Data Mixture Inference: What do BPE Tokenizers Reveal about their Training Data?

0

Sign in to get full access
Overview
- This paper investigates what Byte-Pair Encoding (BPE) tokenizers reveal about the training data used to create them.
- BPE tokenizers are commonly used in natural language processing, but their inner workings are not well understood.
- The researchers aim to uncover insights about the data composition and distribution by analyzing the tokenizers themselves.
Plain English Explanation
The paper looks at Byte-Pair Encoding (BPE) tokenizers, which are tools used in natural language processing to break down text into smaller units called "tokens." These tokenizers are trained on large datasets, but it's not always clear what kind of data they were trained on.
The researchers in this study wanted to see if they could learn something about the training data by analyzing the inner workings of the tokenizers themselves. They hypothesized that the way the tokenizers break down words and phrases might reveal clues about the types of text they were exposed to during training.
By carefully examining the tokens created by different BPE tokenizers, the researchers were able to uncover insights about the data composition and distribution. This could help us better understand how these tokenizers work and how they might perform on different types of text.
Technical Explanation
The paper focuses on analyzing Byte-Pair Encoding (BPE) tokenizers, which are a popular technique used in natural language processing to break down text into smaller units called "tokens." These tokenizers are trained on large datasets, but the details of the training data are often opaque.
The researchers developed a method to infer the properties of the training data by examining the tokenizers themselves. They hypothesized that the way the tokenizers break down words and phrases might reveal clues about the types of text they were exposed to during training.
Through a series of experiments, the researchers analyzed the tokens produced by different BPE tokenizers and found that the tokenization patterns were indeed correlated with the characteristics of the training data. For example, they could detect the presence of specialized terminology, foreign languages, and even demographic biases in the data.
These findings suggest that the tokenization process can be a valuable tool for understanding the composition and distribution of the data used to train natural language processing models. This knowledge could help researchers and practitioners make more informed decisions about model development and deployment.
Critical Analysis
The paper provides a novel and insightful approach to studying the inner workings of BPE tokenizers and what they reveal about the training data. The researchers acknowledge that their method is not a comprehensive solution and that further research is needed to fully understand the relationship between tokenization and data composition.
One potential limitation of the study is that it focuses on a specific tokenization technique (BPE) and does not consider other approaches, such as subword unit tokenization. It would be interesting to see if the researchers' findings can be extended to other tokenization methods or if there are unique insights to be gained from each approach.
Additionally, the paper does not delve into the potential implications of these findings for downstream tasks or the fairness and robustness of language models. Further research could explore how the insights from tokenizer analysis can be used to mitigate biases or improve the performance of natural language processing systems.
Conclusion
This paper presents a novel approach to studying the training data of natural language processing models by analyzing the inner workings of BPE tokenizers. The researchers were able to uncover insights about the composition and distribution of the data used to train these tokenizers, which could have important implications for model development and deployment.
While the study is limited in scope, it opens up new avenues for research on the relationship between tokenization and data properties. By continuing to explore these connections, researchers and practitioners may be able to develop more robust and fair natural language processing systems that better reflect the diversity of human language and experience.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Data Mixture Inference: What do BPE Tokenizers Reveal about their Training Data?
Jonathan Hayase, Alisa Liu, Yejin Choi, Sewoong Oh, Noah A. Smith
The pretraining data of today's strongest language models is opaque; in particular, little is known about the proportions of various domains or languages represented. In this work, we tackle a task which we call data mixture inference, which aims to uncover the distributional make-up of training data. We introduce a novel attack based on a previously overlooked source of information: byte-pair encoding (BPE) tokenizers, used by the vast majority of modern language models. Our key insight is that the ordered list of merge rules learned by a BPE tokenizer naturally reveals information about the token frequencies in its training data. Given a tokenizer's merge list along with example data for each category of interest, we formulate a linear program that solves for the proportion of each category in the tokenizer's training set. In controlled experiments, we show that our attack recovers mixture ratios with high precision for tokenizers trained on known mixtures of natural languages, programming languages, and data sources. We then apply our approach to off-the-shelf tokenizers released with recent LMs. We confirm much publicly disclosed information about these models, and also make several new inferences: GPT-4o and Mistral NeMo's tokenizers are much more multilingual than their predecessors, training on 39% and 47% non-English language data, respectively; Llama 3 extends GPT-3.5's tokenizer primarily for multilingual (48%) use; GPT-3.5's and Claude's tokenizers are trained on predominantly code (~60%). We hope our work sheds light on current design practices for pretraining data, and inspires continued research into data mixture inference for LMs.
Read more9/6/2024
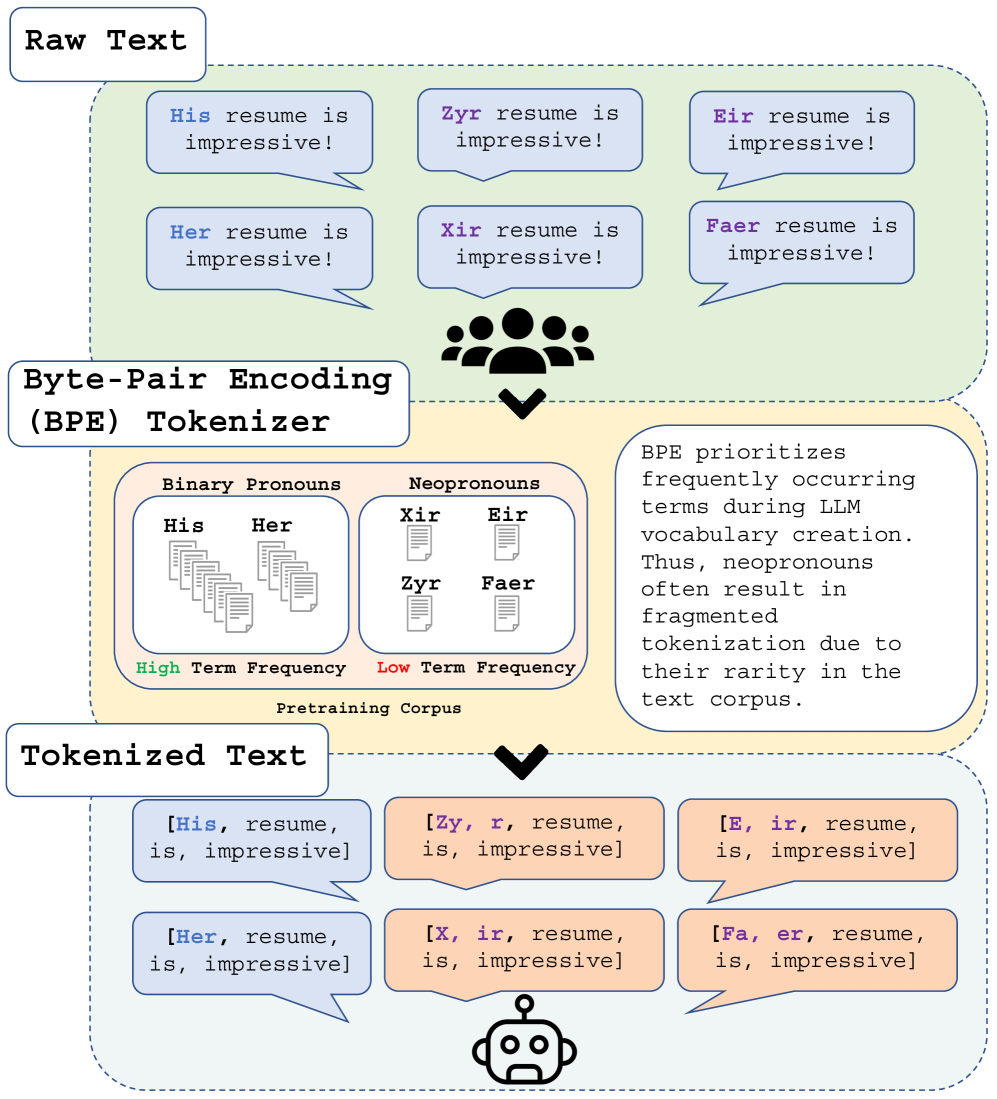
0
Tokenization Matters: Navigating Data-Scarce Tokenization for Gender Inclusive Language Technologies
Anaelia Ovalle, Ninareh Mehrabi, Palash Goyal, Jwala Dhamala, Kai-Wei Chang, Richard Zemel, Aram Galstyan, Yuval Pinter, Rahul Gupta
Gender-inclusive NLP research has documented the harmful limitations of gender binary-centric large language models (LLM), such as the inability to correctly use gender-diverse English neopronouns (e.g., xe, zir, fae). While data scarcity is a known culprit, the precise mechanisms through which scarcity affects this behavior remain underexplored. We discover LLM misgendering is significantly influenced by Byte-Pair Encoding (BPE) tokenization, the tokenizer powering many popular LLMs. Unlike binary pronouns, BPE overfragments neopronouns, a direct consequence of data scarcity during tokenizer training. This disparate tokenization mirrors tokenizer limitations observed in multilingual and low-resource NLP, unlocking new misgendering mitigation strategies. We propose two techniques: (1) pronoun tokenization parity, a method to enforce consistent tokenization across gendered pronouns, and (2) utilizing pre-existing LLM pronoun knowledge to improve neopronoun proficiency. Our proposed methods outperform finetuning with standard BPE, improving neopronoun accuracy from 14.1% to 58.4%. Our paper is the first to link LLM misgendering to tokenization and deficient neopronoun grammar, indicating that LLMs unable to correctly treat neopronouns as pronouns are more prone to misgender.
Read more4/9/2024

