Position: Measure Dataset Diversity, Don't Just Claim It

0
Sign in to get full access
Overview
- Emphasizes the importance of quantifying dataset diversity, rather than just claiming diversity
- Highlights the need for standardized, reproducible metrics to measure diversity and bias in AI datasets
- Discusses various challenges in curating fair and diverse datasets for AI systems
Plain English Explanation
Measuring the diversity of datasets used to train AI systems is crucial, but many researchers simply claim their datasets are diverse without providing concrete evidence. This paper argues that we need standardized, quantifiable metrics to assess the true diversity and potential biases within AI datasets.
The authors point to several recent studies that have developed principled approaches to measuring dataset bias, assessing linguistic diversity in multilingual NLP, and cataloging the challenges of curating fair datasets. However, they argue these efforts are not yet widely adopted, and more work is needed to standardize diversity measurement in AI.
The paper also highlights examples where researchers have tried to address cultural and socioeconomic diversity in their datasets, but notes the need for a more systematic approach to bias exploration in AI. By quantifying dataset diversity, the authors believe researchers can make more informed decisions about model development and deployment.
Technical Explanation
The paper emphasizes the importance of measuring dataset diversity, rather than simply claiming datasets are diverse. The authors argue that standardized, reproducible metrics are needed to assess the true diversity and potential biases within AI datasets.
The paper discusses several recent studies that have developed new approaches to measuring dataset bias and diversity. For example, Hardt et al. proposed a principled framework for defining and measuring bias in datasets. Srinivasan et al. developed techniques to transparently measure and compare linguistic diversity in multilingual NLP datasets. Additionally, Mitchell et al. cataloged a taxonomy of challenges in curating fair datasets for AI systems.
The paper also highlights examples where researchers have attempted to address cultural and socioeconomic diversity in their datasets, such as the No Filter approach for contrastive vision tasks. However, the authors note the need for a more systematic approach to bias exploration in AI.
Critical Analysis
The paper makes a compelling case for the need to measure dataset diversity rather than simply claiming it. The authors highlight important prior work in this area, but note that these efforts have not yet been widely adopted. One potential limitation is that the paper does not provide a specific set of standardized metrics or a clear roadmap for developing them.
Additionally, the paper could have delved deeper into the challenges and trade-offs involved in curating diverse datasets, such as the tension between breadth and depth of coverage, the difficulty of obtaining representative samples, and the ethical considerations around data collection and use.
While the paper encourages readers to think critically about dataset diversity, it could have also addressed potential pushback or skepticism from the AI community, and how to overcome resistance to adopting more rigorous diversity measurement practices.
Conclusion
This paper makes a compelling argument for the importance of quantifying dataset diversity in AI, rather than simply claiming it. The authors highlight the need for standardized, reproducible metrics to assess the true diversity and potential biases within AI datasets, and point to several recent studies that have made progress in this direction.
By developing and widely adopting such diversity measurement practices, the AI community can make more informed decisions about model development and deployment, and work towards building more inclusive, representative, and equitable AI systems. The paper serves as a call to action for the AI research community to prioritize dataset diversity as a key consideration in their work.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Position: Measure Dataset Diversity, Don't Just Claim It
Dora Zhao, Jerone T. A. Andrews, Orestis Papakyriakopoulos, Alice Xiang
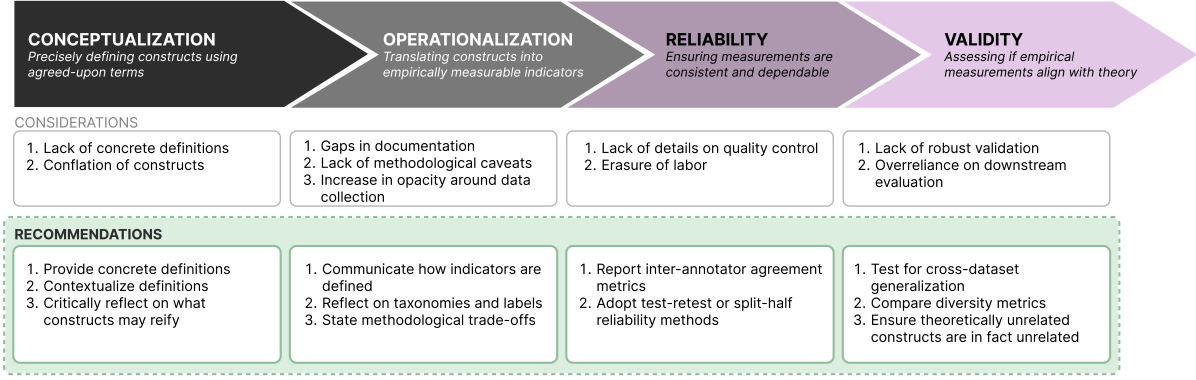
Machine learning (ML) datasets, often perceived as neutral, inherently encapsulate abstract and disputed social constructs. Dataset curators frequently employ value-laden terms such as diversity, bias, and quality to characterize datasets. Despite their prevalence, these terms lack clear definitions and validation. Our research explores the implications of this issue by analyzing diversity across 135 image and text datasets. Drawing from social sciences, we apply principles from measurement theory to identify considerations and offer recommendations for conceptualizing, operationalizing, and evaluating diversity in datasets. Our findings have broader implications for ML research, advocating for a more nuanced and precise approach to handling value-laden properties in dataset construction.
