Strategic Data Ordering: Enhancing Large Language Model Performance through Curriculum Learning
2405.07490
0
0
📊
Abstract
The rapid advancement of Large Language Models (LLMs) has improved text understanding and generation but poses challenges in computational resources. This study proposes a curriculum learning-inspired, data-centric training strategy that begins with simpler tasks and progresses to more complex ones, using criteria such as prompt length, attention scores, and loss values to structure the training data. Experiments with Mistral-7B (Jiang et al., 2023) and Gemma-7B (Team et al., 2024) models demonstrate that curriculum learning slightly improves performance compared to traditional random data shuffling. Notably, we observed that sorting data based on our proposed attention criteria generally led to better performance. This approach offers a sustainable method to enhance LLM performance without increasing model size or dataset volume, addressing scalability challenges in LLM training.
Create account to get full access
Overview
- Researchers proposed a curriculum learning-inspired training strategy for Large Language Models (LLMs) to improve performance without increasing model size or dataset volume.
- The strategy starts with simpler tasks and progresses to more complex ones, using criteria like prompt length, attention scores, and loss values to structure the training data.
- Experiments with two LLM models showed that this curriculum learning approach slightly improved performance compared to traditional random data shuffling.
- Sorting data based on the proposed attention criteria generally led to better model performance, addressing scalability challenges in LLM training.
Plain English Explanation
Large language models (LLMs) like Mistral-7B and Gemma-7B have made great strides in understanding and generating human-like text. However, training these models requires a lot of computational power and resources.
The researchers in this study came up with a new training strategy inspired by the concept of "curriculum learning." Instead of feeding the model a random mix of training data, they started with simpler tasks and gradually moved to more complex ones. They used different criteria, such as the length of the prompts, the model's attention scores, and the loss values, to organize the training data in a structured way.
When they tested this approach on the Mistral-7B and Gemma-7B models, they found that it led to a small but noticeable improvement in the models' performance compared to the traditional random data shuffling method. Interestingly, they discovered that sorting the data based on the attention criteria they proposed generally resulted in the best performance.
This research offers a sustainable way to enhance the capabilities of large language models without having to increase the model size or the amount of training data. This is an important step in addressing the scalability challenges that come with training these powerful AI systems.
Technical Explanation
The researchers proposed a curriculum learning-inspired, data-centric training strategy for Large Language Models (LLMs) to improve their performance without increasing model size or dataset volume. The key idea is to start with simpler tasks and progressively move to more complex ones, using criteria such as prompt length, attention scores, and loss values to structure the training data.
In their experiments, the team used the Mistral-7B [1] and Gemma-7B [2] models and found that the curriculum learning approach led to slightly better performance compared to the traditional random data shuffling method. Notably, sorting the data based on the proposed attention criteria generally resulted in the best model performance.
The researchers argue that this approach offers a sustainable way to enhance LLM capabilities by optimizing the training data, rather than simply increasing the model size or the dataset volume. This addresses the scalability challenges faced in LLM training, where the computational resources required can be prohibitive.
[1] Empowering Large Language Models with Textual Data Augmentation [2] Evaluating and Optimizing Educational Content for Large Language Model
Critical Analysis
The researchers' curriculum learning-inspired training strategy is an interesting approach to improving LLM performance without increasing model size or dataset volume. By structuring the training data in a more systematic way, the technique seems to offer a sustainable solution to the scalability challenges in LLM training.
However, the paper does not provide a detailed analysis of the specific mechanisms behind the performance improvements observed. It would be helpful to understand the intricacies of how the proposed attention criteria and the curriculum learning approach influence the model's learning process.
Additionally, the researchers only tested their method on two LLM models, Mistral-7B and Gemma-7B. It would be valuable to see how the technique performs on a broader range of LLMs, including those with different architectures and training datasets, to assess its generalizability.
Further research could also explore the potential trade-offs or limitations of this approach, such as the computational overhead required to implement the curriculum learning strategy or the impact on training time. Manipulating Large Language Models to Increase Product and A Novel Paradigm for Boosting Translation Capabilities of Large Language Models may provide relevant insights in this area.
Overall, the researchers have presented a promising approach to enhancing LLM performance, and further investigation into the nuances and broader applicability of their method could lead to valuable advancements in the field of large language models.
