Data Cleaning and Machine Learning: A Systematic Literature Review
2310.01765
0
0
Abstract
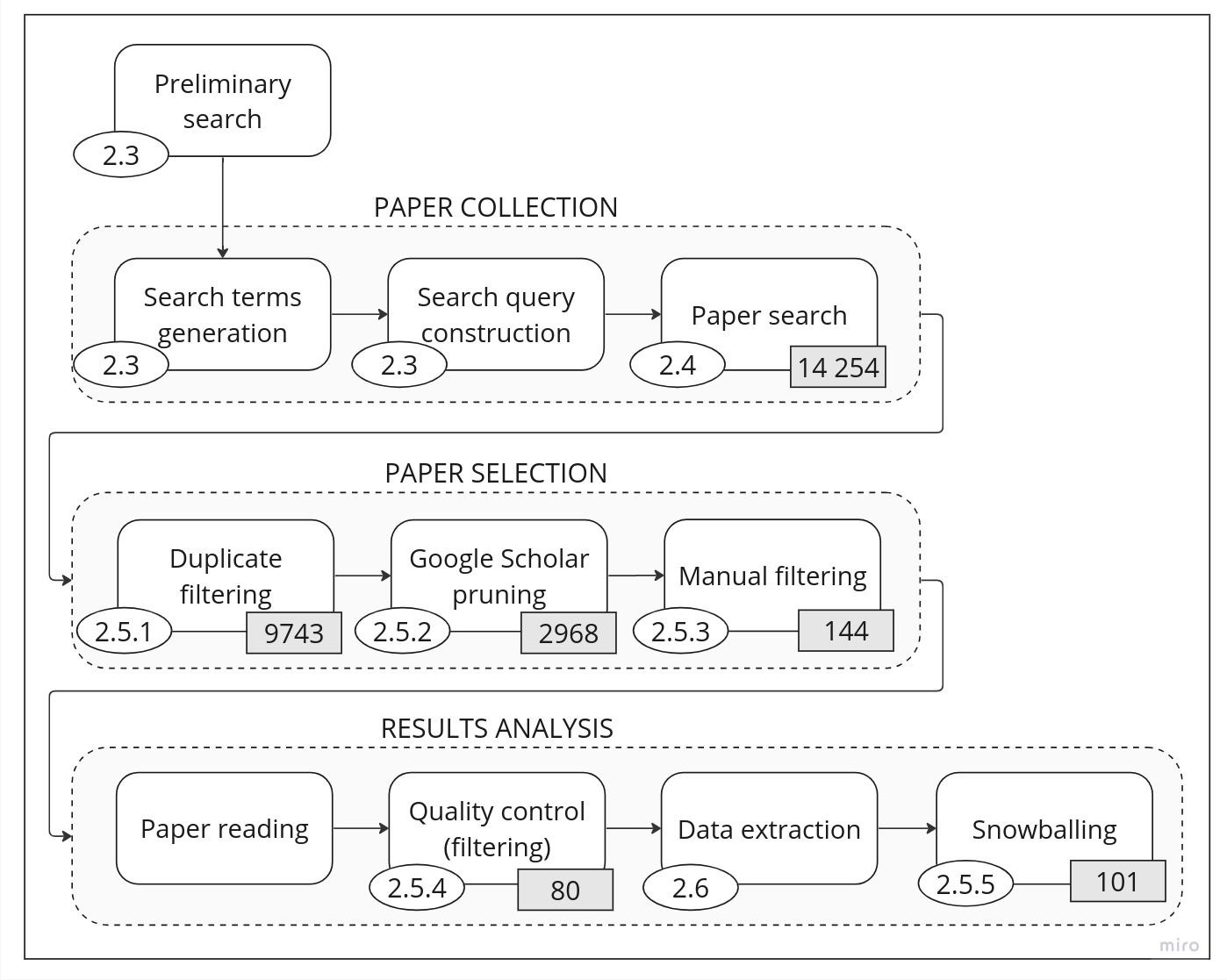
Context: Machine Learning (ML) is integrated into a growing number of systems for various applications. Because the performance of an ML model is highly dependent on the quality of the data it has been trained on, there is a growing interest in approaches to detect and repair data errors (i.e., data cleaning). Researchers are also exploring how ML can be used for data cleaning; hence creating a dual relationship between ML and data cleaning. To the best of our knowledge, there is no study that comprehensively reviews this relationship. Objective: This paper's objectives are twofold. First, it aims to summarize the latest approaches for data cleaning for ML and ML for data cleaning. Second, it provides future work recommendations. Method: We conduct a systematic literature review of the papers published between 2016 and 2022 inclusively. We identify different types of data cleaning activities with and for ML: feature cleaning, label cleaning, entity matching, outlier detection, imputation, and holistic data cleaning. Results: We summarize the content of 101 papers covering various data cleaning activities and provide 24 future work recommendations. Our review highlights many promising data cleaning techniques that can be further extended. Conclusion: We believe that our review of the literature will help the community develop better approaches to clean data.
