Data-Driven Knowledge Transfer in Batch $Q^*$ Learning

0

Sign in to get full access
Overview
- This paper proposes a novel approach for transferring knowledge between reinforcement learning (RL) agents in a batch setting, where the agents learn from a fixed dataset without further interaction with the environment.
- The key idea is to leverage auxiliary information, such as state representations or dynamics models, to guide the learning of a target agent's action-value function (Q-function) using data from a source agent.
- The authors demonstrate the effectiveness of their method on several benchmark environments, showing improved sample efficiency and performance compared to standard batch RL algorithms.
Plain English Explanation
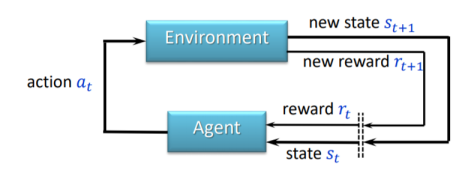
The paper tackles the challenge of how to transfer knowledge between reinforcement learning (RL) agents. In RL, agents learn to make good decisions by interacting with an environment and receiving rewards. However, this can be a slow and inefficient process, especially when starting from scratch.
The key insight in this paper is that we can leverage auxiliary information, such as state representations or dynamics models, to help a target agent learn more effectively from data collected by a source agent. This is particularly useful in a batch setting, where the agents learn from a fixed dataset without further interaction with the environment.
The authors propose a method that transfers knowledge by guiding the target agent's learning of its action-value function (Q-function), which is a crucial component of many RL algorithms. By incorporating the auxiliary information, the target agent can learn more efficiently and achieve better performance compared to standard batch RL methods.
The paper demonstrates the effectiveness of this approach on several benchmark environments, showing improved sample efficiency and overall performance. This is an important contribution to the field of RL, as it can help accelerate the learning process and enable agents to perform better with less data.
Technical Explanation
The paper introduces a novel data-driven knowledge transfer approach for batch Q-learning, where the objective is to learn an optimal action-value function (Q-function) from a fixed dataset without further environment interactions.
The key idea is to leverage auxiliary information, such as state representations or dynamics models, to guide the learning of the target agent's Q-function using data from a source agent. The authors formulate this as a constrained optimization problem, where the target agent's Q-function is learned to minimize the distance to the source agent's Q-function while also satisfying certain constraints related to the auxiliary information.
Specifically, the authors propose two variants of their method:
-
Auxiliary Constrained Q-learning (ACQ): This approach incorporates auxiliary state representations into the learning of the target agent's Q-function by constraining it to match the source agent's Q-function on states with similar representations.
-
Auxiliary Dynamics-Guided Q-learning (ADQ): This variant uses the source agent's dynamics model to inform the target agent's Q-function learning, constraining it to match the source agent's Q-function on states that are likely to be visited under the source agent's policy.
The authors evaluate their methods on several benchmark environments, including classic control tasks and more complex continuous control problems. The results demonstrate that their approaches can significantly improve sample efficiency and performance compared to standard batch Q-learning algorithms, such as fitted Q-iteration and batch-constrained Q-learning.
Critical Analysis
The paper presents a promising approach for transferring knowledge between RL agents in a batch setting. The authors' key insight of leveraging auxiliary information to guide the learning of the target agent's Q-function is well-motivated and appears to be effective in the experiments.
One potential limitation of the approach is the reliance on having access to high-quality auxiliary information, such as state representations or dynamics models. In practice, these may not always be readily available or easy to obtain, which could limit the broader applicability of the method.
Additionally, the paper does not fully address the potential issue of distributional shift between the source and target agents. While the authors mention this concern, they do not provide a comprehensive analysis of how their methods might perform in the presence of significant distribution mismatch between the two agents.
Another area for further research could be the extension of the knowledge transfer approach to more complex settings, such as hierarchical or multi-task RL problems. It would be interesting to see how the proposed methods could be adapted to leverage cross-task or cross-agent knowledge in these more challenging scenarios.
Overall, the paper presents a promising contribution to the field of batch reinforcement learning and knowledge transfer, and the authors' experiments demonstrate the potential benefits of their approach. However, addressing the limitations mentioned above could further strengthen the impact and practical applicability of the proposed techniques.
Conclusion
This paper introduces a novel data-driven knowledge transfer approach for batch Q-learning, which leverages auxiliary information to guide the learning of a target agent's action-value function using data from a source agent. The authors demonstrate the effectiveness of their methods, Auxiliary Constrained Q-learning (ACQ) and Auxiliary Dynamics-Guided Q-learning (ADQ), on several benchmark environments, showing improved sample efficiency and performance compared to standard batch RL algorithms.
The key contribution of this work is the insight that auxiliary information, such as state representations or dynamics models, can be used to effectively transfer knowledge between RL agents in a batch setting, where the agents learn from a fixed dataset without further environment interactions. This is an important advancement in the field of reinforcement learning, as it can help accelerate the learning process and enable agents to achieve better performance with less data.
While the paper presents promising results, further research is needed to address potential limitations, such as the reliance on high-quality auxiliary information and the potential impact of distributional shift between source and target agents. Exploring the extension of the knowledge transfer approach to more complex RL settings, such as hierarchical or multi-task problems, could also be a fruitful area for future work.
Overall, this paper makes a valuable contribution to the growing body of research on knowledge transfer in reinforcement learning, offering a novel and effective solution for improving the sample efficiency and performance of batch RL agents.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Data-Driven Knowledge Transfer in Batch $Q^*$ Learning
Elynn Chen, Xi Chen, Wenbo Jing
In data-driven decision-making in marketing, healthcare, and education, it is desirable to utilize a large amount of data from existing ventures to navigate high-dimensional feature spaces and address data scarcity in new ventures. We explore knowledge transfer in dynamic decision-making by concentrating on batch stationary environments and formally defining task discrepancies through the lens of Markov decision processes (MDPs). We propose a framework of Transferred Fitted $Q$-Iteration algorithm with general function approximation, enabling the direct estimation of the optimal action-state function $Q^*$ using both target and source data. We establish the relationship between statistical performance and MDP task discrepancy under sieve approximation, shedding light on the impact of source and target sample sizes and task discrepancy on the effectiveness of knowledge transfer. We show that the final learning error of the $Q^*$ function is significantly improved from the single task rate both theoretically and empirically.
Read more4/24/2024
0
Exploration in Knowledge Transfer Utilizing Reinforcement Learning
Adam Jedliv{c}ka, Tatiana Valentine Guy
The contribution focuses on the problem of exploration within the task of knowledge transfer. Knowledge transfer refers to the useful application of the knowledge gained while learning the source task in the target task. The intended benefit of knowledge transfer is to speed up the learning process of the target task. The article aims to compare several exploration methods used within a deep transfer learning algorithm, particularly Deep Target Transfer $Q$-learning. The methods used are $epsilon$-greedy, Boltzmann, and upper confidence bound exploration. The aforementioned transfer learning algorithms and exploration methods were tested on the virtual drone problem. The results have shown that the upper confidence bound algorithm performs the best out of these options. Its sustainability to other applications is to be checked.
Read more7/16/2024

