Data-Efficient 3D Visual Grounding via Order-Aware Referring
2403.16539
0
0
Abstract
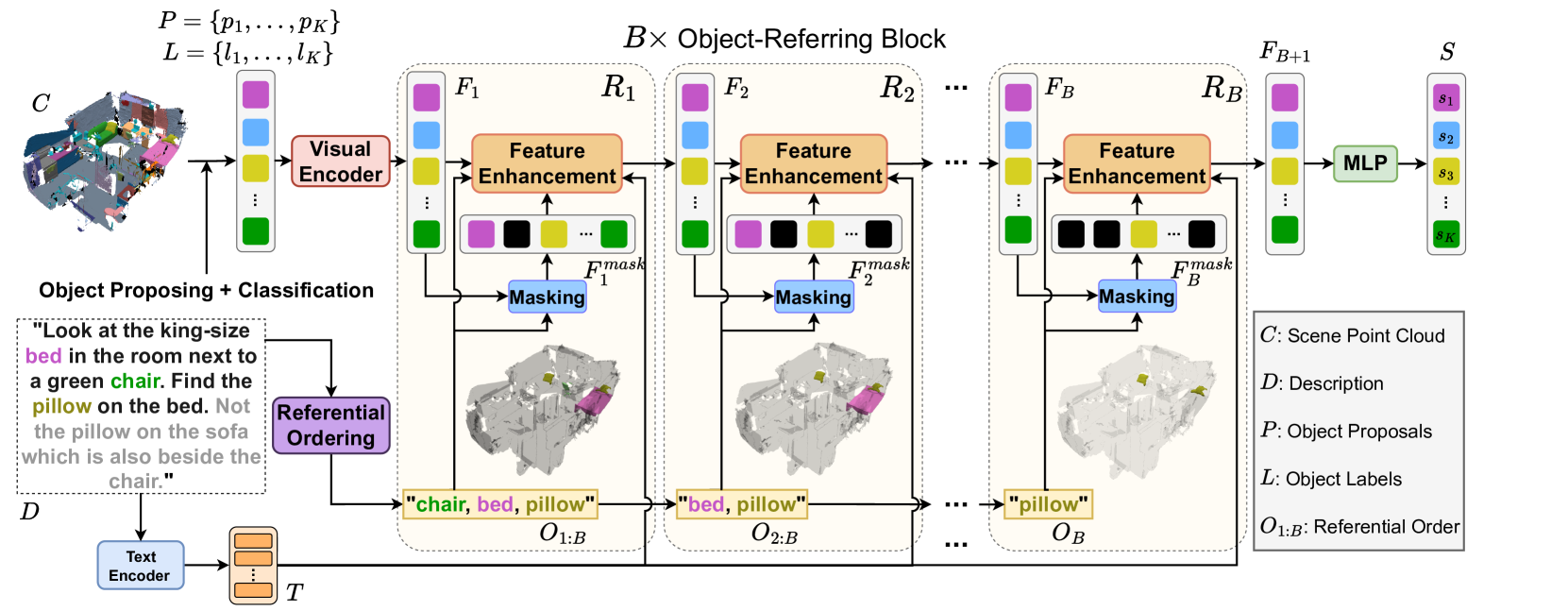
3D visual grounding aims to identify the target object within a 3D point cloud scene referred to by a natural language description. Previous works usually require significant data relating to point color and their descriptions to exploit the corresponding complicated verbo-visual relations. In our work, we introduce Vigor, a novel Data-Efficient 3D Visual Grounding framework via Order-aware Referring. Vigor leverages LLM to produce a desirable referential order from the input description for 3D visual grounding. With the proposed stacked object-referring blocks, the predicted anchor objects in the above order allow one to locate the target object progressively without supervision on the identities of anchor objects or exact relations between anchor/target objects. In addition, we present an order-aware warm-up training strategy, which augments referential orders for pre-training the visual grounding framework. This allows us to better capture the complex verbo-visual relations and benefit the desirable data-efficient learning scheme. Experimental results on the NR3D and ScanRefer datasets demonstrate our superiority in low-resource scenarios. In particular, Vigor surpasses current state-of-the-art frameworks by 9.3% and 7.6% grounding accuracy under 1% data and 10% data settings on the NR3D dataset, respectively.
