Data-dependent Generalization Bounds via Variable-Size Compressibility
2303.05369
0
0
🐍
Abstract
In this paper, we establish novel data-dependent upper bounds on the generalization error through the lens of a variable-size compressibility framework that we introduce newly here. In this framework, the generalization error of an algorithm is linked to a variable-size 'compression rate' of its input data. This is shown to yield bounds that depend on the empirical measure of the given input data at hand, rather than its unknown distribution. Our new generalization bounds that we establish are tail bounds, tail bounds on the expectation, and in-expectations bounds. Moreover, it is shown that our framework also allows to derive general bounds on any function of the input data and output hypothesis random variables. In particular, these general bounds are shown to subsume and possibly improve over several existing PAC-Bayes and data-dependent intrinsic dimension-based bounds that are recovered as special cases, thus unveiling a unifying character of our approach. For instance, a new data-dependent intrinsic dimension-based bound is established, which connects the generalization error to the optimization trajectories and reveals various interesting connections with the rate-distortion dimension of a process, the R'enyi information dimension of a process, and the metric mean dimension.
Create account to get full access
Overview
- The paper introduces a new "variable-size compressibility" framework for analyzing the generalization error of machine learning algorithms.
- This framework links the generalization error to a "compression rate" of the input data, rather than its unknown distribution.
- The paper establishes several types of generalization bounds within this framework, including tail bounds, tail bounds on the expectation, and in-expectation bounds.
- The framework also allows for deriving general bounds on functions of the input data and output hypothesis.
- These general bounds are shown to subsume and potentially improve upon several existing PAC-Bayes and data-dependent intrinsic dimension-based bounds.
Plain English Explanation
The paper introduces a new way to understand how well machine learning algorithms will perform on new, unseen data. Typically, this "generalization error" is hard to predict because it depends on the unknown distribution of the data.
However, this paper proposes a new framework that links the generalization error to how "compressible" the input data is. The idea is that if the data can be compressed a lot, then the algorithm doesn't need to learn as much, and the generalization error will be lower.
Within this framework, the paper establishes several different types of bounds on the generalization error. These bounds depend on the particular input data at hand, rather than its unknown underlying distribution. This is a key advantage, as it makes the bounds more practical to use.
Additionally, the paper shows that this framework can be used to derive general bounds on any function of the input data and output hypothesis. These general bounds turn out to subsume and potentially improve upon several existing types of bounds, like PAC-Bayes bounds and data-dependent intrinsic dimension-based bounds. This suggests that the new framework provides a unifying perspective on generalization bounds.
Technical Explanation
The paper introduces a "variable-size compressibility" framework for analyzing the generalization error of machine learning algorithms. In this framework, the generalization error is linked to a "compression rate" of the input data, rather than its unknown distribution.
Specifically, the paper establishes three types of generalization bounds within this framework:
- Tail bounds on the generalization error
- Tail bounds on the expectation of the generalization error
- In-expectation bounds on the generalization error
Moreover, the paper shows that the framework can be used to derive general bounds on any function of the input data and output hypothesis random variables. These general bounds are proven to subsume and potentially improve upon several existing PAC-Bayes and data-dependent intrinsic dimension-based bounds.
As a specific example, the paper establishes a new data-dependent intrinsic dimension-based bound. This bound connects the generalization error to the optimization trajectories and reveals connections with the rate-distortion dimension, Rényi information dimension, and metric mean dimension of the data-generating process.
Critical Analysis
The paper introduces a novel and promising framework for analyzing generalization in machine learning. The key advantage of the variable-size compressibility approach is that it provides bounds that depend on the empirical properties of the given input data, rather than its unknown underlying distribution.
However, the paper does not provide much intuition or practical guidance on how to actually compute the relevant compression rates or intrinsic dimensions for real-world datasets and algorithms. Doing so may require significant technical expertise and additional research.
Additionally, while the paper shows that the new bounds subsume or improve upon several existing approaches, it does not provide a comprehensive comparison to the state-of-the-art in generalization bounds. Further empirical validation on a wider range of benchmarks would help assess the practical usefulness of the proposed framework.
Finally, the paper focuses solely on the theoretical analysis of generalization error, without considering other important practical aspects of machine learning, such as computational complexity, robustness, or fairness. Integrating the variable-size compressibility framework with these other desiderata could lead to a more holistic understanding of effective machine learning.
Conclusion
This paper introduces a novel "variable-size compressibility" framework for analyzing the generalization error of machine learning algorithms. By linking the generalization error to a "compression rate" of the input data, rather than its unknown distribution, the framework provides a new perspective on deriving practical generalization bounds.
The paper establishes several types of bounds within this framework, including tail bounds, tail bounds on the expectation, and in-expectation bounds. Importantly, the framework also allows for deriving general bounds on any function of the input data and output hypothesis, which subsume and potentially improve upon several existing approaches.
While the technical details of the framework may be challenging, the core idea of using data compressibility as a proxy for generalization is an intriguing one. Further research is needed to make the framework more accessible and to validate its practical utility across a range of machine learning tasks and datasets. Nonetheless, this paper represents an important step towards a more data-centric understanding of generalization in machine learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔄
Uniform Generalization Bounds on Data-Dependent Hypothesis Sets via PAC-Bayesian Theory on Random Sets
Benjamin Dupuis, Paul Viallard, George Deligiannidis, Umut Simsekli
0
0
We propose data-dependent uniform generalization bounds by approaching the problem from a PAC-Bayesian perspective. We first apply the PAC-Bayesian framework on `random sets' in a rigorous way, where the training algorithm is assumed to output a data-dependent hypothesis set after observing the training data. This approach allows us to prove data-dependent bounds, which can be applicable in numerous contexts. To highlight the power of our approach, we consider two main applications. First, we propose a PAC-Bayesian formulation of the recently developed fractal-dimension-based generalization bounds. The derived results are shown to be tighter and they unify the existing results around one simple proof technique. Second, we prove uniform bounds over the trajectories of continuous Langevin dynamics and stochastic gradient Langevin dynamics. These results provide novel information about the generalization properties of noisy algorithms.
