in an optimal manner. The survey provides insights into various techniques for building LLMs that are computationally efficient and scalable, without compromising their capabilities.
Overall, the research highlights the critical role of data-centric AI in the age of LLMs, emphasizing the need for innovative approaches to training data, benchmarking, and model architecture design to unlock the full potential of these powerful language models.
Technical Explanation
The paper explores several key aspects of data-centric AI in the context of large language models (LLMs). One focus is on the development of appropriate benchmarks and curation of training data for LLMs. The authors discuss the importance of ensuring that the training data is diverse, relevant, and representative, with careful consideration of potential biases.
The paper also addresses the strategic ordering of training data, which can have a significant impact on the learning process of LLMs. The authors explore techniques for optimizing the sequence in which training data is presented to the models, with the goal of accelerating learning and improving overall performance.
Additionally, the research examines the design of efficient LLM architectures that can effectively leverage training data. The survey provides an overview of various approaches for building computationally efficient and scalable LLMs, while maintaining their impressive capabilities.
The paper also delves into the broader landscape of large language models, covering the foundational techniques and emerging trends in this rapidly evolving field of AI research.
Critical Analysis
The research presented in the paper highlights the importance of data-centric AI in the age of large language models, but it also acknowledges several caveats and limitations. One key challenge is the inherent complexity and diversity of natural language, which can make it challenging to develop comprehensive and unbiased benchmarks and training datasets.
Additionally, the authors note that the optimization of training data ordering, while promising, may have diminishing returns as models become larger and more sophisticated. Further research is needed to understand the limits of this approach and how it can be effectively integrated with other techniques for improving LLM performance.
The paper also emphasizes the need for efficient LLM architectures, but it does not provide a comprehensive evaluation of the tradeoffs between computational efficiency and model capabilities. Readers may want to explore additional sources to gain a more nuanced understanding of this design space.
Overall, the research presented in this paper offers valuable insights into the evolving field of data-centric AI and its implications for large language models. However, it is important to consider the paper's findings within the broader context of AI research and to remain critical and open-minded as the field continues to rapidly evolve.
Conclusion
The paper highlights the critical role of data-centric AI in the age of large language models (LLMs). It explores key challenges and opportunities in training data curation, benchmark development, strategic data ordering, and efficient LLM architecture design.
The research emphasizes the importance of carefully curating and structuring training data to ensure that LLMs learn the desired skills and knowledge, while mitigating potential biases. It also examines how the strategic ordering of training data can accelerate learning and improve model performance.
Additionally, the paper provides insights into the design of efficient LLM architectures that can leverage training data in an optimal manner, without compromising the models' capabilities.
The findings presented in this paper have significant implications for the continued advancement of large language models and their application in a wide range of domains. As the field of AI research continues to evolve, the principles of data-centric AI will likely play an increasingly crucial role in unlocking the full potential of these powerful language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

A Survey of Multimodal Large Language Model from A Data-centric Perspective
Tianyi Bai, Hao Liang, Binwang Wan, Ling Yang, Bozhou Li, Yifan Wang, Bin Cui, Conghui He, Binhang Yuan, Wentao Zhang
0
0
Human beings perceive the world through diverse senses such as sight, smell, hearing, and touch. Similarly, multimodal large language models (MLLMs) enhance the capabilities of traditional large language models by integrating and processing data from multiple modalities including text, vision, audio, video, and 3D environments. Data plays a pivotal role in the development and refinement of these models. In this survey, we comprehensively review the literature on MLLMs from a data-centric perspective. Specifically, we explore methods for preparing multimodal data during the pretraining and adaptation phases of MLLMs. Additionally, we analyze the evaluation methods for datasets and review benchmarks for evaluating MLLMs. Our survey also outlines potential future research directions. This work aims to provide researchers with a detailed understanding of the data-driven aspects of MLLMs, fostering further exploration and innovation in this field.
5/28/2024
🖼️
Better, Not Just More: Data-Centric Machine Learning for Earth Observation
Ribana Roscher, Marc Ru{ss}wurm, Caroline Gevaert, Michael Kampffmeyer, Jefersson A. dos Santos, Maria Vakalopoulou, Ronny Hansch, Stine Hansen, Keiller Nogueira, Jonathan Prexl, Devis Tuia
0
0
Recent developments and research in modern machine learning have led to substantial improvements in the geospatial field. Although numerous deep learning architectures and models have been proposed, the majority of them have been solely developed on benchmark datasets that lack strong real-world relevance. Furthermore, the performance of many methods has already saturated on these datasets. We argue that a shift from a model-centric view to a complementary data-centric perspective is necessary for further improvements in accuracy, generalization ability, and real impact on end-user applications. Furthermore, considering the entire machine learning cycle - from problem definition to model deployment with feedback - is crucial for enhancing machine learning models that can be reliable in unforeseen situations. This work presents a definition as well as a precise categorization and overview of automated data-centric learning approaches for geospatial data. It highlights the complementary role of data-centric learning with respect to model-centric in the larger machine learning deployment cycle. We review papers across the entire geospatial field and categorize them into different groups. A set of representative experiments shows concrete implementation examples. These examples provide concrete steps to act on geospatial data with data-centric machine learning approaches.
6/26/2024
🔗
Ziya2: Data-centric Learning is All LLMs Need
Ruyi Gan, Ziwei Wu, Renliang Sun, Junyu Lu, Xiaojun Wu, Dixiang Zhang, Kunhao Pan, Junqing He, Yuanhe Tian, Ping Yang, Qi Yang, Hao Wang, Jiaxing Zhang, Yan Song
0
0
Various large language models (LLMs) have been proposed in recent years, including closed- and open-source ones, continually setting new records on multiple benchmarks. However, the development of LLMs still faces several issues, such as high cost of training models from scratch, and continual pre-training leading to catastrophic forgetting, etc. Although many such issues are addressed along the line of research on LLMs, an important yet practical limitation is that many studies overly pursue enlarging model sizes without comprehensively analyzing and optimizing the use of pre-training data in their learning process, as well as appropriate organization and leveraging of such data in training LLMs under cost-effective settings. In this work, we propose Ziya2, a model with 13 billion parameters adopting LLaMA2 as the foundation model, and further pre-trained on 700 billion tokens, where we focus on pre-training techniques and use data-centric optimization to enhance the learning process of Ziya2 on different stages. We define three data attributes and firstly establish data-centric scaling laws to illustrate how different data impacts LLMs. Experiments show that Ziya2 significantly outperforms other models in multiple benchmarks especially with promising results compared to representative open-source ones. Ziya2 (Base) is released at https://huggingface.co/IDEA-CCNL/Ziya2-13B-Base and https://modelscope.cn/models/Fengshenbang/Ziya2-13B-Base/summary.
4/5/2024
📊
Strategic Data Ordering: Enhancing Large Language Model Performance through Curriculum Learning
Jisu Kim, Juhwan Lee
0
0
The rapid advancement of Large Language Models (LLMs) has improved text understanding and generation but poses challenges in computational resources. This study proposes a curriculum learning-inspired, data-centric training strategy that begins with simpler tasks and progresses to more complex ones, using criteria such as prompt length, attention scores, and loss values to structure the training data. Experiments with Mistral-7B (Jiang et al., 2023) and Gemma-7B (Team et al., 2024) models demonstrate that curriculum learning slightly improves performance compared to traditional random data shuffling. Notably, we observed that sorting data based on our proposed attention criteria generally led to better performance. This approach offers a sustainable method to enhance LLM performance without increasing model size or dataset volume, addressing scalability challenges in LLM training.
5/14/2024