Create account to get full access
Overview
- Introduces a novel 3D visual grounding approach called DOrA that leverages order-aware referring expressions
- Proposes a two-stage model that first grounds the referring expression to the relevant object in the scene, then refines the localization of the object
- Evaluates DOrA on 3D visual grounding benchmarks and shows state-of-the-art performance
Plain English Explanation
The paper presents a new way to help computers understand how people describe 3D objects in an image or scene. This is called "3D visual grounding." The key idea is to use the order of words in the description to better locate the target object.
For example, if someone says "the red cube next to the green sphere," the order of "red cube" and "green sphere" provides important information about their spatial relationship. The new DOrA model takes advantage of this order-aware referring to more accurately pinpoint the object being described.
DOrA works in two steps. First, it figures out which object in the scene the description is referring to. Then it refines the localization of that object, making the bounding box around it more precise. Experiments show this approach outperforms previous 3D visual grounding methods on standard benchmarks.
Technical Explanation
The paper introduces a novel 3D visual grounding approach called DOrA: 3D Visual Grounding with Order-Aware Referring. Rather than treating referring expressions as unordered collections of words, DOrA explicitly models the order of referring terms to better ground them in 3D scenes.
The DOrA model operates in two stages. First, it uses a Transformer-based architecture to ground the full referring expression to the relevant object in the 3D scene. Then, it refines the localization of that object through a second Transformer module that takes into account the order of the referring terms.
Experiments on popular 3D visual grounding benchmarks like COT-3D, Weakly-Supervised 3D Visual Grounding, and Naturally-Supervised 3D Visual Grounding demonstrate that DOrA outperforms previous state-of-the-art approaches. The authors attribute this to the model's ability to effectively leverage the order information in referring expressions.
Critical Analysis
The paper presents a compelling approach to 3D visual grounding that addresses an important limitation of prior work - the failure to fully utilize the structure and ordering of referring expressions. By modeling order-aware referring, DOrA is able to achieve significant performance gains over previous methods.
However, the paper does not explore the limits of this approach. It would be valuable to understand how DOrA behaves on more complex or ambiguous referring expressions, where the order of terms may be less informative. Additionally, the evaluation is limited to existing 3D visual grounding datasets, which may not capture the full diversity of real-world scenarios.
Further research could also investigate the interpretability of the DOrA model - how does it actually use the order information to ground the referring expressions? Providing more insights into the inner workings of the model could lead to even more effective 3D visual grounding approaches in the future.
Conclusion
The DOrA model presented in this paper represents an important advance in 3D visual grounding by leveraging the order of referring terms. By explicitly modeling this structural information, DOrA is able to outperform previous state-of-the-art methods on standard benchmarks.
This work highlights the value of going beyond simple word-level features and instead considering the broader linguistic structure of referring expressions. As 3D computer vision continues to progress, techniques like DOrA that can bridge the gap between language and visual perception will become increasingly crucial.
While the paper leaves some avenues for future work, the core idea of order-aware 3D visual grounding is a significant contribution that could inspire further innovations in this rapidly evolving field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

CoT3DRef: Chain-of-Thoughts Data-Efficient 3D Visual Grounding
Eslam Mohamed Bakr, Mohamed Ayman, Mahmoud Ahmed, Habib Slim, Mohamed Elhoseiny
0
0
3D visual grounding is the ability to localize objects in 3D scenes conditioned by utterances. Most existing methods devote the referring head to localize the referred object directly, causing failure in complex scenarios. In addition, it does not illustrate how and why the network reaches the final decision. In this paper, we address this question Can we design an interpretable 3D visual grounding framework that has the potential to mimic the human perception system?. To this end, we formulate the 3D visual grounding problem as a sequence-to-sequence Seq2Seq task by first predicting a chain of anchors and then the final target. Interpretability not only improves the overall performance but also helps us identify failure cases. Following the chain of thoughts approach enables us to decompose the referring task into interpretable intermediate steps, boosting the performance and making our framework extremely data-efficient. Moreover, our proposed framework can be easily integrated into any existing architecture. We validate our approach through comprehensive experiments on the Nr3D, Sr3D, and Scanrefer benchmarks and show consistent performance gains compared to existing methods without requiring manually annotated data. Furthermore, our proposed framework, dubbed CoT3DRef, is significantly data-efficient, whereas on the Sr3D dataset, when trained only on 10% of the data, we match the SOTA performance that trained on the entire data. The code is available at https:eslambakr.github.io/cot3dref.github.io/.