0
BPE Gets Picky: Efficient Vocabulary Refinement During Tokenizer Training
Pavel Chizhov, Catherine Arnett, Elizaveta Korotkova, Ivan P. Yamshchikov
Language models can largely benefit from efficient tokenization. However, they still mostly utilize the classical BPE algorithm, a simple and reliable method. This has been shown to cause such issues as under-trained tokens and sub-optimal compression that may affect the downstream performance. We introduce Picky BPE, a modified BPE algorithm that carries out vocabulary refinement during tokenizer training. Our method improves vocabulary efficiency, eliminates under-trained tokens, and does not compromise text compression. Our experiments show that our method does not reduce the downstream performance, and in several cases improves it.
Read more9/10/2024

0
Batching BPE Tokenization Merges
Alexander P. Morgan
The Byte Pair Encoding algorithm can be safely batched to merge hundreds of pairs of tokens at a time when building up a tokenizer's vocabulary. This technique combined with reducing the memory footprint of text used in vocabulary training make it feasible to train a high quality tokenizer on a basic laptop. This paper presents BatchBPE, an open-source pure Python implementation of these concepts, with the goal of making experimenting with new tokenization strategies more accessible especially in compute- and memory-constrained contexts. BatchBPE's usefulness and malleability are demonstrated through the training of several token vocabularies to explore the batch merging process and experiment with preprocessing a stop word list and ignoring the least common text chunks in a dataset. Resultant encoded lengths of texts are used as a basic evaluation metric.
Read more8/12/2024