CoT3DRef: Chain-of-Thoughts Data-Efficient 3D Visual Grounding
2310.06214
0
0

Abstract
3D visual grounding is the ability to localize objects in 3D scenes conditioned by utterances. Most existing methods devote the referring head to localize the referred object directly, causing failure in complex scenarios. In addition, it does not illustrate how and why the network reaches the final decision. In this paper, we address this question Can we design an interpretable 3D visual grounding framework that has the potential to mimic the human perception system?. To this end, we formulate the 3D visual grounding problem as a sequence-to-sequence Seq2Seq task by first predicting a chain of anchors and then the final target. Interpretability not only improves the overall performance but also helps us identify failure cases. Following the chain of thoughts approach enables us to decompose the referring task into interpretable intermediate steps, boosting the performance and making our framework extremely data-efficient. Moreover, our proposed framework can be easily integrated into any existing architecture. We validate our approach through comprehensive experiments on the Nr3D, Sr3D, and Scanrefer benchmarks and show consistent performance gains compared to existing methods without requiring manually annotated data. Furthermore, our proposed framework, dubbed CoT3DRef, is significantly data-efficient, whereas on the Sr3D dataset, when trained only on 10% of the data, we match the SOTA performance that trained on the entire data. The code is available at https:eslambakr.github.io/cot3dref.github.io/.
Create account to get full access
Overview
- This paper introduces CoT3DRef, a novel approach for data-efficient 3D visual grounding that leverages a chain-of-thought (CoT) mechanism.
- 3D visual grounding is the task of localizing 2D object references within 3D scenes, which is important for various applications like augmented reality and robotics.
- The CoT3DRef model aims to achieve high performance with limited training data by reasoning through a sequence of intermediate steps, similar to how humans solve such problems.
Plain English Explanation
The paper presents a new method called CoT3DRef that can locate 2D objects within 3D scenes effectively, even when limited training data is available. 3D visual grounding is the task of finding the position of objects described in text (like "the blue chair") within a 3D model or scene. This is important for applications like augmented reality and robotics that need to understand the 3D world.
The key innovation in CoT3DRef is that it reasons through a sequence of intermediate steps, similar to how humans might solve such a problem. Rather than trying to directly map the text to the 3D location, the model first grounds the text to 2D regions in images, then reasons about how those 2D regions correspond to 3D locations. This "chain of thought" allows the model to be more data-efficient, as it can learn the individual mapping steps from less training data.
The paper shows that CoT3DRef outperforms other 3D visual grounding methods, especially when training data is limited. This is an important advancement, as collecting large 3D datasets can be challenging and expensive. By being more data-efficient, CoT3DRef makes 3D visual grounding more practical for real-world applications.
Technical Explanation
CoT3DRef is a novel approach for 3D visual grounding that uses a chain-of-thought (CoT) mechanism to reason through intermediate steps. The model first grounds the textual reference to 2D regions in images, then infers the corresponding 3D locations based on the 2D-3D association.
The CoT3DRef architecture consists of several key components:
- A text encoder to represent the input textual reference.
- An image encoder to represent the 2D image regions.
- A 2D grounding module that aligns the text and 2D image features.
- A 3D reasoning module that maps the 2D grounding to corresponding 3D locations.
This staged approach allows CoT3DRef to be more data-efficient compared to end-to-end methods, as it can learn the individual mapping steps from less training data. The model is trained using a combination of supervised losses for the 2D grounding and 3D reasoning tasks.
Experiments on the RefCOCO+ and ScanRefer datasets show that CoT3DRef outperforms state-of-the-art 3D visual grounding methods, especially when training data is limited. This suggests the chain-of-thought approach is an effective way to tackle this task in a data-efficient manner.
Critical Analysis
The paper provides a thorough evaluation of CoT3DRef, including comparisons to various baselines and ablation studies. The results demonstrate the benefits of the CoT approach for 3D visual grounding, particularly its data efficiency.
However, the paper does not discuss potential limitations or caveats of the proposed method. For example, it is unclear how CoT3DRef would perform on more complex 3D scenes with occlusions or clutter, or how sensitive the model is to errors in the 2D grounding stage. Additionally, the paper does not address potential biases or fairness issues that could arise from the training data or model architecture.
