Data Measurements for Decentralized Data Markets

0

Sign in to get full access
Overview
- The paper discusses data measurements for decentralized data markets, which are emerging platforms that allow individuals to securely buy, sell, and share data without a central authority.
- It explores federated data measurement techniques that can be used in these decentralized environments to assess the quality and value of data without compromising privacy or security.
- The research aims to enable fair and transparent data transactions in decentralized settings, where data providers and consumers can make informed decisions.
Plain English Explanation
Decentralized data markets are new types of online platforms that let people buy, sell, and share data without a central controller. This is an important development, as it gives individuals more control over their personal information. However, in these decentralized systems, it can be difficult to measure the quality and value of data in a fair and secure way.
The provided paper explores techniques called "federated data measurements" that can be used to assess data in decentralized data markets. These methods allow data providers and consumers to understand the characteristics of data without revealing sensitive details. This helps create more transparent and equitable data transactions, where both parties can make informed decisions.
The researchers draw inspiration from related work on incentivizing federation, data valuation, and data quality assessment in the context of federated learning. They also consider how to measure dataset similarity across decentralized data sources.
Technical Explanation
The paper proposes a framework for federated data measurements in decentralized data markets. The key idea is to enable data providers and consumers to assess the quality and value of data without revealing sensitive information about the underlying datasets.
The authors outline several technical components of their approach:
- Federated Data Profiling: Techniques for generating data profiles that summarize key statistical properties of a dataset without exposing individual data points.
- Federated Data Valuation: Methods for estimating the value of a dataset based on its characteristics and intended use case, again without accessing the raw data.
- Federated Data Quality Assessment: Procedures for evaluating the accuracy, completeness, and other quality metrics of a dataset in a decentralized manner.
These federated techniques allow data participants to make informed decisions about data transactions while preserving privacy and security. The researchers demonstrate the feasibility of their approach through experiments and discuss how it can be integrated into decentralized data market platforms.
Critical Analysis
The paper presents a thoughtful approach to data measurement in decentralized environments, addressing important challenges around privacy, security, and transparency. The proposed federated techniques seem promising, as they could enable fair and equitable data transactions without compromising the sensitive information of data providers.
However, the authors acknowledge several limitations and areas for further research. For example, they note the need to develop robust mechanisms for verifying the integrity of federated data profiles and valuations, as malicious actors could attempt to manipulate the measurements. Additionally, the scalability and performance of the federated techniques in large-scale, high-volume decentralized data markets require further investigation.
Another potential concern is the complexity of implementing these federated data measurement systems in practice. Integrating the various technical components and ensuring seamless interoperability across decentralized data market platforms could be a significant engineering challenge.
Overall, the research makes a valuable contribution to the emerging field of decentralized data economics. By addressing the critical issue of data measurement, the authors lay the groundwork for more transparent and efficient decentralized data markets. Continued research and real-world deployment of such federated techniques could have far-reaching implications for individual data rights, privacy, and the equitable exchange of information in the digital age.
Conclusion
The provided paper presents a framework for federated data measurements in decentralized data markets, aiming to facilitate fair and secure data transactions without a central authority. The researchers explore techniques for data profiling, valuation, and quality assessment that preserve the privacy and security of sensitive data.
By enabling data providers and consumers to make informed decisions about data exchange, the proposed approach could play a crucial role in the development of more transparent and equitable decentralized data ecosystems. While the authors highlight several areas for further research and practical challenges, the work represents an important step forward in realizing the promise of decentralized data markets.
As the digital economy continues to evolve, solutions like those discussed in this paper will be increasingly relevant, empowering individuals to take greater control over their data and participate in new forms of data-driven value creation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Data Measurements for Decentralized Data Markets
Charles Lu, Mohammad Mohammadi Amiri, Ramesh Raskar
Decentralized data markets can provide more equitable forms of data acquisition for machine learning. However, to realize practical marketplaces, efficient techniques for seller selection need to be developed. We propose and benchmark federated data measurements to allow a data buyer to find sellers with relevant and diverse datasets. Diversity and relevance measures enable a buyer to make relative comparisons between sellers without requiring intermediate brokers and training task-dependent models.
