Developing an efficient corpus using Ensemble Data cleaning approach
2406.00789
0
0
📊
Abstract
Despite the observable benefit of Natural Language Processing (NLP) in processing a large amount of textual medical data within a limited time for information retrieval, a handful of research efforts have been devoted to uncovering novel data-cleaning methods. Data cleaning in NLP is at the centre point for extracting validated information. Another observed limitation in the NLP domain is having limited medical corpora that provide answers to a given medical question. Realising the limitations and challenges from two perspectives, this research aims to clean a medical dataset using ensemble techniques and to develop a corpus. The corpora expect that it will answer the question based on the semantic relationship of corpus sequences. However, the data cleaning method in this research suggests that the ensemble technique provides the highest accuracy (94%) compared to the single process, which includes vectorisation, exploratory data analysis, and feeding the vectorised data. The second aim of having an adequate corpus was realised by extracting answers from the dataset. This research is significant in machine learning, specifically data cleaning and the medical sector, but it also underscores the importance of NLP in the medical field, where accurate and timely information extraction can be a matter of life and death. It establishes text data processing using NLP as a powerful tool for extracting valuable information like image data.
Create account to get full access
Overview
- Natural Language Processing (NLP) can help process large amounts of medical text data quickly, but research on novel data-cleaning methods is limited.
- There is also a lack of comprehensive medical corpora (collections of text) that can provide answers to specific medical questions.
- This research aims to clean a medical dataset using ensemble techniques (combining multiple methods) and develop a corpus that can answer medical questions based on the semantic (meaning) relationships in the text.
Plain English Explanation
Despite the clear benefits of Natural Language Processing (NLP) in quickly processing large volumes of medical text data, there has been relatively little research into new and improved methods for cleaning that data. Data cleaning is a crucial step in NLP, as it helps ensure the information extracted is accurate and reliable.
Another limitation in the NLP field is the lack of comprehensive medical text corpora (collections) that can provide answers to specific medical questions. Corpora with strong semantic (meaning-based) relationships between the text sequences could be extremely valuable for the medical community.
Recognizing these challenges, this research had two main goals: 1) to clean a medical dataset using a combination of data processing techniques, and 2) to develop a corpus of medical text that can answer questions based on the semantic relationships in the data.
The results showed that the ensemble (combined) data cleaning approach provided the highest accuracy, at 94%, compared to single data processing methods. And the team was able to extract relevant answers from the dataset to build a useful medical text corpus.
This research is significant for both machine learning and the medical field. Improving data cleaning and building effective medical text corpora are important steps in leveraging the power of NLP to extract critical information from large volumes of medical text data, which could ultimately save lives.
Technical Explanation
The researchers used an ensemble approach, combining multiple data cleaning techniques, to process a medical dataset. This included vectorization (converting text to numerical format), exploratory data analysis, and feeding the vectorized data into the ensemble model.
The ensemble method outperformed single data cleaning processes, achieving an accuracy of 94%. This suggests that the combination of techniques was more effective at identifying and addressing data quality issues compared to using individual methods in isolation.
Additionally, the team was able to extract relevant answers from the cleaned dataset, allowing them to develop a medical text corpus with strong semantic relationships between the sequences of text. This corpus can be used to answer specific medical questions, filling a gap in the available NLP resources for the healthcare domain.
The research highlights the importance of robust data cleaning in NLP applications, particularly for sensitive domains like healthcare where information accuracy is critical. It also underscores the value of building specialized text corpora to support targeted question-answering in medical contexts.
Critical Analysis
While the ensemble data cleaning approach demonstrated strong performance, the paper does not provide details on the specific techniques used or how they were combined. Further information on the ensemble model architecture and training process would be helpful to assess the generalizability and potential limitations of the method.
Additionally, the research only focused on a single medical dataset, so the effectiveness of the ensemble cleaning approach on other healthcare-related text data is unclear. Evaluating the method on a broader range of medical corpora would help strengthen the conclusions and identify any dataset-specific biases or challenges.