Further research could investigate the generalization capabilities of CoT3DRef, explore ways to make the 2D-3D reasoning more robust, and consider the ethical implications of deploying such a system in real-world applications like robotics or augmented reality. Overall, the paper presents a promising approach, but additional analysis and validation would help strengthen the claims and ensure the model's suitability for practical use cases.
Conclusion
This paper introduces CoT3DRef, a novel 3D visual grounding method that uses a chain-of-thought mechanism to reason through intermediate steps. By decomposing the task into 2D grounding and 3D reasoning, CoT3DRef achieves strong performance with limited training data, which is a key advantage over end-to-end approaches.
The experimental results demonstrate the effectiveness of the CoT3DRef model, particularly in data-scarce scenarios. This is an important advancement, as collecting large 3D datasets can be challenging. By being more data-efficient, CoT3DRef makes 3D visual grounding more practical for real-world applications like augmented reality and robotics.
While the paper presents a promising approach, further research is needed to address potential limitations and ensure the model's robustness and fairness. Exploring the generalization capabilities of CoT3DRef and considering the ethical implications of deploying such a system would be valuable next steps.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

New!Empowering 3D Visual Grounding with Reasoning Capabilities
Chenming Zhu, Tai Wang, Wenwei Zhang, Kai Chen, Xihui Liu
0
0
Although great progress has been made in 3D visual grounding, current models still rely on explicit textual descriptions for grounding and lack the ability to reason human intentions from implicit instructions. We propose a new task called 3D reasoning grounding and introduce a new benchmark ScanReason which provides over 10K question-answer-location pairs from five reasoning types that require the synerization of reasoning and grounding. We further design our approach, ReGround3D, composed of the visual-centric reasoning module empowered by Multi-modal Large Language Model (MLLM) and the 3D grounding module to obtain accurate object locations by looking back to the enhanced geometry and fine-grained details from the 3D scenes. A chain-of-grounding mechanism is proposed to further boost the performance with interleaved reasoning and grounding steps during inference. Extensive experiments on the proposed benchmark validate the effectiveness of our proposed approach.
7/2/2024
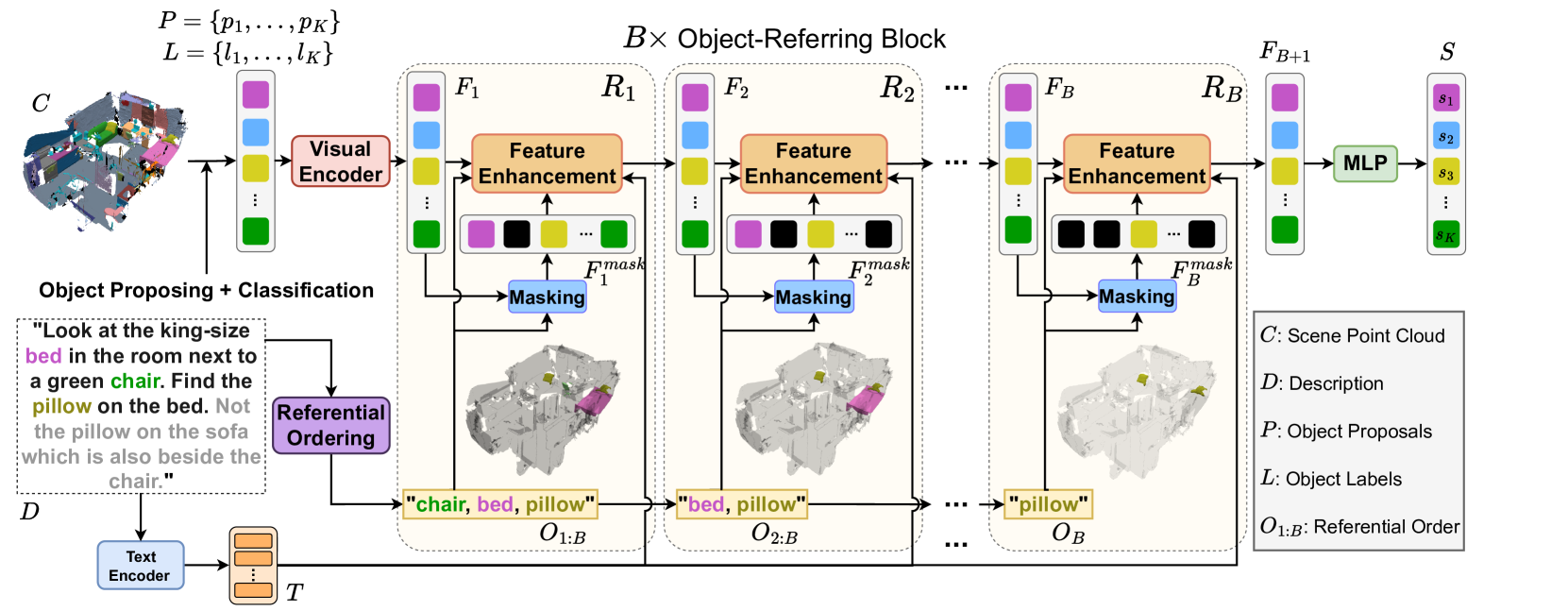
Data-Efficient 3D Visual Grounding via Order-Aware Referring
Tung-Yu Wu, Sheng-Yu Huang, Yu-Chiang Frank Wang
0
0
