Systematic Literature Review on Application of Learning-based Approaches in Continuous Integration
2406.19765
0
0
Abstract
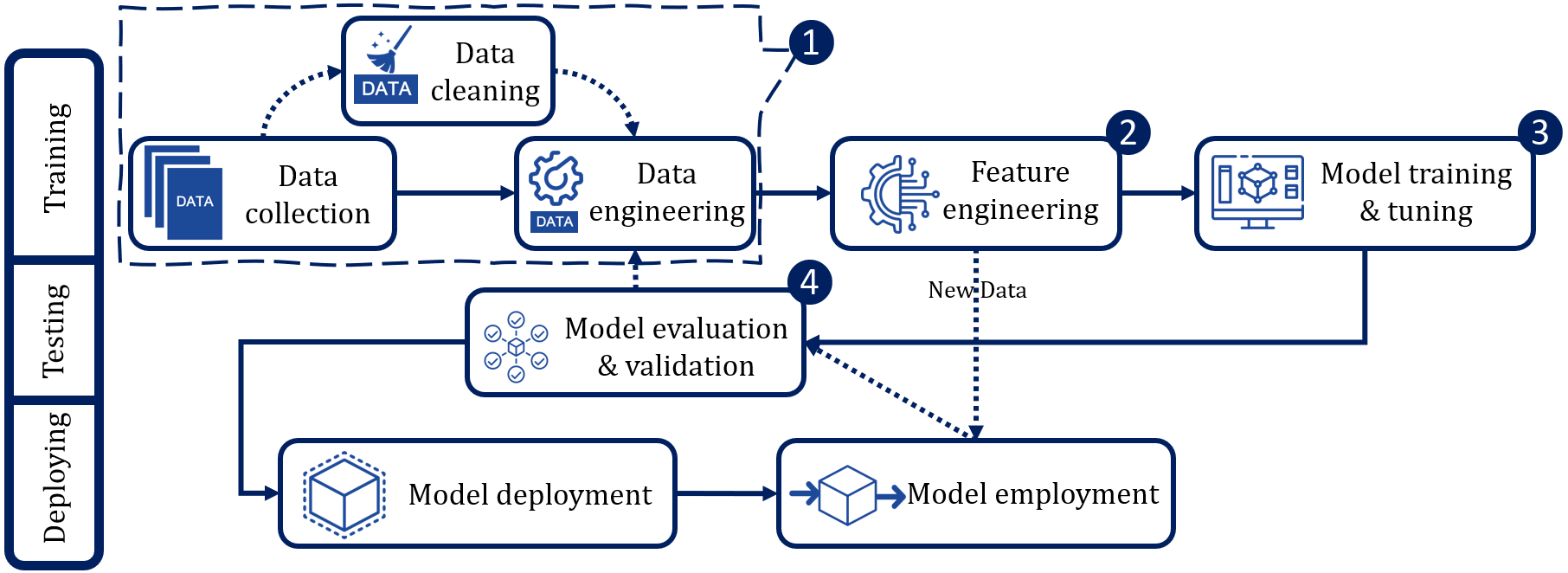
Context: Machine learning (ML) and deep learning (DL) analyze raw data to extract valuable insights in specific phases. The rise of continuous practices in software projects emphasizes automating Continuous Integration (CI) with these learning-based methods, while the growing adoption of such approaches underscores the need for systematizing knowledge. Objective: Our objective is to comprehensively review and analyze existing literature concerning learning-based methods within the CI domain. We endeavour to identify and analyse various techniques documented in the literature, emphasizing the fundamental attributes of training phases within learning-based solutions in the context of CI. Method: We conducted a Systematic Literature Review (SLR) involving 52 primary studies. Through statistical and thematic analyses, we explored the correlations between CI tasks and the training phases of learning-based methodologies across the selected studies, encompassing a spectrum from data engineering techniques to evaluation metrics. Results: This paper presents an analysis of the automation of CI tasks utilizing learning-based methods. We identify and analyze nine types of data sources, four steps in data preparation, four feature types, nine subsets of data features, five approaches for hyperparameter selection and tuning, and fifteen evaluation metrics. Furthermore, we discuss the latest techniques employed, existing gaps in CI task automation, and the characteristics of the utilized learning-based techniques. Conclusion: This study provides a comprehensive overview of learning-based methods in CI, offering valuable insights for researchers and practitioners developing CI task automation. It also highlights the need for further research to advance these methods in CI.