The development of the medical text corpus is a promising step, but the paper does not discuss the corpus's quality, coverage, or how it compares to other available resources. Providing more details on the corpus composition, entity recognition, and ability to answer different types of medical queries would give readers a better understanding of its practical utility.
Overall, this research makes valuable contributions to improving data cleaning and building specialized text corpora for NLP applications in healthcare. However, further details and broader evaluation would help solidify the conclusions and provide clearer guidance for future work in this important area.
Conclusion
This research tackles two key challenges in the field of Natural Language Processing (NLP) for the medical domain: data cleaning and the development of comprehensive medical text corpora.
The findings demonstrate that an ensemble of data cleaning techniques can outperform single-method approaches, achieving high accuracy in processing a medical dataset. This is a significant step in ensuring the reliability of information extracted from large volumes of healthcare-related text data using NLP.
Furthermore, the researchers were able to leverage the cleaned dataset to create a medical text corpus with strong semantic relationships between the sequences of text. This corpus can be used to answer specific medical questions, filling a critical gap in the available NLP resources for the healthcare industry.
The implications of this research are far-reaching, as accurate and timely information extraction through NLP can be a matter of life and death in the medical field. By improving data cleaning and building specialized text corpora, this work establishes NLP as a powerful tool for unlocking valuable insights from the vast troves of medical text data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Mathematical Entities: Corpora and Benchmarks
Jacob Collard, Valeria de Paiva, Eswaran Subrahmanian
0
0
Mathematics is a highly specialized domain with its own unique set of challenges. Despite this, there has been relatively little research on natural language processing for mathematical texts, and there are few mathematical language resources aimed at NLP. In this paper, we aim to provide annotated corpora that can be used to study the language of mathematics in different contexts, ranging from fundamental concepts found in textbooks to advanced research mathematics. We preprocess the corpora with a neural parsing model and some manual intervention