A data-centric approach for assessing progress of Graph Neural Networks
2406.12439
0
0
Abstract
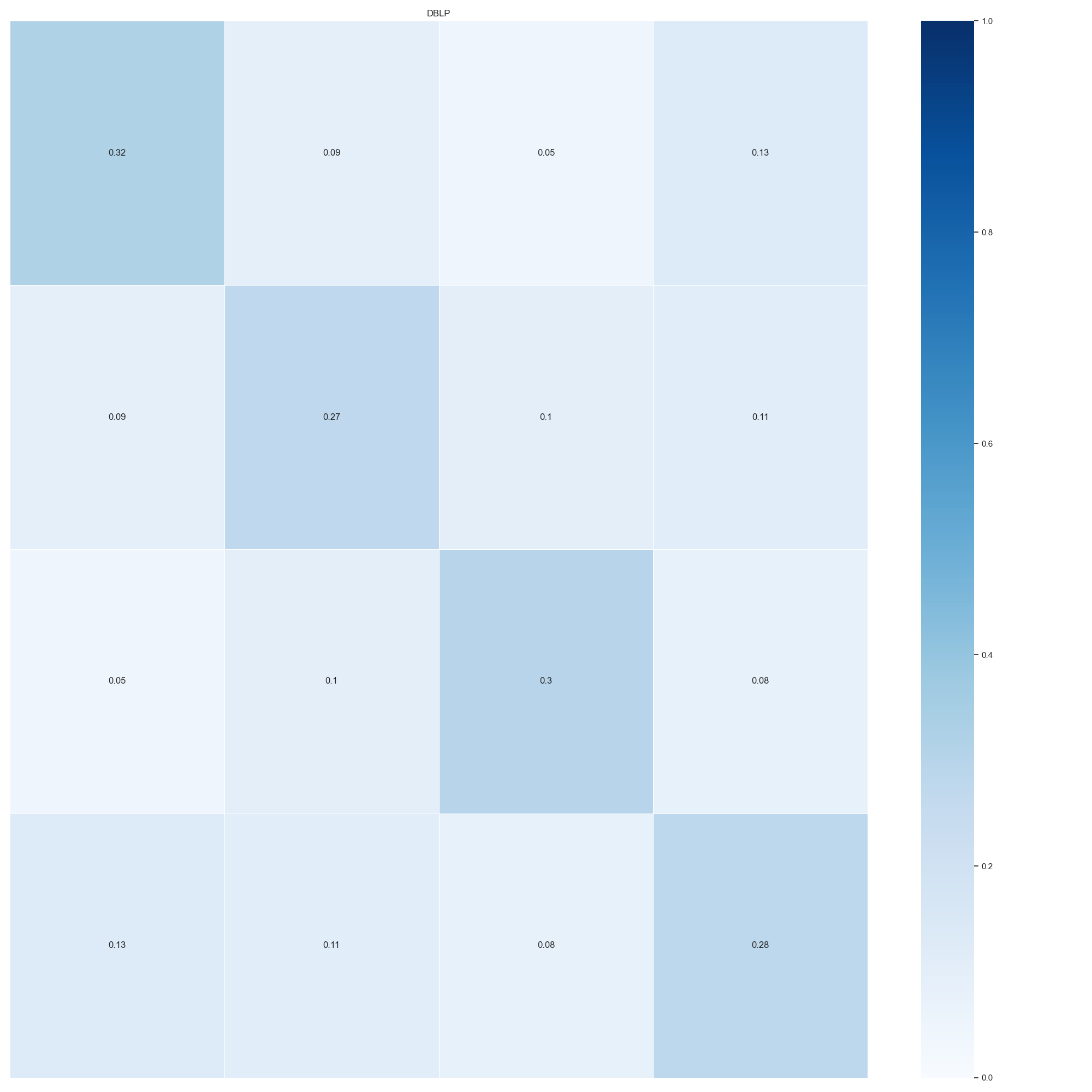
Graph Neural Networks (GNNs) have achieved state-of-the-art results in node classification tasks. However, most improvements are in multi-class classification, with less focus on the cases where each node could have multiple labels. The first challenge in studying multi-label node classification is the scarcity of publicly available datasets. To address this, we collected and released three real-world biological datasets and developed a multi-label graph generator with tunable properties. We also argue that traditional notions of homophily and heterophily do not apply well to multi-label scenarios. Therefore, we define homophily and Cross-Class Neighborhood Similarity for multi-label classification and investigate $9$ collected multi-label datasets. Lastly, we conducted a large-scale comparative study with $8$ methods across nine datasets to evaluate current progress in multi-label node classification. We release our code at url{https://github.com/Tianqi-py/MLGNC}.
