Data Valuation and Detections in Federated Learning

0
📊
Sign in to get full access
Overview
- Federated Learning (FL) is a collaborative model training approach that preserves the privacy of raw data.
- A key challenge in FL is fairly and efficiently valuing the data contributed by each client, which is crucial for incentivizing high-quality data contributions.
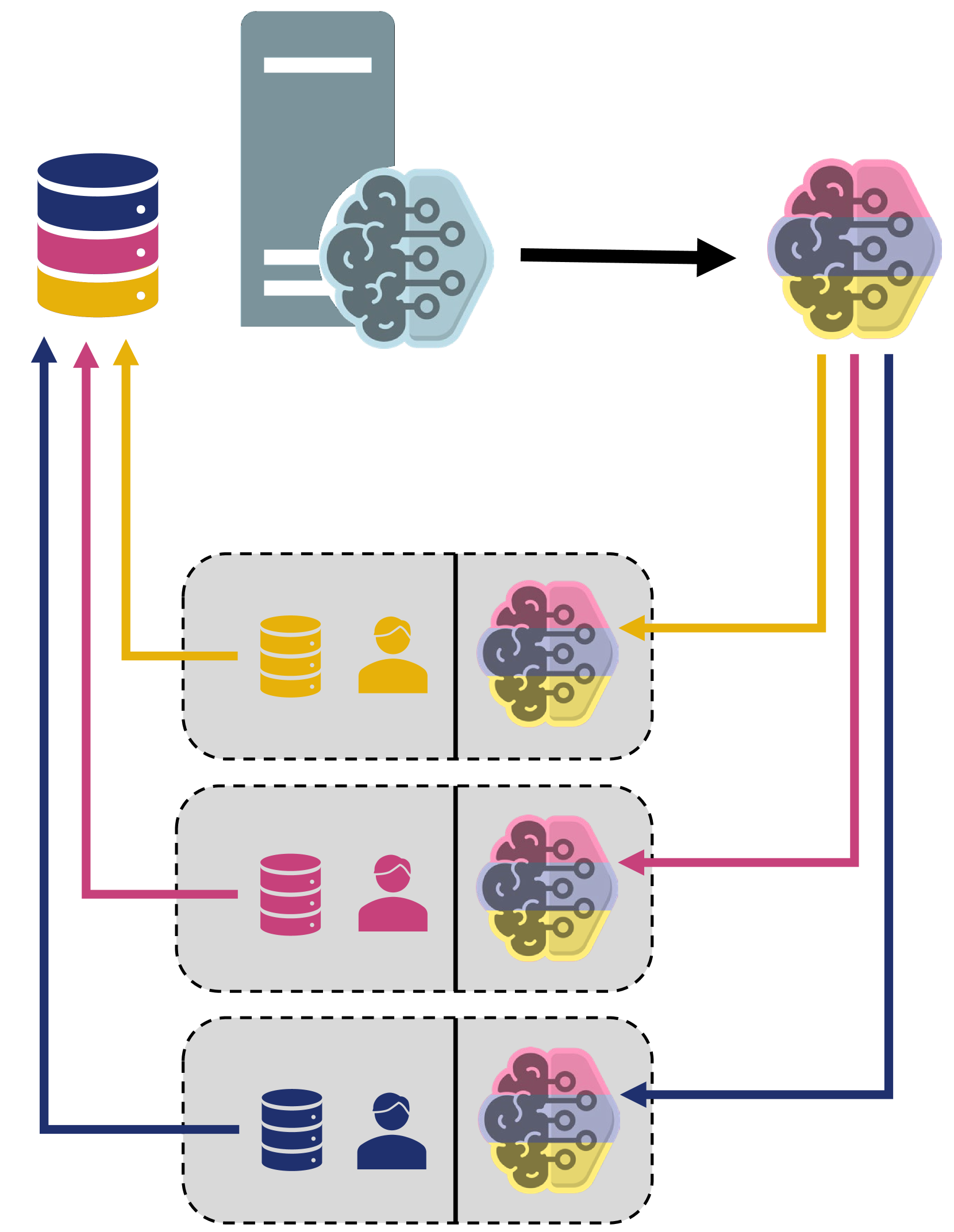
- This paper introduces a novel privacy-preserving method called FedBary for evaluating client contributions and selecting relevant datasets without a pre-specified training algorithm in an FL task.
