Four Ways to Improve Verbo-visual Fusion for Dense 3D Visual Grounding

0
📊
Sign in to get full access
Overview
- The paper introduces the task of dense 3D visual grounding, which involves localizing and segmenting 3D objects in a scene based on natural language descriptions.
- The authors propose a novel model called ConcreteNet that features several innovative modules to improve performance on challenging repetitive instances.
- ConcreteNet ranks 1st on the ScanRefer benchmark and won the 3D Object Localization challenge at the ICCV 3rd Workshop on Language for 3D Scenes.
Plain English Explanation
The paper discusses a technology called 3D visual grounding, which allows computers to understand and locate 3D objects in a scene based on descriptions in regular language. This has many practical applications, like in autonomous robotics or augmented/virtual reality.
A common way to do this is by using bounding boxes to mark the location of objects. However, for real-world uses that require physical interaction, a bounding box isn't detailed enough - you need to know the full 3D shape and position of the object. So the researchers tackle the harder problem of 3D instance segmentation, where they not only find the object, but outline its exact 3D form.
Their model, called ConcreteNet, has several clever features to help it perform well, especially on objects that are similar to each other (like a bunch of chairs in a room). For example, it uses an "attentive fusion" module to better understand the relationships between objects, and a "contrastive training" technique to make the model better at distinguishing between similar things. It also has ways to account for how the camera angle affects the descriptions.
By combining these innovations, ConcreteNet achieves state-of-the-art performance on a benchmark test, and even won a challenge related to this task. The researchers' work represents an important step forward in 3D object-centric AI, allowing computers to understand and interact with the 3D world more like humans do.
Technical Explanation
The paper introduces the task of dense 3D visual grounding, which involves localizing and segmenting 3D objects in a scene based on natural language descriptions. This extends beyond the common "grounding-by-detection" approach that only uses bounding boxes, towards a more detailed 3D instance segmentation.
The authors propose a novel model called ConcreteNet that features four key innovations:
-
Attentive Fusion Module: This module aims to better disambiguate relational cues between similar instances (e.g. multiple chairs) by fusing bottom-up visual features with top-down language guidance in an attentive manner.
-
Contrastive Training: The researchers develop a contrastive training scheme to induce stronger separation between instances in the latent space, further helping the model distinguish between repetitive objects.
-
Global Camera Token: ConcreteNet resolves view-dependent language expressions by learning a global camera token that encodes information about the scene perspective.
-
Multi-View Ensembling: The model combines predictions from multiple viewpoints to improve the quality and consistency of the final 3D segmentation masks.
Experiments show that ConcreteNet achieves state-of-the-art performance on the challenging ScanRefer benchmark, and won the 3D Object Localization challenge at the ICCV 3rd Workshop on Language for 3D Scenes. This demonstrates the effectiveness of the proposed techniques for advancing 3D visual grounding capabilities.
Critical Analysis
The paper presents a compelling approach to the important problem of dense 3D visual grounding. The authors identify key challenges, such as dealing with repetitive instances, and propose innovative solutions that push the state-of-the-art.
One potential limitation is that the model's performance may still be sensitive to the specific dataset and task formulation. The researchers acknowledge that the ScanRefer benchmark, while challenging, may not fully capture the complexity of real-world 3D environments. Further evaluation on more diverse datasets would help validate the generalizability of ConcreteNet.
Additionally, while the multi-view ensembling technique improves mask quality, it comes at the cost of increased computational complexity. This may limit the practicality of the model for certain applications that require real-time performance.
Overall, the paper makes a strong contribution to the field of 3D visual grounding and 3D object-centric AI. The innovative modules and high-performing results on benchmark tasks suggest that ConcreteNet is a promising step towards more robust and versatile 3D understanding capabilities.
Conclusion
This paper introduces the task of dense 3D visual grounding and proposes the ConcreteNet model as a novel solution. By addressing key challenges like repetitive instances and view-dependent language, the researchers have pushed the state-of-the-art in this important area of 3D scene understanding.