3D visual grounding aims to identify the target object within a 3D point cloud scene referred to by a natural language description. Previous works usually require significant data relating to point color and their descriptions to exploit the corresponding complicated verbo-visual relations. In our work, we introduce Vigor, a novel Data-Efficient 3D Visual Grounding framework via Order-aware Referring. Vigor leverages LLM to produce a desirable referential order from the input description for 3D visual grounding. With the proposed stacked object-referring blocks, the predicted anchor objects in the above order allow one to locate the target object progressively without supervision on the identities of anchor objects or exact relations between anchor/target objects. In addition, we present an order-aware warm-up training strategy, which augments referential orders for pre-training the visual grounding framework. This allows us to better capture the complex verbo-visual relations and benefit the desirable data-efficient learning scheme. Experimental results on the NR3D and ScanRefer datasets demonstrate our superiority in low-resource scenarios. In particular, Vigor surpasses current state-of-the-art frameworks by 9.3% and 7.6% grounding accuracy under 1% data and 10% data settings on the NR3D dataset, respectively.
6/3/2024

A Survey on Text-guided 3D Visual Grounding: Elements, Recent Advances, and Future Directions
Daizong Liu, Yang Liu, Wencan Huang, Wei Hu
0
0
Text-guided 3D visual grounding (T-3DVG), which aims to locate a specific object that semantically corresponds to a language query from a complicated 3D scene, has drawn increasing attention in the 3D research community over the past few years. Compared to 2D visual grounding, this task presents great potential and challenges due to its closer proximity to the real world and the complexity of data collection and 3D point cloud source processing. In this survey, we attempt to provide a comprehensive overview of the T-3DVG progress, including its fundamental elements, recent research advances, and future research directions. To the best of our knowledge, this is the first systematic survey on the T-3DVG task. Specifically, we first provide a general structure of the T-3DVG pipeline with detailed components in a tutorial style, presenting a complete background overview. Then, we summarize the existing T-3DVG approaches into different categories and analyze their strengths and weaknesses. We also present the benchmark datasets and evaluation metrics to assess their performances. Finally, we discuss the potential limitations of existing T-3DVG and share some insights on several promising research directions. The latest papers are continually collected at https://github.com/liudaizong/Awesome-3D-Visual-Grounding.