Create account to get full access
Overview
- This paper presents a systematic literature review on the topic of data cleaning and its impact on machine learning.
- The research was funded by the Fonds de Recherche du Quebec (FRQ), the Canadian Institute for Advanced Research (CIFAR), and the National Science and Engineering Research Council of Canada (NSERC).
Plain English Explanation
This paper explores the important role of data cleaning in the field of machine learning. Data cleaning refers to the process of identifying and correcting errors, inconsistencies, or missing values in a dataset before it is used for analysis or training machine learning models. The authors conducted a thorough review of the existing research on this topic to understand the current state of knowledge and identify key insights.
The review examines how different data cleaning techniques and approaches can impact the performance and reliability of machine learning models. For example, effective data cleaning can improve model accuracy and robustness, while poor data cleaning can lead to biased or unreliable results. The authors also explore the relationship between data cleaning and other aspects of the machine learning workflow, such as dataset development and business process management.
By synthesizing the findings from multiple studies, the review provides a comprehensive understanding of the role of data cleaning in machine learning and highlights areas where further research is needed. This knowledge can inform the practices of data scientists, machine learning engineers, and organizations seeking to effectively leverage machine learning to drive insights and innovation.
Technical Explanation
The authors conducted a systematic literature review to investigate the current state of research on data cleaning and its impact on machine learning. They searched various academic databases and identified 165 relevant articles published between 2010 and 2022. These articles were then carefully analyzed and synthesized to address the following research questions:
- What are the key data cleaning techniques and approaches used in machine learning applications?
- How do different data cleaning methods and strategies affect the performance and reliability of machine learning models?
- What is the relationship between data cleaning and other aspects of the machine learning workflow, such as dataset development and business process management?
The review revealed a diverse range of data cleaning techniques, including outlier detection, missing value imputation, feature engineering, and data transformation. The authors found that the choice and implementation of these techniques can have a significant impact on model performance, with effective data cleaning leading to improved accuracy, robustness, and generalization. However, the review also highlighted the need for more research on the trade-offs and contextual factors that influence the effectiveness of different data cleaning approaches.
Furthermore, the authors identified linkages between data cleaning and other components of the machine learning pipeline, such as dataset development and business process management. For example, the review suggests that effective data cleaning can enhance the quality and reliability of machine learning datasets, which in turn supports the development of robust and high-performing models.
Critical Analysis
The systematic literature review presented in this paper provides a valuable synthesis of the current research on data cleaning and its impact on machine learning. The authors have done a commendable job of identifying and analyzing a comprehensive set of relevant studies, and their findings offer important insights for both researchers and practitioners in the field.
One potential limitation of the review is the relatively narrow time frame of the included studies (2010-2022). While this helps to ensure the relevance of the findings, it may also miss important earlier work or exclude more recent advancements in the field. Additionally, the review focuses primarily on the technical aspects of data cleaning and model performance, without delving deeply into the broader implications or practical challenges of implementing effective data cleaning strategies in real-world machine learning applications.
Further research could explore these areas in more depth, addressing questions such as the organizational and human factors that influence data cleaning practices, the ethical considerations around data quality and bias, and the potential trade-offs between data cleaning and other aspects of the machine learning workflow. Additionally, a more nuanced analysis of the contextual factors that shape the effectiveness of different data cleaning techniques could provide valuable insights for practitioners.
Conclusion
This systematic literature review offers a comprehensive and insightful exploration of the role of data cleaning in machine learning. The authors have synthesized a wealth of research to demonstrate the significant impact that data cleaning can have on the performance and reliability of machine learning models. By highlighting the linkages between data cleaning and other components of the machine learning pipeline, the review also underscores the importance of adopting a holistic, workflow-oriented approach to data management and model development.