The strong performance of ConcreteNet on benchmarks and challenges demonstrates the potential of the model's techniques for enabling more sophisticated 3D-aware applications, from autonomous robotics to augmented/virtual reality. As 3D sensing and modeling capabilities continue to advance, the ability to accurately ground language to 3D structures will become increasingly valuable for real-world AI systems that need to understand and interact with the physical environment.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
0
Four Ways to Improve Verbo-visual Fusion for Dense 3D Visual Grounding
Ozan Unal, Christos Sakaridis, Suman Saha, Luc Van Gool
3D visual grounding is the task of localizing the object in a 3D scene which is referred by a description in natural language. With a wide range of applications ranging from autonomous indoor robotics to AR/VR, the task has recently risen in popularity. A common formulation to tackle 3D visual grounding is grounding-by-detection, where localization is done via bounding boxes. However, for real-life applications that require physical interactions, a bounding box insufficiently describes the geometry of an object. We therefore tackle the problem of dense 3D visual grounding, i.e. referral-based 3D instance segmentation. We propose a dense 3D grounding network ConcreteNet, featuring four novel stand-alone modules that aim to improve grounding performance for challenging repetitive instances, i.e. instances with distractors of the same semantic class. First, we introduce a bottom-up attentive fusion module that aims to disambiguate inter-instance relational cues, next, we construct a contrastive training scheme to induce separation in the latent space, we then resolve view-dependent utterances via a learned global camera token, and finally we employ multi-view ensembling to improve referred mask quality. ConcreteNet ranks 1st on the challenging ScanRefer online benchmark and has won the ICCV 3rd Workshop on Language for 3D Scenes 3D Object Localization challenge. Our code is available at ouenal.github.io/concretenet/.
Read more7/17/2024
0
Rethinking 3D Dense Caption and Visual Grounding in A Unified Framework through Prompt-based Localization
Yongdong Luo, Haojia Lin, Xiawu Zheng, Yigeng Jiang, Fei Chao, Jie Hu, Guannan Jiang, Songan Zhang, Rongrong Ji
3D Visual Grounding (3DVG) and 3D Dense Captioning (3DDC) are two crucial tasks in various 3D applications, which require both shared and complementary information in localization and visual-language relationships. Therefore, existing approaches adopt the two-stage detect-then-describe/discriminate pipeline, which relies heavily on the performance of the detector, resulting in suboptimal performance. Inspired by DETR, we propose a unified framework, 3DGCTR, to jointly solve these two distinct but closely related tasks in an end-to-end fashion. The key idea is to reconsider the prompt-based localization ability of the 3DVG model. In this way, the 3DVG model with a well-designed prompt as input can assist the 3DDC task by extracting localization information from the prompt. In terms of implementation, we integrate a Lightweight Caption Head into the existing 3DVG network with a Caption Text Prompt as a connection, effectively harnessing the existing 3DVG model's inherent localization capacity, thereby boosting 3DDC capability. This integration facilitates simultaneous multi-task training on both tasks, mutually enhancing their performance. Extensive experimental results demonstrate the effectiveness of this approach. Specifically, on the ScanRefer dataset, 3DGCTR surpasses the state-of-the-art 3DDC method by 4.3% in [email protected] in MLE training and improves upon the SOTA 3DVG method by 3.16% in [email protected]. The codes are at https://github.com/Leon1207/3DGCTR.