Conclusion
This study proposed a curriculum learning-inspired training strategy for Large Language Models (LLMs) that aims to improve performance without increasing model size or dataset volume. By structuring the training data based on criteria like prompt length, attention scores, and loss values, the researchers were able to achieve slightly better results compared to traditional random data shuffling.
The key insight is that optimizing the training data through a curriculum learning approach can be a sustainable way to enhance LLM capabilities, addressing the scalability challenges in LLM training. This research offers a potential path forward for developing more efficient and capable language models that can be deployed more widely, with implications for improving temporal awareness in LLMs for sequential recommendation and other applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

New!Curriculum Learning with Quality-Driven Data Selection
Biao Wu, Fang Meng, Ling Chen
0
0
The impressive multimodal capabilities demonstrated by OpenAI's GPT-4 have generated significant interest in the development of Multimodal Large Language Models (MLLMs). Visual instruction tuning of MLLMs with machine-generated instruction-following data has shown to enhance zero-shot capabilities across various tasks. However, there has been limited exploration into controlling the quality of the instruction data.Current methodologies for data selection in MLLMs often rely on single, unreliable scores or use downstream tasks for selection, which is time-consuming and can lead to potential overfitting on the chosen evaluation datasets. To mitigate these limitations, we propose a novel data selection methodology that utilizes image-text correlation and model perplexity to evaluate and select data of varying quality. This approach leverages the distinct distribution of these two attributes, mapping data quality into a two-dimensional space that allows for the selection of data based on their location within this distribution. By utilizing this space, we can analyze the impact of task type settings, used as prompts, on data quality. Additionally, this space can be used to construct multi-stage subsets of varying quality to facilitate curriculum learning. Our research includes comprehensive experiments conducted on various datasets. The results emphasize substantial enhancements in five commonly assessed capabilities compared to using the complete dataset. Our codes, data, and models are publicly available at: url{https://anonymous.4open.science/r/EHIT-31B4}
7/2/2024
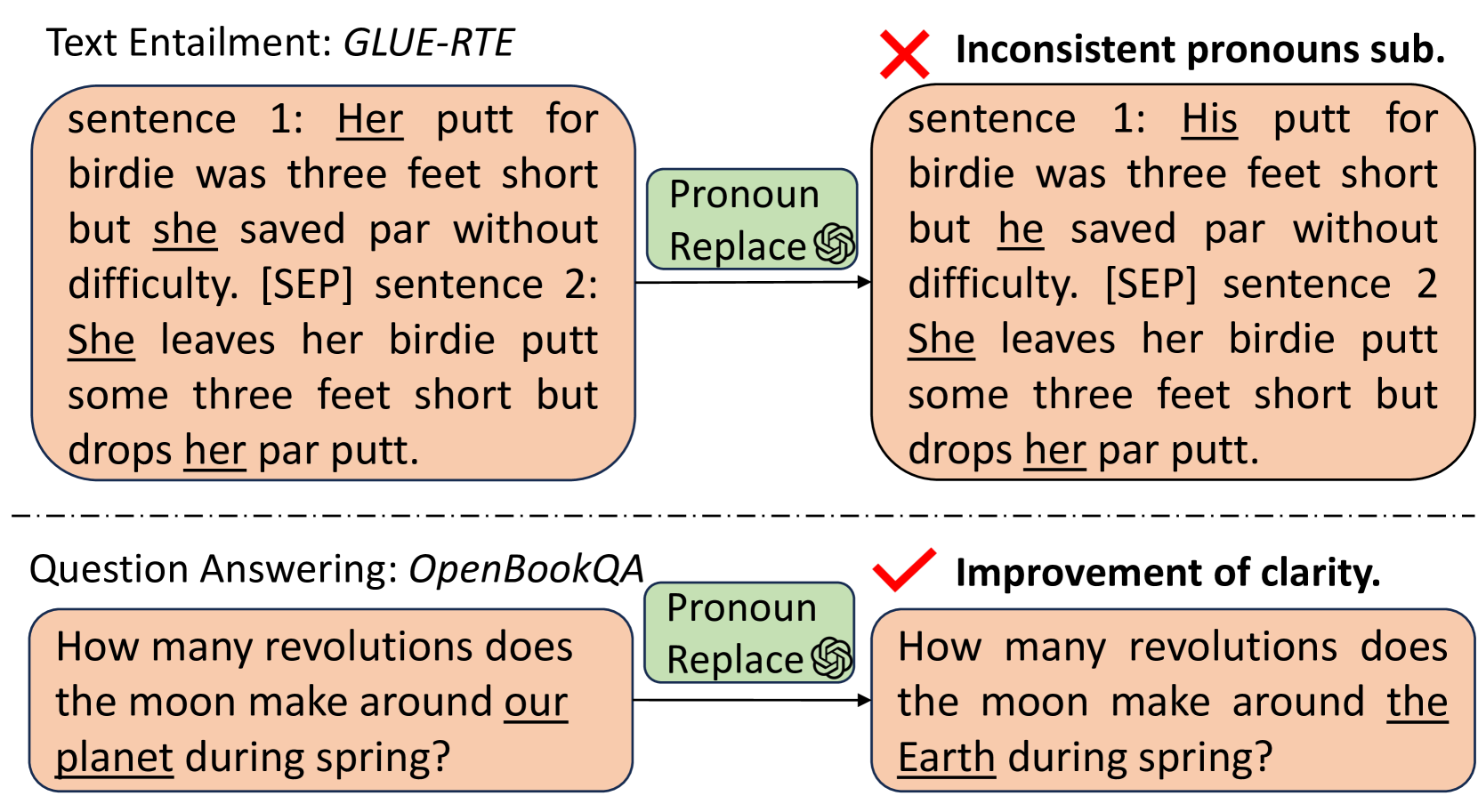
Empowering Large Language Models for Textual Data Augmentation
Yichuan Li, Kaize Ding, Jianling Wang, Kyumin Lee
0
0