6/11/2024
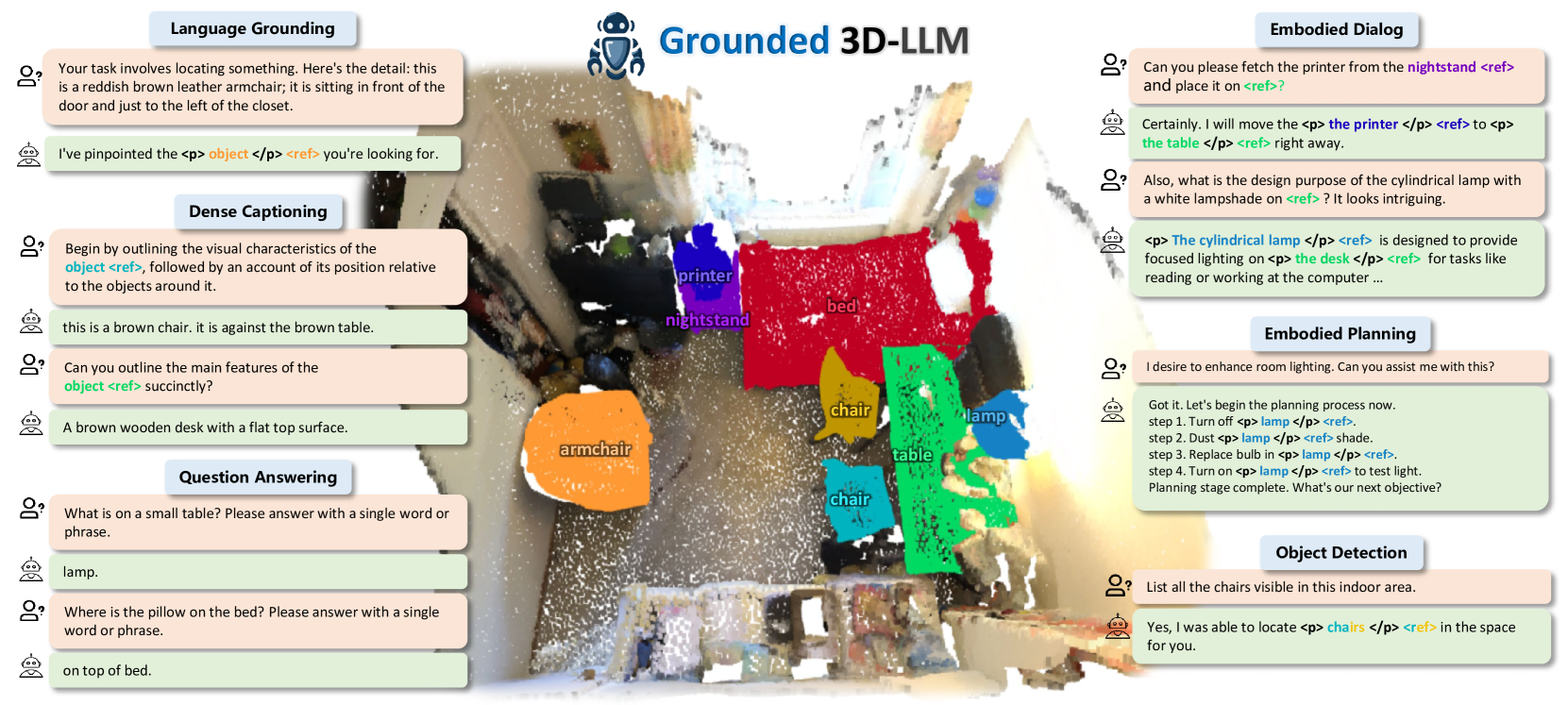
Grounded 3D-LLM with Referent Tokens
Yilun Chen, Shuai Yang, Haifeng Huang, Tai Wang, Ruiyuan Lyu, Runsen Xu, Dahua Lin, Jiangmiao Pang
0
0
Prior studies on 3D scene understanding have primarily developed specialized models for specific tasks or required task-specific fine-tuning. In this study, we propose Grounded 3D-LLM, which explores the potential of 3D large multi-modal models (3D LMMs) to consolidate various 3D vision tasks within a unified generative framework. The model uses scene referent tokens as special noun phrases to reference 3D scenes, enabling the handling of sequences that interleave 3D and textual data. It offers a natural approach for translating 3D vision tasks into language formats using task-specific instruction templates. To facilitate the use of referent tokens in subsequent language modeling, we have curated large-scale grounded language datasets that offer finer scene-text correspondence at the phrase level by bootstrapping existing object labels. Subsequently, we introduced Contrastive LAnguage-Scene Pre-training (CLASP) to effectively leverage this data, thereby integrating 3D vision with language models. Our comprehensive evaluation covers open-ended tasks like dense captioning and 3D QA, alongside close-ended tasks such as object detection and language grounding. Experiments across multiple 3D benchmarks reveal the leading performance and the broad applicability of Grounded 3D-LLM. Code and datasets will be released on the project page: https://groundedscenellm.github.io/grounded_3d-llm.github.io.
5/20/2024