Create account to get full access
Overview
- This paper proposes a data-centric approach for assessing the progress of Graph Neural Networks (GNNs) on node classification tasks.
- The authors argue that traditional evaluation metrics, such as accuracy, do not provide a comprehensive understanding of GNN performance, especially in the context of diverse graph datasets.
- The proposed approach focuses on analyzing the properties of graph datasets, including homophily and heterophily, and how they impact GNN performance.
Plain English Explanation
The paper is about a new way to evaluate how well Graph Neural Networks (GNNs) perform on the task of node classification. Node classification is when you want to predict the category or label of a node (e.g., a person, a website, or a chemical compound) in a graph.
Traditionally, researchers have used metrics like accuracy to measure how well GNNs perform. However, the authors argue that this doesn't give a full picture, especially when dealing with different types of graph datasets. Some graphs have nodes that are very similar to their neighbors (homophily), while others have nodes that are quite different from their neighbors (heterophily).
The new approach focuses on understanding the properties of the graph dataset, like how homophilic or heterophilic it is, and then evaluating how well the GNN performs in that context. This provides a more nuanced and comprehensive way to assess the progress of GNN models, beyond just looking at overall accuracy.
Technical Explanation
The paper introduces a data-centric approach for evaluating the performance of Graph Neural Networks (GNNs) on node classification tasks. The key idea is to go beyond traditional evaluation metrics, like accuracy, and instead focus on understanding the properties of the graph dataset and how they impact GNN performance.
The authors specifically examine the concepts of homophily and heterophily in graph datasets. Homophily refers to the tendency of nodes to be similar to their neighbors, while heterophily refers to the opposite - nodes being dissimilar to their neighbors.
The proposed approach involves several steps:
- Characterizing the graph dataset in terms of its homophilic and heterophilic properties.
- Evaluating GNN performance on the dataset, not just in terms of overall accuracy, but also how the GNN behaves in different homophilic and heterophilic regions of the graph.
- Analyzing the results to gain insights into the strengths and weaknesses of the GNN model, and how it can be improved to handle diverse graph scenarios, including those with high levels of heterophily.
The paper presents experiments on various graph datasets, including those with varying degrees of homophily and heterophily. The results show that the data-centric approach provides a more comprehensive understanding of GNN performance compared to traditional evaluation metrics, and can help guide the development of more robust and generalizable GNN models.
Critical Analysis
The paper presents a thoughtful and well-designed approach for evaluating the progress of Graph Neural Networks (GNNs) on node classification tasks. The authors make a compelling case that traditional evaluation metrics, such as accuracy, do not provide a complete picture of GNN performance, especially in the context of diverse graph datasets with varying degrees of homophily and heterophily.
The data-centric approach proposed in the paper is a valuable contribution, as it shifts the focus towards understanding the underlying properties of the graph dataset and how they impact GNN performance. This provides researchers and practitioners with a more nuanced and insightful way to assess the strengths and weaknesses of GNN models, which can then inform the development of more robust and generalizable architectures.
One potential limitation of the study is the reliance on a relatively small number of graph datasets, which may not fully capture the breadth of real-world graph scenarios. It would be valuable to see the proposed approach applied to a larger and more diverse set of datasets, including those with more complex structures and properties.
Additionally, while the paper provides a solid technical explanation of the proposed approach, more discussion on the practical implications and potential challenges in deploying this method in real-world settings could be beneficial. For example, how would the data-centric analysis be integrated into the GNN development workflow, and what considerations need to be made when applying it to large-scale, industrial-grade graph datasets?
Overall, this paper represents a significant step forward in the understanding and evaluation of Graph Neural Networks. By shifting the focus towards the properties of the data itself, the authors have opened up new avenues for improving the performance and generalization of these powerful machine learning models, which could have far-reaching implications for a wide range of graph-based applications.
Conclusion
This paper proposes a data-centric approach for assessing the progress of Graph Neural Networks (GNNs) on node classification tasks. The key idea is to move beyond traditional evaluation metrics, such as accuracy, and instead focus on understanding the properties of the graph dataset, particularly its homophilic and heterophilic characteristics, and how they impact GNN performance.