With the capabilities of understanding and executing natural language instructions, Large language models (LLMs) can potentially act as a powerful tool for textual data augmentation. However, the quality of augmented data depends heavily on the augmentation instructions provided, and the effectiveness can fluctuate across different downstream tasks. While manually crafting and selecting instructions can offer some improvement, this approach faces scalability and consistency issues in practice due to the diversity of downstream tasks. In this work, we address these limitations by proposing a new solution, which can automatically generate a large pool of augmentation instructions and select the most suitable task-informed instructions, thereby empowering LLMs to create high-quality augmented data for different downstream tasks. Empirically, the proposed approach consistently generates augmented data with better quality compared to non-LLM and LLM-based data augmentation methods, leading to the best performance on 26 few-shot learning tasks sourced from a wide range of application domains.
4/30/2024

Large Language Model-Driven Curriculum Design for Mobile Networks
Omar Erak, Omar Alhussein, Shimaa Naser, Nouf Alabbasi, De Mi, Sami Muhaidat
0
0
This study introduces an innovative framework that employs large language models (LLMs) to automate the design and generation of curricula for reinforcement learning (RL). As mobile networks evolve towards the 6G era, managing their increasing complexity and dynamic nature poses significant challenges. Conventional RL approaches often suffer from slow convergence and poor generalization due to conflicting objectives and the large state and action spaces associated with mobile networks. To address these shortcomings, we introduce curriculum learning, a method that systematically exposes the RL agent to progressively challenging tasks, improving convergence and generalization. However, curriculum design typically requires extensive domain knowledge and manual human effort. Our framework mitigates this by utilizing the generative capabilities of LLMs to automate the curriculum design process, significantly reducing human effort while improving the RL agent's convergence and performance. We deploy our approach within a simulated mobile network environment and demonstrate improved RL convergence rates, generalization to unseen scenarios, and overall performance enhancements. As a case study, we consider autonomous coordination and user association in mobile networks. Our obtained results highlight the potential of combining LLM-based curriculum generation with RL for managing next-generation wireless networks, marking a significant step towards fully autonomous network operations.