to provide part-of-speech tags, lemmas, and dependency trees. In total, we provide 182397 sentences across three corpora. We then aim to test and evaluate several noteworthy natural language processing models using these corpora, to show how well they can adapt to the domain of mathematics and provide useful tools for exploring mathematical language. We evaluate several neural and symbolic models against benchmarks that we extract from the corpus metadata to show that terminology extraction and definition extraction do not easily generalize to mathematics, and that additional work is needed to achieve good performance on these metrics. Finally, we provide a learning assistant that grants access to the content of these corpora in a context-sensitive manner, utilizing text search and entity linking. Though our corpora and benchmarks provide useful metrics for evaluating mathematical language processing, further work is necessary to adapt models to mathematics in order to provide more effective learning assistants and apply NLP methods to different mathematical domains.
6/18/2024
A Sentiment Analysis of Medical Text Based on Deep Learning
Yinan Chen
0
0
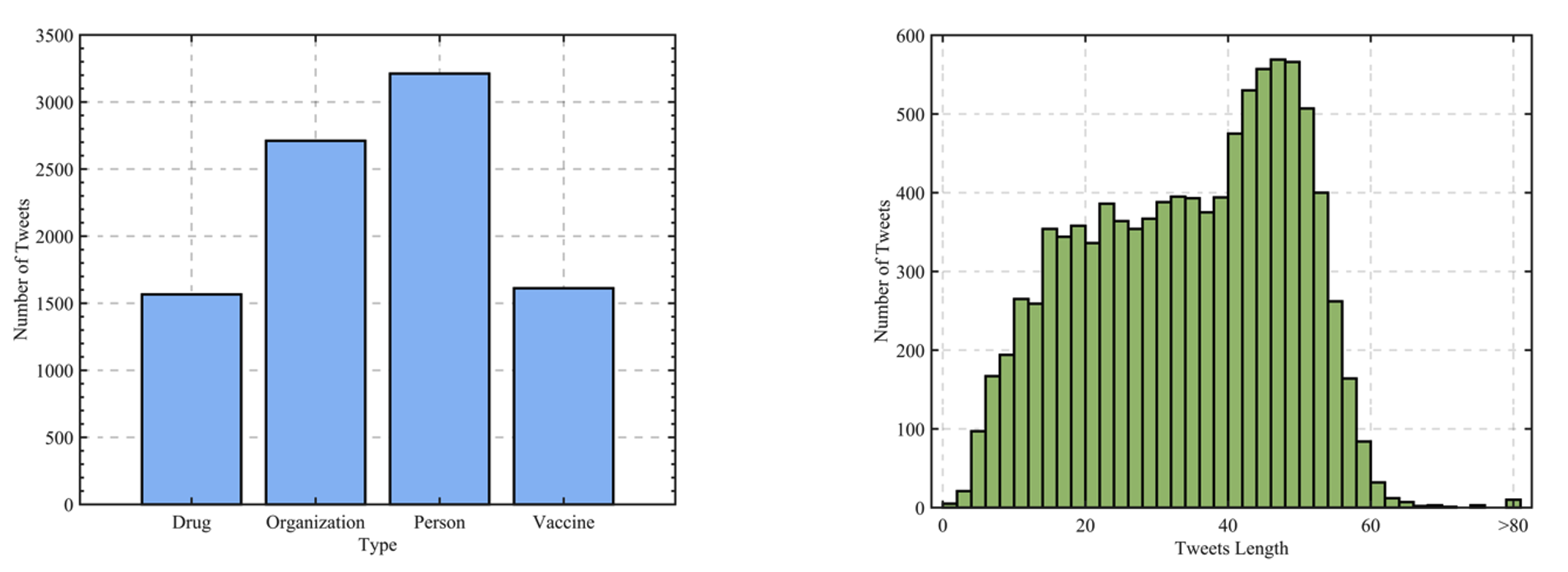
The field of natural language processing (NLP) has made significant progress with the rapid development of deep learning technologies. One of the research directions in text sentiment analysis is sentiment analysis of medical texts, which holds great potential for application in clinical diagnosis. However, the medical field currently lacks sufficient text datasets, and the effectiveness of sentiment analysis is greatly impacted by different model design approaches, which presents challenges. Therefore, this paper focuses on the medical domain, using bidirectional encoder representations from transformers (BERT) as the basic pre-trained model and experimenting with modules such as convolutional neural network (CNN), fully connected network (FCN), and graph convolutional networks (GCN) at the output layer. Experiments and analyses were conducted on the METS-CoV dataset to explore the training performance after integrating different deep learning networks. The results indicate that CNN models outperform other networks when trained on smaller medical text datasets in combination with pre-trained models like BERT. This study highlights the significance of model selection in achieving effective sentiment analysis in the medical domain and provides a reference for future research to develop more efficient model architectures.