- FedBary utilizes Wasserstein distance within the federated context, offering a new solution for data valuation in the FL framework.
Plain English Explanation
Federated Learning (FL) is a way for multiple parties to train a shared machine learning model without having to share their private data. This is useful when the data is sensitive, like medical records or financial information.
One challenge with FL is figuring out how to fairly value the data that each party contributes. This is important because you want to incentivize the parties to contribute high-quality data that will improve the model. In an FL system with many parties, only some of the datasets may be relevant to a specific learning task, while others could even have a negative impact.
The paper introduces a new method called FedBary that addresses this data valuation challenge. FedBary uses a mathematical concept called Wasserstein distance to evaluate how much each party's data contributes to the overall model. This allows for transparent data valuation and efficient computation, without needing to rely as heavily on additional validation datasets.
The researchers demonstrate the potential of this data valuation method through experiments and theoretical analysis. They show that FedBary is a promising approach for incentivising federation and selecting relevant datasets in Federated Learning tasks.
Technical Explanation
The paper introduces a novel privacy-preserving method called FedBary for evaluating client contributions and selecting relevant datasets in a Federated Learning (FL) task. FedBary utilizes Wasserstein distance within the federated context, offering a new solution for data valuation in the FL framework.
The key idea behind FedBary is to use the Wasserstein distance, a metric that quantifies the similarity between probability distributions, to measure the relevance of each client's data to the overall FL task. This allows the method to identify the most informative datasets without the need for a pre-specified training algorithm.
The researchers demonstrate the effectiveness of FedBary through extensive empirical experiments on several benchmark datasets. They show that FedBary can accurately evaluate client contributions and select the most relevant datasets, leading to improved model performance compared to baseline methods. Moreover, the approach reduces the dependence on validation datasets, which is a common limitation in Federated Bayesian Deep Learning and other Federated Learning frameworks.
Through theoretical analysis, the paper also provides insights into the properties of the Wasserstein distance in the federated context, establishing connections to universal dataset similarity metrics and demonstrating the robustness of the FedBary approach.
Critical Analysis
The paper presents a promising approach for data valuation in Federated Learning, but it also highlights several caveats and areas for further research:
-
The paper focuses on a specific FL scenario with a single learning task, but in real-world applications, there may be multiple learning tasks with varying data requirements. Extending FedBary to handle more complex FL setups would be a valuable direction for future research.
-
The theoretical analysis in the paper provides insights into the Wasserstein distance in the federated context, but a more comprehensive understanding of the properties and limitations of this metric in FL would be beneficial.
-
The empirical experiments in the paper demonstrate the effectiveness of FedBary, but it would be interesting to see how the method performs in settings with noisy or biased data, which are common challenges in real-world FL deployments.
-
The paper does not address the potential impact of FedBary on the overall incentive structure and participation dynamics within an FL system. Further research is needed to understand how this data valuation method affects client behavior and the long-term sustainability of the FL framework.
Overall, the FedBary approach presented in this paper is a notable contribution to the field of Federated Learning, but continued research and validation in diverse settings would be valuable to fully understand its potential and limitations.
Conclusion
This paper introduces a novel privacy-preserving method called FedBary for evaluating client contributions and selecting relevant datasets in Federated Learning (FL) tasks. By utilizing Wasserstein distance within the federated context, FedBary offers a new solution for data valuation that ensures transparent and efficient computation, while reducing the dependence on validation datasets.
The researchers demonstrate the potential of this data valuation method through extensive empirical experiments and theoretical analyses, showcasing its ability to accurately assess client contributions and identify the most relevant datasets. This work represents a promising avenue for Federated Learning research, with the potential to enhance the fairness, efficiency, and sustainability of collaborative model training while preserving data privacy.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
0
Data Valuation and Detections in Federated Learning
Wenqian Li, Shuran Fu, Fengrui Zhang, Yan Pang
Federated Learning (FL) enables collaborative model training while preserving the privacy of raw data. A challenge in this framework is the fair and efficient valuation of data, which is crucial for incentivizing clients to contribute high-quality data in the FL task. In scenarios involving numerous data clients within FL, it is often the case that only a subset of clients and datasets are pertinent to a specific learning task, while others might have either a negative or negligible impact on the model training process. This paper introduces a novel privacy-preserving method for evaluating client contributions and selecting relevant datasets without a pre-specified training algorithm in an FL task. Our proposed approach FedBary, utilizes Wasserstein distance within the federated context, offering a new solution for data valuation in the FL framework. This method ensures transparent data valuation and efficient computation of the Wasserstein barycenter and reduces the dependence on validation datasets. Through extensive empirical experiments and theoretical analyses, we demonstrate the potential of this data valuation method as a promising avenue for FL research.