6/24/2024
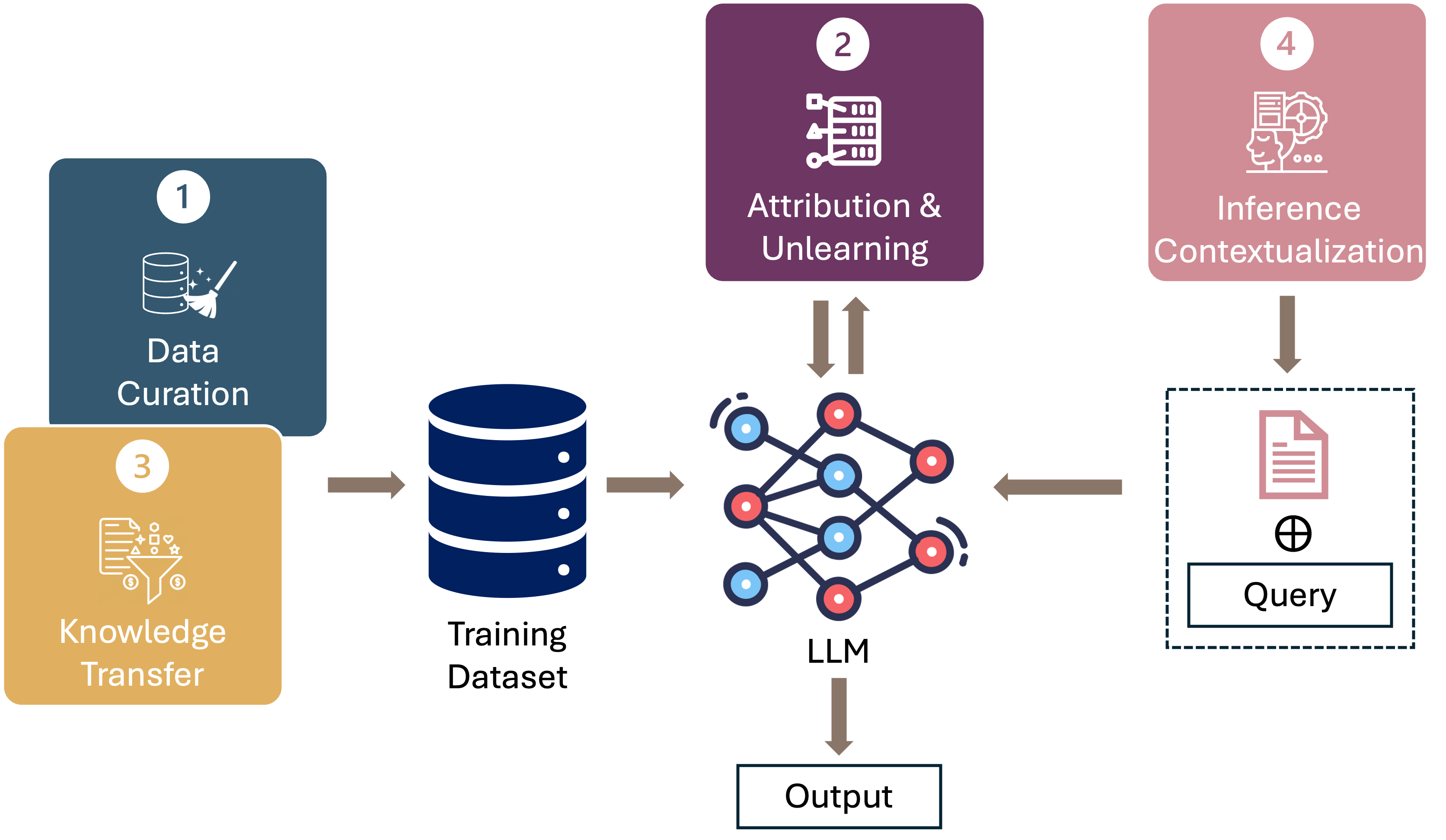
Data-Centric AI in the Age of Large Language Models
Xinyi Xu, Zhaoxuan Wu, Rui Qiao, Arun Verma, Yao Shu, Jingtan Wang, Xinyuan Niu, Zhenfeng He, Jiangwei Chen, Zijian Zhou, Gregory Kang Ruey Lau, Hieu Dao, Lucas Agussurja, Rachael Hwee Ling Sim, Xiaoqiang Lin, Wenyang Hu, Zhongxiang Dai, Pang Wei Koh, Bryan Kian Hsiang Low
0
0
This position paper proposes a data-centric viewpoint of AI research, focusing on large language models (LLMs). We start by making the key observation that data is instrumental in the developmental (e.g., pretraining and fine-tuning) and inferential stages (e.g., in-context learning) of LLMs, and yet it receives disproportionally low attention from the research community. We identify four specific scenarios centered around data, covering data-centric benchmarks and data curation, data attribution, knowledge transfer, and inference contextualization. In each scenario, we underscore the importance of data, highlight promising research directions, and articulate the potential impacts on the research community and, where applicable, the society as a whole. For instance, we advocate for a suite of data-centric benchmarks tailored to the scale and complexity of data for LLMs. These benchmarks can be used to develop new data curation methods and document research efforts and results, which can help promote openness and transparency in AI and LLM research.
6/21/2024