The findings of this review have important implications for both researchers and practitioners in the field of machine learning. They underscore the critical need for robust and effective data cleaning strategies, and they provide a valuable foundation for future work aimed at further advancing our understanding of this crucial aspect of the machine learning process.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🐍
SyROCCo: Enhancing Systematic Reviews using Machine Learning
Zheng Fang, Miguel Arana-Catania, Felix-Anselm van Lier, Juliana Outes Velarde, Harry Bregazzi, Mara Airoldi, Eleanor Carter, Rob Procter
0
0
The sheer number of research outputs published every year makes systematic reviewing increasingly time- and resource-intensive. This paper explores the use of machine learning techniques to help navigate the systematic review process. ML has previously been used to reliably 'screen' articles for review - that is, identify relevant articles based on reviewers' inclusion criteria. The application of ML techniques to subsequent stages of a review, however, such as data extraction and evidence mapping, is in its infancy. We therefore set out to develop a series of tools that would assist in the profiling and analysis of 1,952 publications on the theme of 'outcomes-based contracting'. Tools were developed for the following tasks: assign publications into 'policy area' categories; identify and extract key information for evidence mapping, such as organisations, laws, and geographical information; connect the evidence base to an existing dataset on the same topic; and identify subgroups of articles that may share thematic content. An interactive tool using these techniques and a public dataset with their outputs have been released. Our results demonstrate the utility of ML techniques to enhance evidence accessibility and analysis within the systematic review processes. These efforts show promise in potentially yielding substantial efficiencies for future systematic reviewing and for broadening their analytical scope. Our work suggests that there may be implications for the ease with which policymakers and practitioners can access evidence. While ML techniques seem poised to play a significant role in bridging the gap between research and policy by offering innovative ways of gathering, accessing, and analysing data from systematic reviews, we also highlight their current limitations and the need to exercise caution in their application, particularly given the potential for errors and biases.
6/26/2024
New!Systematic Literature Review on Application of Learning-based Approaches in Continuous Integration
Ali Kazemi Arani, Triet Huynh Minh Le, Mansooreh Zahedi, M. Ali Babar
0
0
Context: Machine learning (ML) and deep learning (DL) analyze raw data to extract valuable insights in specific phases. The rise of continuous practices in software projects emphasizes automating Continuous Integration (CI) with these learning-based methods, while the growing adoption of such approaches underscores the need for systematizing knowledge. Objective: Our objective is to comprehensively review and analyze existing literature concerning learning-based methods within the CI domain. We endeavour to identify and analyse various techniques documented in the literature, emphasizing the fundamental attributes of training phases within learning-based solutions in the context of CI. Method: We conducted a Systematic Literature Review (SLR) involving 52 primary studies. Through statistical and thematic analyses, we explored the correlations between CI tasks and the training phases of learning-based methodologies across the selected studies, encompassing a spectrum from data engineering techniques to evaluation metrics. Results: This paper presents an analysis of the automation of CI tasks utilizing learning-based methods. We identify and analyze nine types of data sources, four steps in data preparation, four feature types, nine subsets of data features, five approaches for hyperparameter selection and tuning, and fifteen evaluation metrics. Furthermore, we discuss the latest techniques employed, existing gaps in CI task automation, and the characteristics of the utilized learning-based techniques. Conclusion: This study provides a comprehensive overview of learning-based methods in CI, offering valuable insights for researchers and practitioners developing CI task automation. It also highlights the need for further research to advance these methods in CI.
7/1/2024
🗣️
A Systematic Literature Review on the Use of Machine Learning in Software Engineering
Nyaga Fred, I. O. Temkin
0
0
Software engineering (SE) is a dynamic field that involves multiple phases all of which are necessary to develop sustainable software systems. Machine learning (ML), a branch of artificial intelligence (AI), has drawn a lot of attention in recent years thanks to its ability to analyze massive volumes of data and extract useful patterns from data. Several studies have focused on examining, categorising, and assessing the application of ML in SE processes. We conducted a literature review on primary studies to address this gap. The study was carried out following the objective and the research questions to explore the current state of the art in applying machine learning techniques in software engineering processes. The review identifies the key areas within software engineering where ML has been applied, including software quality assurance, software maintenance, software comprehension, and software documentation. It also highlights the specific ML techniques that have been leveraged in these domains, such as supervised learning, unsupervised learning, and deep learning. Keywords: machine learning, deep learning, software engineering, natural language processing, source code
6/21/2024
📊
Developing an efficient corpus using Ensemble Data cleaning approach
Md Taimur Ahad
0
0
Despite the observable benefit of Natural Language Processing (NLP) in processing a large amount of textual medical data within a limited time for information retrieval, a handful of research efforts have been devoted to uncovering novel data-cleaning methods. Data cleaning in NLP is at the centre point for extracting validated information. Another observed limitation in the NLP domain is having limited medical corpora that provide answers to a given medical question. Realising the limitations and challenges from two perspectives, this research aims to clean a medical dataset using ensemble techniques and to develop a corpus. The corpora expect that it will answer the question based on the semantic relationship of corpus sequences. However, the data cleaning method in this research suggests that the ensemble technique provides the highest accuracy (94%) compared to the single process, which includes vectorisation, exploratory data analysis, and feeding the vectorised data. The second aim of having an adequate corpus was realised by extracting answers from the dataset. This research is significant in machine learning, specifically data cleaning and the medical sector, but it also underscores the importance of NLP in the medical field, where accurate and timely information extraction can be a matter of life and death. It establishes text data processing using NLP as a powerful tool for extracting valuable information like image data.
6/4/2024