4/17/2024
Computational Job Market Analysis with Natural Language Processing
Mike Zhang
0
0
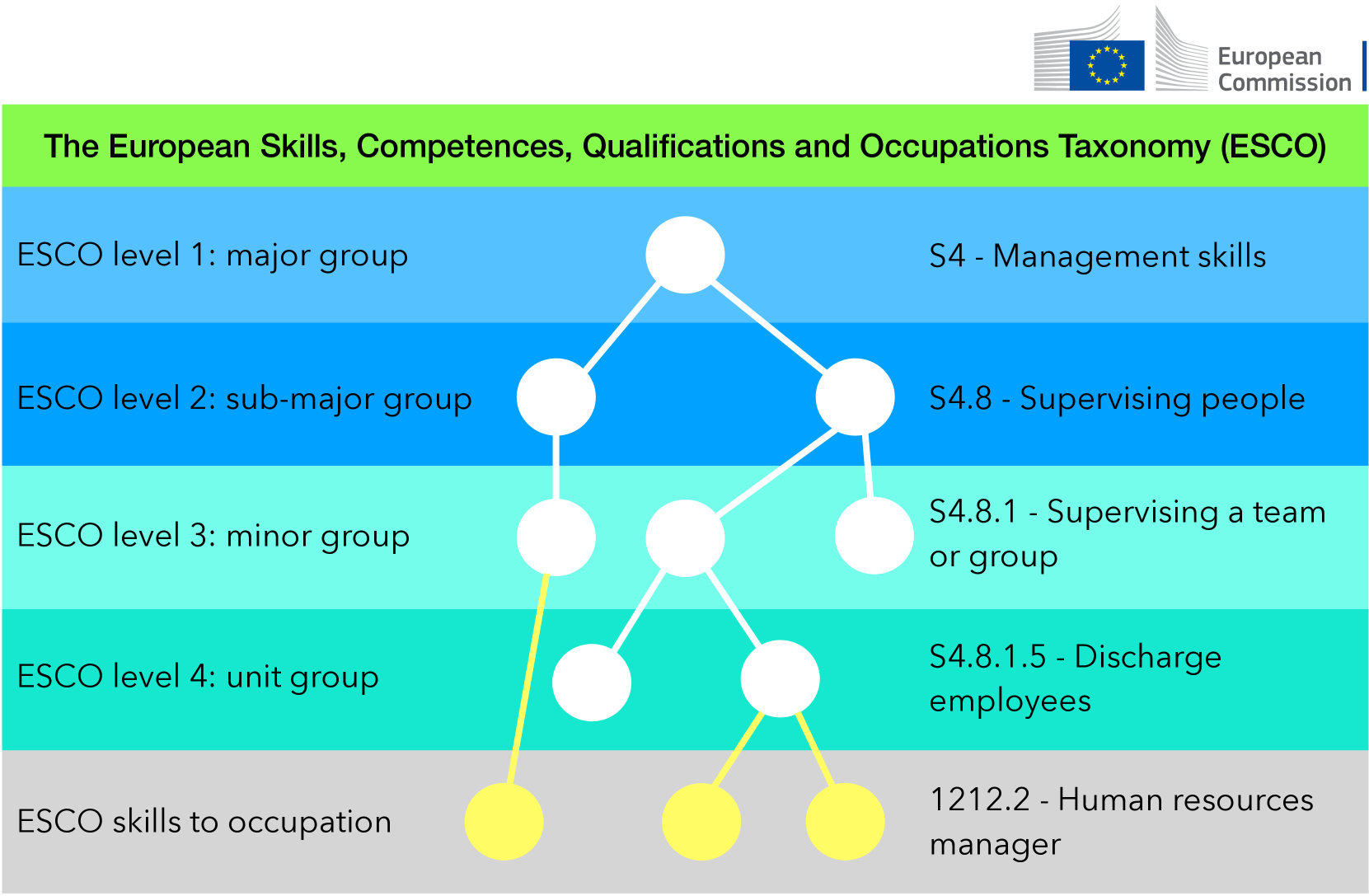
[Abridged Abstract] Recent technological advances underscore labor market dynamics, yielding significant consequences for employment prospects and increasing job vacancy data across platforms and languages. Aggregating such data holds potential for valuable insights into labor market demands, new skills emergence, and facilitating job matching for various stakeholders. However, despite prevalent insights in the private sector, transparent language technology systems and data for this domain are lacking. This thesis investigates Natural Language Processing (NLP) technology for extracting relevant information from job descriptions, identifying challenges including scarcity of training data, lack of standardized annotation guidelines, and shortage of effective extraction methods from job ads. We frame the problem, obtaining annotated data, and introducing extraction methodologies. Our contributions include job description datasets, a de-identification dataset, and a novel active learning algorithm for efficient model training. We propose skill extraction using weak supervision, a taxonomy-aware pre-training methodology adapting multilingual language models to the job market domain, and a retrieval-augmented model leveraging multiple skill extraction datasets to enhance overall performance. Finally, we ground extracted information within a designated taxonomy.