4/23/2024
📊
Four Ways to Improve Verbo-visual Fusion for Dense 3D Visual Grounding
Ozan Unal, Christos Sakaridis, Suman Saha, Luc Van Gool
0
0
3D visual grounding is the task of localizing the object in a 3D scene which is referred by a description in natural language. With a wide range of applications ranging from autonomous indoor robotics to AR/VR, the task has recently risen in popularity. A common formulation to tackle 3D visual grounding is grounding-by-detection, where localization is done via bounding boxes. However, for real-life applications that require physical interactions, a bounding box insufficiently describes the geometry of an object. We therefore tackle the problem of dense 3D visual grounding, i.e. referral-based 3D instance segmentation. We propose a dense 3D grounding network ConcreteNet, featuring four novel stand-alone modules that aim to improve grounding performance for challenging repetitive instances, i.e. instances with distractors of the same semantic class. First, we introduce a bottom-up attentive fusion module that aims to disambiguate inter-instance relational cues, next, we construct a contrastive training scheme to induce separation in the latent space, we then resolve view-dependent utterances via a learned global camera token, and finally we employ multi-view ensembling to improve referred mask quality. ConcreteNet ranks 1st on the challenging ScanRefer online benchmark and has won the ICCV 3rd Workshop on Language for 3D Scenes 3D Object Localization challenge.
7/4/2024

Weakly-Supervised 3D Visual Grounding based on Visual Linguistic Alignment
Xiaoxu Xu, Yitian Yuan, Qiudan Zhang, Wenhui Wu, Zequn Jie, Lin Ma, Xu Wang
0
0
Learning to ground natural language queries to target objects or regions in 3D point clouds is quite essential for 3D scene understanding. Nevertheless, existing 3D visual grounding approaches require a substantial number of bounding box annotations for text queries, which is time-consuming and labor-intensive to obtain. In this paper, we propose textbf{3D-VLA}, a weakly supervised approach for textbf{3D} visual grounding based on textbf{V}isual textbf{L}inguistic textbf{A}lignment. Our 3D-VLA exploits the superior ability of current large-scale vision-language models (VLMs) on aligning the semantics between texts and 2D images, as well as the naturally existing correspondences between 2D images and 3D point clouds, and thus implicitly constructs correspondences between texts and 3D point clouds with no need for fine-grained box annotations in the training procedure. During the inference stage, the learned text-3D correspondence will help us ground the text queries to the 3D target objects even without 2D images. To the best of our knowledge, this is the first work to investigate 3D visual grounding in a weakly supervised manner by involving large scale vision-language models, and extensive experiments on ReferIt3D and ScanRefer datasets demonstrate that our 3D-VLA achieves comparable and even superior results over the fully supervised methods.
4/16/2024

Empowering 3D Visual Grounding with Reasoning Capabilities
Chenming Zhu, Tai Wang, Wenwei Zhang, Kai Chen, Xihui Liu
0
0
Although great progress has been made in 3D visual grounding, current models still rely on explicit textual descriptions for grounding and lack the ability to reason human intentions from implicit instructions. We propose a new task called 3D reasoning grounding and introduce a new benchmark ScanReason which provides over 10K question-answer-location pairs from five reasoning types that require the synerization of reasoning and grounding. We further design our approach, ReGround3D, composed of the visual-centric reasoning module empowered by Multi-modal Large Language Model (MLLM) and the 3D grounding module to obtain accurate object locations by looking back to the enhanced geometry and fine-grained details from the 3D scenes. A chain-of-grounding mechanism is proposed to further boost the performance with interleaved reasoning and grounding steps during inference. Extensive experiments on the proposed benchmark validate the effectiveness of our proposed approach.
7/2/2024