The proposed approach provides a more comprehensive and nuanced way to evaluate GNN models, enabling researchers and practitioners to gain deeper insights into their strengths, weaknesses, and potential areas for improvement. By shifting the focus towards the underlying data properties, this work represents a significant step forward in the development of more robust and generalizable GNN architectures, which could have far-reaching implications for a wide range of graph-based applications.
The critical analysis suggests that while the paper presents a solid technical contribution, further exploration of the practical implications and potential challenges in deploying the data-centric approach would be valuable. Nonetheless, this research represents an important milestone in the ongoing efforts to advance the state-of-the-art in Graph Neural Networks and unlock their full potential.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏷️
Article Classification with Graph Neural Networks and Multigraphs
Khang Ly, Yury Kashnitsky, Savvas Chamezopoulos, Valeria Krzhizhanovskaya
0
0
Classifying research output into context-specific label taxonomies is a challenging and relevant downstream task, given the volume of existing and newly published articles. We propose a method to enhance the performance of article classification by enriching simple Graph Neural Network (GNN) pipelines with multi-graph representations that simultaneously encode multiple signals of article relatedness, e.g. references, co-authorship, shared publication source, shared subject headings, as distinct edge types. Fully supervised transductive node classification experiments are conducted on the Open Graph Benchmark OGBN-arXiv dataset and the PubMed diabetes dataset, augmented with additional metadata from Microsoft Academic Graph and PubMed Central, respectively. The results demonstrate that multi-graphs consistently improve the performance of a variety of GNN models compared to the default graphs. When deployed with SOTA textual node embedding methods, the transformed multi-graphs enable simple and shallow 2-layer GNN pipelines to achieve results on par with more complex architectures.
5/29/2024
🧠
Incorporating Heterophily into Graph Neural Networks for Graph Classification
Jiayi Yang, Sourav Medya, Wei Ye
0
0
Graph Neural Networks (GNNs) often assume strong homophily for graph classification, seldom considering heterophily, which means connected nodes tend to have different class labels and dissimilar features. In real-world scenarios, graphs may have nodes that exhibit both homophily and heterophily. Failing to generalize to this setting makes many GNNs underperform in graph classification. In this paper, we address this limitation by identifying three effective designs and develop a novel GNN architecture called IHGNN (short for Incorporating Heterophily into Graph Neural Networks). These designs include the combination of integration and separation of the ego- and neighbor-embeddings of nodes, adaptive aggregation of node embeddings from different layers, and differentiation between different node embeddings for constructing the graph-level readout function. We empirically validate IHGNN on various graph datasets and demonstrate that it outperforms the state-of-the-art GNNs for graph classification.
5/10/2024
Global-Local Graph Neural Networks for Node-Classification
Moshe Eliasof, Eran Treister
0
0
The task of graph node classification is often approached by utilizing a local Graph Neural Network (GNN), that learns only local information from the node input features and their adjacency. In this paper, we propose to improve the performance of node classification GNNs by utilizing both global and local information, specifically by learning label- and node- features. We therefore call our method Global-Local-GNN (GLGNN). To learn proper label features, for each label, we maximize the similarity between its features and nodes features that belong to the label, while maximizing the distance between nodes that do not belong to the considered label. We then use the learnt label features to predict the node classification map. We demonstrate our GLGNN using three different GNN backbones, and show that our approach improves baseline performance, revealing the importance of global information utilization for node classification.
6/18/2024
🤔
Characterizing Graph Datasets for Node Classification: Homophily-Heterophily Dichotomy and Beyond
Oleg Platonov, Denis Kuznedelev, Artem Babenko, Liudmila Prokhorenkova
0
0
Homophily is a graph property describing the tendency of edges to connect similar nodes; the opposite is called heterophily. It is often believed that heterophilous graphs are challenging for standard message-passing graph neural networks (GNNs), and much effort has been put into developing efficient methods for this setting. However, there is no universally agreed-upon measure of homophily in the literature. In this work, we show that commonly used homophily measures have critical drawbacks preventing the comparison of homophily levels across different datasets. For this, we formalize desirable properties for a proper homophily measure and verify which measures satisfy which properties. In particular, we show that a measure that we call adjusted homophily satisfies more desirable properties than other popular homophily measures while being rarely used in graph machine learning literature. Then, we go beyond the homophily-heterophily dichotomy and propose a new characteristic that allows one to further distinguish different sorts of heterophily. The proposed label informativeness (LI) characterizes how much information a neighbor's label provides about a node's label. We prove that this measure satisfies important desirable properties. We also observe empirically that LI better agrees with GNN performance compared to homophily measures, which confirms that it is a useful characteristic of the graph structure.
4/17/2024