Create account to get full access
Overview
- This paper presents a systematic literature review on the application of learning-based approaches in Continuous Integration (CI) pipelines.
- The authors examine how machine learning and other data-driven techniques are being used to enhance various aspects of CI, such as build automation, test case generation, and anomaly detection.
- The review aims to provide a comprehensive overview of the current state of research in this area and identify emerging trends, challenges, and opportunities for future work.
Plain English Explanation
The paper explores how machine learning and other advanced data analysis techniques are being used to improve the process of Continuous Integration (CI) in software development. CI is a crucial part of the software development lifecycle, where developers regularly integrate their code changes into a shared repository and automatically build, test, and deploy the software.
The researchers conducted a systematic literature review to understand how researchers and practitioners are applying learning-based approaches to various CI tasks, such as automatically generating test cases, detecting anomalies in the build process, and optimizing the overall CI pipeline.
By reviewing the existing research in this area, the authors aim to provide a comprehensive overview of the current state of the field and identify promising directions for future work. This could help software development teams enhance their CI practices by leveraging the power of machine learning and other data-driven techniques.
Technical Explanation
The paper presents a systematic literature review on the application of learning-based approaches in Continuous Integration (CI) pipelines. The authors conducted a rigorous search of relevant literature, including academic databases and industry publications, to identify studies that explore the use of machine learning, deep learning, and other data-driven techniques to improve various aspects of CI.
The review covers a wide range of CI-related tasks, such as build automation, test case generation, build and test result analysis, and anomaly detection. For each task, the authors summarize the key findings, highlighting the specific learning-based approaches employed, the performance improvements achieved, and any notable challenges or limitations identified in the research.
The paper also discusses emerging trends and future research directions in this field, such as the integration of large language models for task automation, the use of reinforcement learning for CI pipeline optimization, and the application of unsupervised learning techniques for anomaly detection.
Critical Analysis
The paper provides a comprehensive and well-structured review of the existing research on the application of learning-based approaches in Continuous Integration. The authors have conducted a thorough search and selection process to ensure the relevance and quality of the included studies.
One potential limitation of the review is the focus on academic literature, which may not fully capture the latest industry practices and innovations in this rapidly evolving field. The authors acknowledge this and suggest that future research could also explore grey literature and industry publications to gain a more holistic understanding of the state of the art.
Additionally, while the paper covers a wide range of CI-related tasks, the depth of the analysis for each task may vary, depending on the availability and quality of the existing research. The authors could have provided more critical discussion on the limitations and potential biases of the reviewed studies, as well as the generalizability of their findings.
Despite these minor limitations, the paper serves as a valuable resource for researchers and practitioners interested in understanding the current landscape of learning-based approaches in Continuous Integration. The review highlights promising directions for future work and can help guide the development of more advanced and efficient CI systems.
Conclusion
This systematic literature review provides a comprehensive overview of the application of learning-based approaches in Continuous Integration (CI) pipelines. The authors have examined how machine learning, deep learning, and other data-driven techniques are being used to enhance various aspects of CI, including build automation, test case generation, anomaly detection, and overall pipeline optimization.
The review highlights the potential for learning-based approaches to improve the efficiency, reliability, and scalability of CI processes, which are crucial for modern software development workflows. By synthesizing the existing research in this area, the paper identifies emerging trends, challenges, and opportunities for future work, which can inform the development of more advanced and intelligent CI systems.