Read more9/20/2024
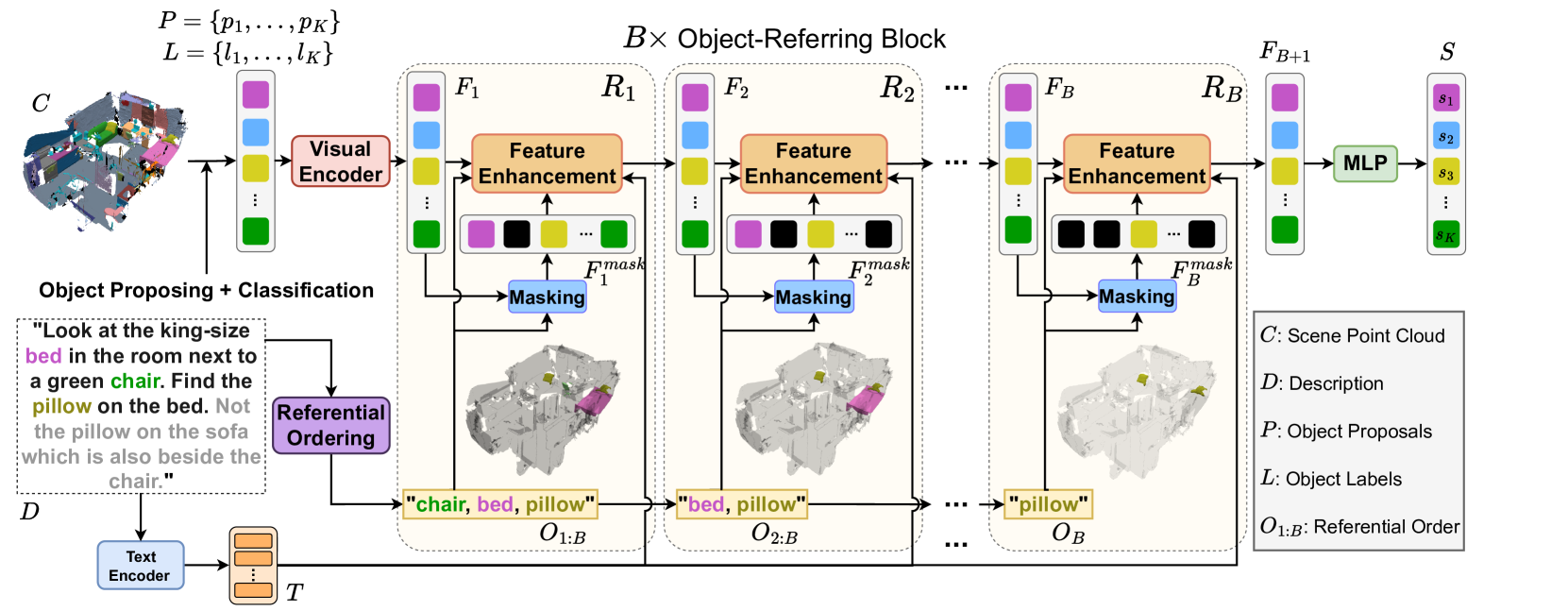
0
Data-Efficient 3D Visual Grounding via Order-Aware Referring
Tung-Yu Wu, Sheng-Yu Huang, Yu-Chiang Frank Wang
3D visual grounding aims to identify the target object within a 3D point cloud scene referred to by a natural language description. Previous works usually require significant data relating to point color and their descriptions to exploit the corresponding complicated verbo-visual relations. In our work, we introduce Vigor, a novel Data-Efficient 3D Visual Grounding framework via Order-aware Referring. Vigor leverages LLM to produce a desirable referential order from the input description for 3D visual grounding. With the proposed stacked object-referring blocks, the predicted anchor objects in the above order allow one to locate the target object progressively without supervision on the identities of anchor objects or exact relations between anchor/target objects. In addition, we present an order-aware warm-up training strategy, which augments referential orders for pre-training the visual grounding framework. This allows us to better capture the complex verbo-visual relations and benefit the desirable data-efficient learning scheme. Experimental results on the NR3D and ScanRefer datasets demonstrate our superiority in low-resource scenarios. In particular, Vigor surpasses current state-of-the-art frameworks by 9.3% and 7.6% grounding accuracy under 1% data and 10% data settings on the NR3D dataset, respectively.
Read more6/3/2024

0
CoT3DRef: Chain-of-Thoughts Data-Efficient 3D Visual Grounding
Eslam Mohamed Bakr, Mohamed Ayman, Mahmoud Ahmed, Habib Slim, Mohamed Elhoseiny
3D visual grounding is the ability to localize objects in 3D scenes conditioned by utterances. Most existing methods devote the referring head to localize the referred object directly, causing failure in complex scenarios. In addition, it does not illustrate how and why the network reaches the final decision. In this paper, we address this question Can we design an interpretable 3D visual grounding framework that has the potential to mimic the human perception system?. To this end, we formulate the 3D visual grounding problem as a sequence-to-sequence Seq2Seq task by first predicting a chain of anchors and then the final target. Interpretability not only improves the overall performance but also helps us identify failure cases. Following the chain of thoughts approach enables us to decompose the referring task into interpretable intermediate steps, boosting the performance and making our framework extremely data-efficient. Moreover, our proposed framework can be easily integrated into any existing architecture. We validate our approach through comprehensive experiments on the Nr3D, Sr3D, and Scanrefer benchmarks and show consistent performance gains compared to existing methods without requiring manually annotated data. Furthermore, our proposed framework, dubbed CoT3DRef, is significantly data-efficient, whereas on the Sr3D dataset, when trained only on 10% of the data, we match the SOTA performance that trained on the entire data. The code is available at https:eslambakr.github.io/cot3dref.github.io/.
Read more4/23/2024