Read more6/7/2024
📊
0
Delegating Data Collection in Decentralized Machine Learning
Nivasini Ananthakrishnan, Stephen Bates, Michael I. Jordan, Nika Haghtalab
Motivated by the emergence of decentralized machine learning (ML) ecosystems, we study the delegation of data collection. Taking the field of contract theory as our starting point, we design optimal and near-optimal contracts that deal with two fundamental information asymmetries that arise in decentralized ML: uncertainty in the assessment of model quality and uncertainty regarding the optimal performance of any model. We show that a principal can cope with such asymmetry via simple linear contracts that achieve 1-1/e fraction of the optimal utility. To address the lack of a priori knowledge regarding the optimal performance, we give a convex program that can adaptively and efficiently compute the optimal contract. We also study linear contracts and derive the optimal utility in the more complex setting of multiple interactions.
Read more5/3/2024
📊
0
Incentivising the federation: gradient-based metrics for data selection and valuation in private decentralised training
Dmitrii Usynin, Daniel Rueckert, Georgios Kaissis
Obtaining high-quality data for collaborative training of machine learning models can be a challenging task due to A) regulatory concerns and B) a lack of data owner incentives to participate. The first issue can be addressed through the combination of distributed machine learning techniques (e.g. federated learning) and privacy enhancing technologies (PET), such as the differentially private (DP) model training. The second challenge can be addressed by rewarding the participants for giving access to data which is beneficial to the training model, which is of particular importance in federated settings, where the data is unevenly distributed. However, DP noise can adversely affect the underrepresented and the atypical (yet often informative) data samples, making it difficult to assess their usefulness. In this work, we investigate how to leverage gradient information to permit the participants of private training settings to select the data most beneficial for the jointly trained model. We assess two such methods, namely variance of gradients (VoG) and the privacy loss-input susceptibility score (PLIS). We show that these techniques can provide the federated clients with tools for principled data selection even in stricter privacy settings.
Read more4/17/2024
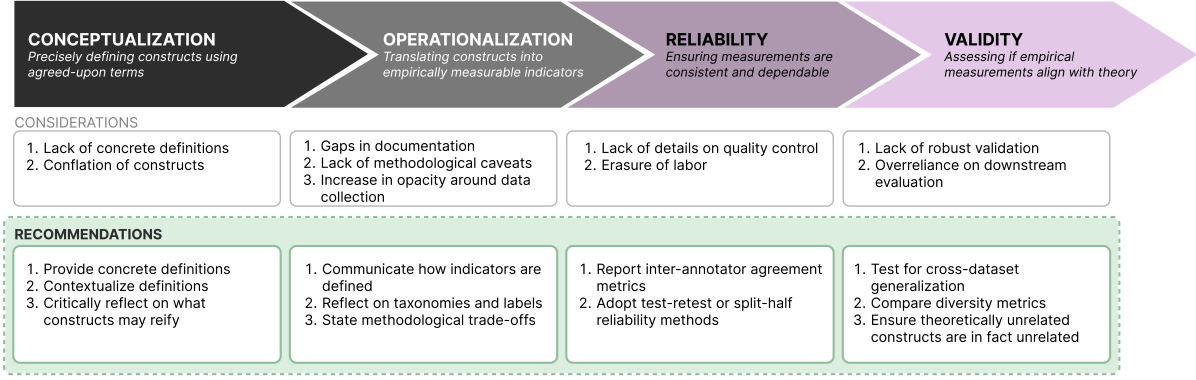
0
Position: Measure Dataset Diversity, Don't Just Claim It
Dora Zhao, Jerone T. A. Andrews, Orestis Papakyriakopoulos, Alice Xiang
Machine learning (ML) datasets, often perceived as neutral, inherently encapsulate abstract and disputed social constructs. Dataset curators frequently employ value-laden terms such as diversity, bias, and quality to characterize datasets. Despite their prevalence, these terms lack clear definitions and validation. Our research explores the implications of this issue by analyzing diversity across 135 image and text datasets. Drawing from social sciences, we apply principles from measurement theory to identify considerations and offer recommendations for conceptualizing, operationalizing, and evaluating diversity in datasets. Our findings have broader implications for ML research, advocating for a more nuanced and precise approach to handling value-laden properties in dataset construction.
Read more7/12/2024