0
Uncertainty-aware transfer across tasks using hybrid model-based successor feature reinforcement learning
Parvin Malekzadeh, Ming Hou, Konstantinos N. Plataniotis
Sample efficiency is central to developing practical reinforcement learning (RL) for complex and large-scale decision-making problems. The ability to transfer and generalize knowledge gained from previous experiences to downstream tasks can significantly improve sample efficiency. Recent research indicates that successor feature (SF) RL algorithms enable knowledge generalization between tasks with different rewards but identical transition dynamics. It has recently been hypothesized that combining model-based (MB) methods with SF algorithms can alleviate the limitation of fixed transition dynamics. Furthermore, uncertainty-aware exploration is widely recognized as another appealing approach for improving sample efficiency. Putting together two ideas of hybrid model-based successor feature (MB-SF) and uncertainty leads to an approach to the problem of sample efficient uncertainty-aware knowledge transfer across tasks with different transition dynamics or/and reward functions. In this paper, the uncertainty of the value of each action is approximated by a Kalman filter (KF)-based multiple-model adaptive estimation. This KF-based framework treats the parameters of a model as random variables. To the best of our knowledge, this is the first attempt at formulating a hybrid MB-SF algorithm capable of generalizing knowledge across large or continuous state space tasks with various transition dynamics while requiring less computation at decision time than MB methods. The number of samples required to learn the tasks was compared to recent SF and MB baselines. The results show that our algorithm generalizes its knowledge across different transition dynamics, learns downstream tasks with significantly fewer samples than starting from scratch, and outperforms existing approaches.
Read more7/23/2024
🔄
0
Robust Knowledge Transfer in Tiered Reinforcement Learning
Jiawei Huang, Niao He
In this paper, we study the Tiered Reinforcement Learning setting, a parallel transfer learning framework, where the goal is to transfer knowledge from the low-tier (source) task to the high-tier (target) task to reduce the exploration risk of the latter while solving the two tasks in parallel. Unlike previous work, we do not assume the low-tier and high-tier tasks share the same dynamics or reward functions, and focus on robust knowledge transfer without prior knowledge on the task similarity. We identify a natural and necessary condition called the ``Optimal Value Dominance'' for our objective. Under this condition, we propose novel online learning algorithms such that, for the high-tier task, it can achieve constant regret on partial states depending on the task similarity and retain near-optimal regret when the two tasks are dissimilar, while for the low-tier task, it can keep near-optimal without making sacrifice. Moreover, we further study the setting with multiple low-tier tasks, and propose a novel transfer source selection mechanism, which can ensemble the information from all low-tier tasks and allow provable benefits on a much larger state-action space.
Read more6/14/2024