Overall, this review serves as a valuable resource for researchers and practitioners interested in exploring the intersection of machine learning and Continuous Integration, and it paves the way for further advancements in this important field of software engineering.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🗣️
A Systematic Literature Review on the Use of Machine Learning in Software Engineering
Nyaga Fred, I. O. Temkin
0
0
Software engineering (SE) is a dynamic field that involves multiple phases all of which are necessary to develop sustainable software systems. Machine learning (ML), a branch of artificial intelligence (AI), has drawn a lot of attention in recent years thanks to its ability to analyze massive volumes of data and extract useful patterns from data. Several studies have focused on examining, categorising, and assessing the application of ML in SE processes. We conducted a literature review on primary studies to address this gap. The study was carried out following the objective and the research questions to explore the current state of the art in applying machine learning techniques in software engineering processes. The review identifies the key areas within software engineering where ML has been applied, including software quality assurance, software maintenance, software comprehension, and software documentation. It also highlights the specific ML techniques that have been leveraged in these domains, such as supervised learning, unsupervised learning, and deep learning. Keywords: machine learning, deep learning, software engineering, natural language processing, source code
6/21/2024
Automating Research Synthesis with Domain-Specific Large Language Model Fine-Tuning
Teo Susnjak, Peter Hwang, Napoleon H. Reyes, Andre L. C. Barczak, Timothy R. McIntosh, Surangika Ranathunga
0
0
This research pioneers the use of fine-tuned Large Language Models (LLMs) to automate Systematic Literature Reviews (SLRs), presenting a significant and novel contribution in integrating AI to enhance academic research methodologies. Our study employed the latest fine-tuning methodologies together with open-sourced LLMs, and demonstrated a practical and efficient approach to automating the final execution stages of an SLR process that involves knowledge synthesis. The results maintained high fidelity in factual accuracy in LLM responses, and were validated through the replication of an existing PRISMA-conforming SLR. Our research proposed solutions for mitigating LLM hallucination and proposed mechanisms for tracking LLM responses to their sources of information, thus demonstrating how this approach can meet the rigorous demands of scholarly research. The findings ultimately confirmed the potential of fine-tuned LLMs in streamlining various labor-intensive processes of conducting literature reviews. Given the potential of this approach and its applicability across all research domains, this foundational study also advocated for updating PRISMA reporting guidelines to incorporate AI-driven processes, ensuring methodological transparency and reliability in future SLRs. This study broadens the appeal of AI-enhanced tools across various academic and research fields, setting a new standard for conducting comprehensive and accurate literature reviews with more efficiency in the face of ever-increasing volumes of academic studies.
4/16/2024
🐍
SyROCCo: Enhancing Systematic Reviews using Machine Learning
Zheng Fang, Miguel Arana-Catania, Felix-Anselm van Lier, Juliana Outes Velarde, Harry Bregazzi, Mara Airoldi, Eleanor Carter, Rob Procter
0
0
The sheer number of research outputs published every year makes systematic reviewing increasingly time- and resource-intensive. This paper explores the use of machine learning techniques to help navigate the systematic review process. ML has previously been used to reliably 'screen' articles for review - that is, identify relevant articles based on reviewers' inclusion criteria. The application of ML techniques to subsequent stages of a review, however, such as data extraction and evidence mapping, is in its infancy. We therefore set out to develop a series of tools that would assist in the profiling and analysis of 1,952 publications on the theme of 'outcomes-based contracting'. Tools were developed for the following tasks: assign publications into 'policy area' categories; identify and extract key information for evidence mapping, such as organisations, laws, and geographical information; connect the evidence base to an existing dataset on the same topic; and identify subgroups of articles that may share thematic content. An interactive tool using these techniques and a public dataset with their outputs have been released. Our results demonstrate the utility of ML techniques to enhance evidence accessibility and analysis within the systematic review processes. These efforts show promise in potentially yielding substantial efficiencies for future systematic reviewing and for broadening their analytical scope. Our work suggests that there may be implications for the ease with which policymakers and practitioners can access evidence. While ML techniques seem poised to play a significant role in bridging the gap between research and policy by offering innovative ways of gathering, accessing, and analysing data from systematic reviews, we also highlight their current limitations and the need to exercise caution in their application, particularly given the potential for errors and biases.
6/26/2024
Data Cleaning and Machine Learning: A Systematic Literature Review
Pierre-Olivier C^ot'e, Amin Nikanjam, Nafisa Ahmed, Dmytro Humeniuk, Foutse Khomh
0
0
Context: Machine Learning (ML) is integrated into a growing number of systems for various applications. Because the performance of an ML model is highly dependent on the quality of the data it has been trained on, there is a growing interest in approaches to detect and repair data errors (i.e., data cleaning). Researchers are also exploring how ML can be used for data cleaning; hence creating a dual relationship between ML and data cleaning. To the best of our knowledge, there is no study that comprehensively reviews this relationship. Objective: This paper's objectives are twofold. First, it aims to summarize the latest approaches for data cleaning for ML and ML for data cleaning. Second, it provides future work recommendations. Method: We conduct a systematic literature review of the papers published between 2016 and 2022 inclusively. We identify different types of data cleaning activities with and for ML: feature cleaning, label cleaning, entity matching, outlier detection, imputation, and holistic data cleaning. Results: We summarize the content of 101 papers covering various data cleaning activities and provide 24 future work recommendations. Our review highlights many promising data cleaning techniques that can be further extended. Conclusion: We believe that our review of the literature will help the community develop better approaches to clean data.
6/3/2024