4/29/2024
📊
Generalization Bounds for Dependent Data using Online-to-Batch Conversion
Sagnik Chatterjee, Manuj Mukherjee, Alhad Sethi
0
0
In this work, we give generalization bounds of statistical learning algorithms trained on samples drawn from a dependent data source, both in expectation and with high probability, using the Online-to-Batch conversion paradigm. We show that the generalization error of statistical learners in the dependent data setting is equivalent to the generalization error of statistical learners in the i.i.d. setting up to a term that depends on the decay rate of the underlying mixing stochastic process and is independent of the complexity of the statistical learner. Our proof techniques involve defining a new notion of stability of online learning algorithms based on Wasserstein distances and employing near-martingale concentration bounds for dependent random variables to arrive at appropriate upper bounds for the generalization error of statistical learners trained on dependent data.
5/24/2024
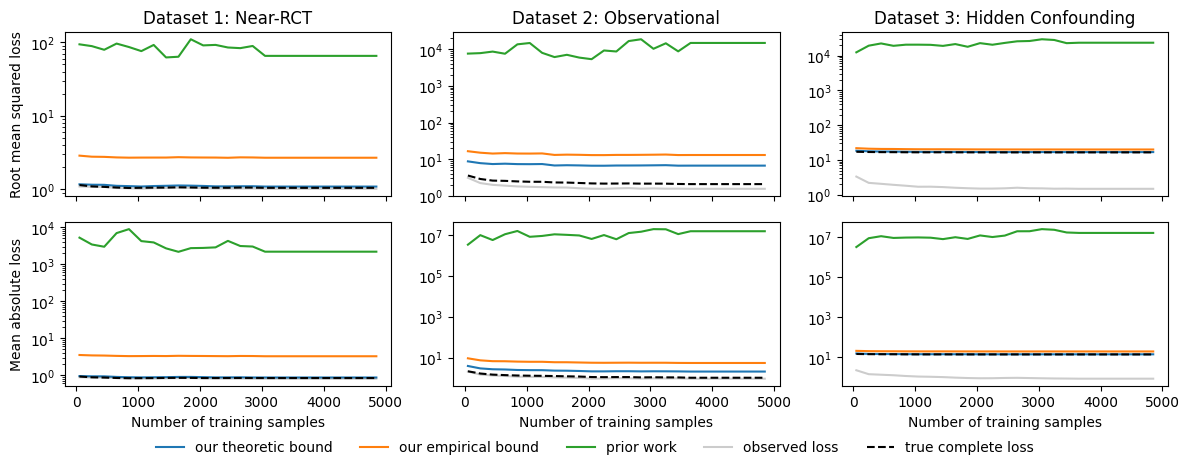
Generalization Bounds for Causal Regression: Insights, Guarantees and Sensitivity Analysis
Daniel Csillag, Claudio Jos'e Struchiner, Guilherme Tegoni Goedert
0
0
Many algorithms have been recently proposed for causal machine learning. Yet, there is little to no theory on their quality, especially considering finite samples. In this work, we propose a theory based on generalization bounds that provides such guarantees. By introducing a novel change-of-measure inequality, we are able to tightly bound the model loss in terms of the deviation of the treatment propensities over the population, which we show can be empirically limited. Our theory is fully rigorous and holds even in the face of hidden confounding and violations of positivity. We demonstrate our bounds on semi-synthetic and real data, showcasing their remarkable tightness and practical utility.
5/16/2024

Slicing Mutual Information Generalization Bounds for Neural Networks
Kimia Nadjahi, Kristjan Greenewald, Rickard Bruel Gabrielsson, Justin Solomon
0
0
The ability of machine learning (ML) algorithms to generalize well to unseen data has been studied through the lens of information theory, by bounding the generalization error with the input-output mutual information (MI), i.e., the MI between the training data and the learned hypothesis. Yet, these bounds have limited practicality for modern ML applications (e.g., deep learning), due to the difficulty of evaluating MI in high dimensions. Motivated by recent findings on the compressibility of neural networks, we consider algorithms that operate by slicing the parameter space, i.e., trained on random lower-dimensional subspaces. We introduce new, tighter information-theoretic generalization bounds tailored for such algorithms, demonstrating that slicing improves generalization. Our bounds offer significant computational and statistical advantages over standard MI bounds, as they rely on scalable alternative measures of dependence, i.e., disintegrated mutual information and $k$-sliced mutual information. Then, we extend our analysis to algorithms whose parameters do not need to exactly lie on random subspaces, by leveraging rate-distortion theory. This strategy yields generalization bounds that incorporate a distortion term measuring model compressibility under slicing, thereby tightening existing bounds without compromising performance or requiring model compression. Building on this, we propose a regularization scheme enabling practitioners to control generalization through compressibility. Finally, we empirically validate our results and achieve the computation of non-vacuous information-theoretic generalization bounds for neural networks, a task that was previously out of reach.
6/7/2024