Read more7/12/2024
3
Beyond Scale: The Diversity Coefficient as a Data Quality Metric for Variability in Natural Language Data
Brando Miranda, Alycia Lee, Sudharsan Sundar, Allison Casasola, Sanmi Koyejo
Current trends in pre-training Large Language Models (LLMs) primarily focus on the scaling of model and dataset size. While the quality of pre-training data is considered an important factor for training powerful LLMs, it remains a nebulous concept that has not been rigorously characterized. To this end, we propose a formalization of one key aspect of data quality -- measuring the variability of natural language data -- specifically via a measure we call the diversity coefficient. Our empirical analysis shows that the proposed diversity coefficient aligns with the intuitive properties of diversity and variability, e.g., it increases as the number of latent concepts increases. Then, we measure the diversity coefficient of publicly available pre-training datasets and demonstrate that their formal diversity is high compared to theoretical lower and upper bounds. Finally, we conduct a comprehensive set of controlled interventional experiments with GPT-2 and LLaMAv2 that demonstrate the diversity coefficient of pre-training data characterizes useful aspects of downstream model evaluation performance -- totaling 44 models of various sizes (51M to 7B parameters). We conclude that our formal notion of diversity is an important aspect of data quality that captures variability and causally leads to improved evaluation performance.
Read more8/27/2024
📉
0
A Principled Approach for a New Bias Measure
Bruno Scarone, Alfredo Viola, Ren'ee J. Miller, Ricardo Baeza-Yates
The widespread use of machine learning and data-driven algorithms for decision making has been steadily increasing over many years. The areas in which this is happening are diverse: healthcare, employment, finance, education, the legal system to name a few; and the associated negative side effects are being increasingly harmful for society. Negative data emph{bias} is one of those, which tends to result in harmful consequences for specific groups of people. Any mitigation strategy or effective policy that addresses the negative consequences of bias must start with awareness that bias exists, together with a way to understand and quantify it. However, there is a lack of consensus on how to measure data bias and oftentimes the intended meaning is context dependent and not uniform within the research community. The main contributions of our work are: (1) The definition of Uniform Bias (UB), the first bias measure with a clear and simple interpretation in the full range of bias values. (2) A systematic study to characterize the flaws of existing measures in the context of anti employment discrimination rules used by the Office of Federal Contract Compliance Programs, additionally showing how UB solves open problems in this domain. (3) A framework that provides an efficient way to derive a mathematical formula for a bias measure based on an algorithmic specification of bias addition. Our results are experimentally validated using nine publicly available datasets and theoretically analyzed, which provide novel insights about the problem. Based on our approach, we also design a bias mitigation model that might be useful to policymakers.
Read more9/12/2024

0
A Measure for Transparent Comparison of Linguistic Diversity in Multilingual NLP Data Sets
Tanja Samardzic, Ximena Gutierrez, Christian Bentz, Steven Moran, Olga Pelloni
Typologically diverse benchmarks are increasingly created to track the progress achieved in multilingual NLP. Linguistic diversity of these data sets is typically measured as the number of languages or language families included in the sample, but such measures do not consider structural properties of the included languages. In this paper, we propose assessing linguistic diversity of a data set against a reference language sample as a means of maximising linguistic diversity in the long run. We represent languages as sets of features and apply a version of the Jaccard index suitable for comparing sets of measures. In addition to the features extracted from typological data bases, we propose an automatic text-based measure, which can be used as a means of overcoming the well-known problem of data sparsity in manually collected features. Our diversity score is interpretable in terms of linguistic features and can identify the types of languages that are not represented in a data set. Using our method, we analyse a range of popular multilingual data sets (UD, Bible100, mBERT, XTREME, XGLUE, XNLI, XCOPA, TyDiQA, XQuAD). In addition to ranking these data sets, we find, for example, that (poly)synthetic languages are missing in almost all of them.
Read more4/17/2024