Read more5/10/2024

0
Federated Fairness Analytics: Quantifying Fairness in Federated Learning
Oscar Dilley, Juan Marcelo Parra-Ullauri, Rasheed Hussain, Dimitra Simeonidou
Federated Learning (FL) is a privacy-enhancing technology for distributed ML. By training models locally and aggregating updates - a federation learns together, while bypassing centralised data collection. FL is increasingly popular in healthcare, finance and personal computing. However, it inherits fairness challenges from classical ML and introduces new ones, resulting from differences in data quality, client participation, communication constraints, aggregation methods and underlying hardware. Fairness remains an unresolved issue in FL and the community has identified an absence of succinct definitions and metrics to quantify fairness; to address this, we propose Federated Fairness Analytics - a methodology for measuring fairness. Our definition of fairness comprises four notions with novel, corresponding metrics. They are symptomatically defined and leverage techniques originating from XAI, cooperative game-theory and networking engineering. We tested a range of experimental settings, varying the FL approach, ML task and data settings. The results show that statistical heterogeneity and client participation affect fairness and fairness conscious approaches such as Ditto and q-FedAvg marginally improve fairness-performance trade-offs. Using our techniques, FL practitioners can uncover previously unobtainable insights into their system's fairness, at differing levels of granularity in order to address fairness challenges in FL. We have open-sourced our work at: https://github.com/oscardilley/federated-fairness.
Read more8/16/2024
📶
0
Federated Learning Can Find Friends That Are Advantageous
Nazarii Tupitsa, Samuel Horv'ath, Martin Tak'av{c}, Eduard Gorbunov
In Federated Learning (FL), the distributed nature and heterogeneity of client data present both opportunities and challenges. While collaboration among clients can significantly enhance the learning process, not all collaborations are beneficial; some may even be detrimental. In this study, we introduce a novel algorithm that assigns adaptive aggregation weights to clients participating in FL training, identifying those with data distributions most conducive to a specific learning objective. We demonstrate that our aggregation method converges no worse than the method that aggregates only the updates received from clients with the same data distribution. Furthermore, empirical evaluations consistently reveal that collaborations guided by our algorithm outperform traditional FL approaches. This underscores the critical role of judicious client selection and lays the foundation for more streamlined and effective FL implementations in the coming years.
Read more7/18/2024
0
Federated Learning: A Cutting-Edge Survey of the Latest Advancements and Applications
Azim Akhtarshenas, Mohammad Ali Vahedifar, Navid Ayoobi, Behrouz Maham, Tohid Alizadeh, Sina Ebrahimi, David L'opez-P'erez
Robust machine learning (ML) models can be developed by leveraging large volumes of data and distributing the computational tasks across numerous devices or servers. Federated learning (FL) is a technique in the realm of ML that facilitates this goal by utilizing cloud infrastructure to enable collaborative model training among a network of decentralized devices. Beyond distributing the computational load, FL targets the resolution of privacy issues and the reduction of communication costs simultaneously. To protect user privacy, FL requires users to send model updates rather than transmitting large quantities of raw and potentially confidential data. Specifically, individuals train ML models locally using their own data and then upload the results in the form of weights and gradients to the cloud for aggregation into the global model. This strategy is also advantageous in environments with limited bandwidth or high communication costs, as it prevents the transmission of large data volumes. With the increasing volume of data and rising privacy concerns, alongside the emergence of large-scale ML models like Large Language Models (LLMs), FL presents itself as a timely and relevant solution. It is therefore essential to review current FL algorithms to guide future research that meets the rapidly evolving ML demands. This survey provides a comprehensive analysis and comparison of the most recent FL algorithms, evaluating them on various fronts including mathematical frameworks, privacy protection, resource allocation, and applications. Beyond summarizing existing FL methods, this survey identifies potential gaps, open areas, and future challenges based on the performance reports and algorithms used in recent studies. This survey enables researchers to readily identify existing limitations in the FL field for further exploration.
Read more5/28/2024