5/1/2024
Multi-News+: Cost-efficient Dataset Cleansing via LLM-based Data Annotation
Juhwan Choi, Jungmin Yun, Kyohoon Jin, YoungBin Kim
0
0
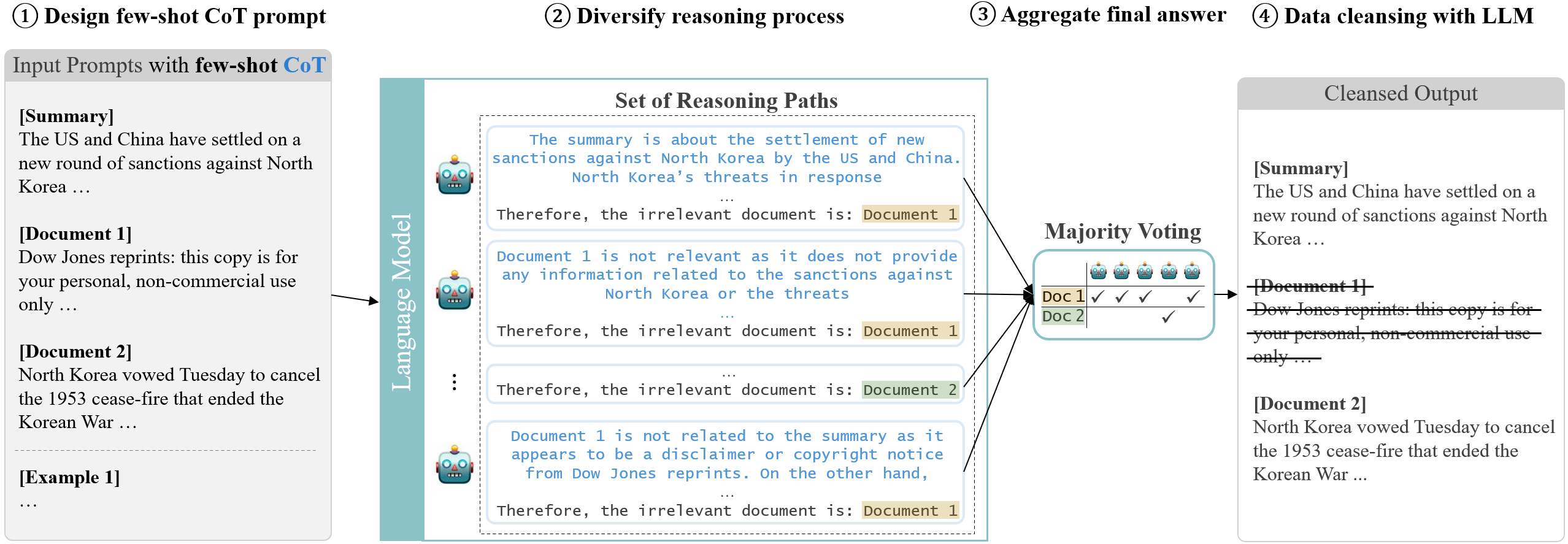
The quality of the dataset is crucial for ensuring optimal performance and reliability of downstream task models. However, datasets often contain noisy data inadvertently included during the construction process. Numerous attempts have been made to correct this issue through human annotators. However, hiring and managing human annotators is expensive and time-consuming. As an alternative, recent studies are exploring the use of large language models (LLMs) for data annotation. In this study, we present a case study that extends the application of LLM-based data annotation to enhance the quality of existing datasets through a cleansing strategy. Specifically, we leverage approaches such as chain-of-thought (CoT) and majority voting to imitate human annotation and classify unrelated documents from the Multi-News dataset, which is widely used for the multi-document summarization task. Through our proposed cleansing method, we introduce an enhanced Multi-News+. By employing LLMs for data cleansing, we demonstrate an efficient and effective approach to improving dataset quality without relying on expensive human annotation efforts.
4/16/2024