Unpacking Tokenization: Evaluating Text Compression and its Correlation with Model Performance

0

Sign in to get full access
Overview
- The research paper examines the relationship between text compression and model performance, with a focus on evaluating the quality of tokenization.
- It explores how the compression ratio of text can provide insights into the effectiveness of tokenization and its impact on language model performance.
- The study aims to shed light on the role of compression in the tokenization process and its implications for language modeling tasks.
Plain English Explanation
The research paper explores the connection between how text is broken down into smaller units (called tokens) and the performance of language models, which are AI systems that can understand and generate human-like language.
The key idea is that the way text is tokenized can affect how well the language model performs on various tasks. If the tokenization process is effective, it should result in a more compact representation of the text, which can then be efficiently processed by the language model.
The researchers investigate this by looking at the relationship between the compression ratio of the text (how much the text can be compressed without losing information) and the performance of the language model. They hypothesize that a higher compression ratio, indicating more efficient tokenization, should be correlated with better model performance.
By understanding this link between tokenization, compression, and model performance, the researchers hope to provide insights that can help improve the design and development of language models, making them more accurate and efficient.
Technical Explanation
The research paper first introduces the concept of tokenization, which is the process of breaking down text into smaller, meaningful units or tokens. The quality of tokenization can have a significant impact on the performance of language models, as it determines how the input text is represented and processed.
To measure the quality of tokenization, the researchers propose using text compression as a proxy. They argue that a more efficient tokenization process should result in a higher compression ratio, as the text can be represented more compactly without losing important information.
The paper then presents experiments that explore the relationship between text compression and model performance. The researchers use various language modeling tasks, such as text generation and question answering, to evaluate the performance of different models. They also measure the compression ratio of the input text for each task and investigate the correlation between compression and model performance.
The key findings of the paper suggest that there is indeed a strong correlation between text compression and model performance. Models that achieve higher compression ratios tend to perform better on the language modeling tasks, indicating that effective tokenization is crucial for the success of these systems.
The paper also delves into the underlying mechanisms that might explain this relationship. It discusses how the compression process can capture important linguistic patterns and structures, which can then be leveraged by the language models to improve their understanding and generation of natural language.
Critical Analysis
The research presented in the paper provides valuable insights into the role of tokenization in language modeling. By focusing on the relationship between text compression and model performance, the authors offer a novel perspective on evaluating the quality of tokenization.
One strength of the study is the use of text compression as a proxy for tokenization quality. This approach is intuitive and aligns with the idea that more efficient tokenization should lead to more compact text representations. The experiments conducted by the researchers provide empirical evidence to support this hypothesis.
However, it is important to note that the paper does not delve deeply into the specific mechanisms underlying the observed correlation. While the authors provide some discussion on how compression can capture linguistic patterns, a more detailed exploration of the theoretical underpinnings could further strengthen the conclusions.
Additionally, the paper acknowledges that the relationship between tokenization and model performance can be influenced by various factors, such as the architecture of the language model and the complexity of the task. Further research may be needed to understand how these factors interact and how they can be optimized to achieve even better language modeling performance.
Conclusion
The research paper presents a thought-provoking investigation into the role of tokenization in language modeling. By focusing on the relationship between text compression and model performance, the authors provide empirical evidence that effective tokenization is crucial for the success of language models.
The findings suggest that optimizing the tokenization process, with the goal of achieving higher compression ratios, could lead to significant improvements in the accuracy and efficiency of language models. This has important implications for the development of more advanced natural language processing systems, which could have far-reaching applications in fields such as machine translation, dialogue systems, and content generation.
Overall, this research contributes to our understanding of the fundamental challenges and opportunities in language modeling, and it highlights the importance of continuing to explore the interplay between the various components that underlie the impressive capabilities of these AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Unpacking Tokenization: Evaluating Text Compression and its Correlation with Model Performance
Omer Goldman, Avi Caciularu, Matan Eyal, Kris Cao, Idan Szpektor, Reut Tsarfaty
Despite it being the cornerstone of BPE, the most common tokenization algorithm, the importance of compression in the tokenization process is still unclear. In this paper, we argue for the theoretical importance of compression, that can be viewed as 0-gram language modeling where equal probability is assigned to all tokens. We also demonstrate the empirical importance of compression for downstream success of pre-trained language models. We control the compression ability of several BPE tokenizers by varying the amount of documents available during their training: from 1 million documents to a character-based tokenizer equivalent to no training data at all. We then pre-train English language models based on those tokenizers and fine-tune them over several tasks. We show that there is a correlation between tokenizers' compression and models' downstream performance, suggesting that compression is a reliable intrinsic indicator of tokenization quality. These correlations are more pronounced for generation tasks (over classification) or for smaller models (over large ones). We replicated a representative part of our experiments on Turkish and found similar results, confirming that our results hold for languages with typological characteristics dissimilar to English. We conclude that building better compressing tokenizers is a fruitful avenue for further research and for improving overall model performance.
Read more6/26/2024
⚙️
0
Toward a Theory of Tokenization in LLMs
Nived Rajaraman, Jiantao Jiao, Kannan Ramchandran
While there has been a large body of research attempting to circumvent tokenization for language modeling (Clark et al., 2022; Xue et al., 2022), the current consensus is that it is a necessary initial step for designing state-of-the-art performant language models. In this paper, we investigate tokenization from a theoretical point of view by studying the behavior of transformers on simple data generating processes. When trained on data drawn from certain simple $k^{text{th}}$-order Markov processes for $k > 1$, transformers exhibit a surprising phenomenon - in the absence of tokenization, they empirically fail to learn the right distribution and predict characters according to a unigram model (Makkuva et al., 2024). With the addition of tokenization, however, we empirically observe that transformers break through this barrier and are able to model the probabilities of sequences drawn from the source near-optimally, achieving small cross-entropy loss. With this observation as starting point, we study the end-to-end cross-entropy loss achieved by transformers with and without tokenization. With the appropriate tokenization, we show that even the simplest unigram models (over tokens) learnt by transformers are able to model the probability of sequences drawn from $k^{text{th}}$-order Markov sources near optimally. Our analysis provides a justification for the use of tokenization in practice through studying the behavior of transformers on Markovian data.
Read more4/15/2024
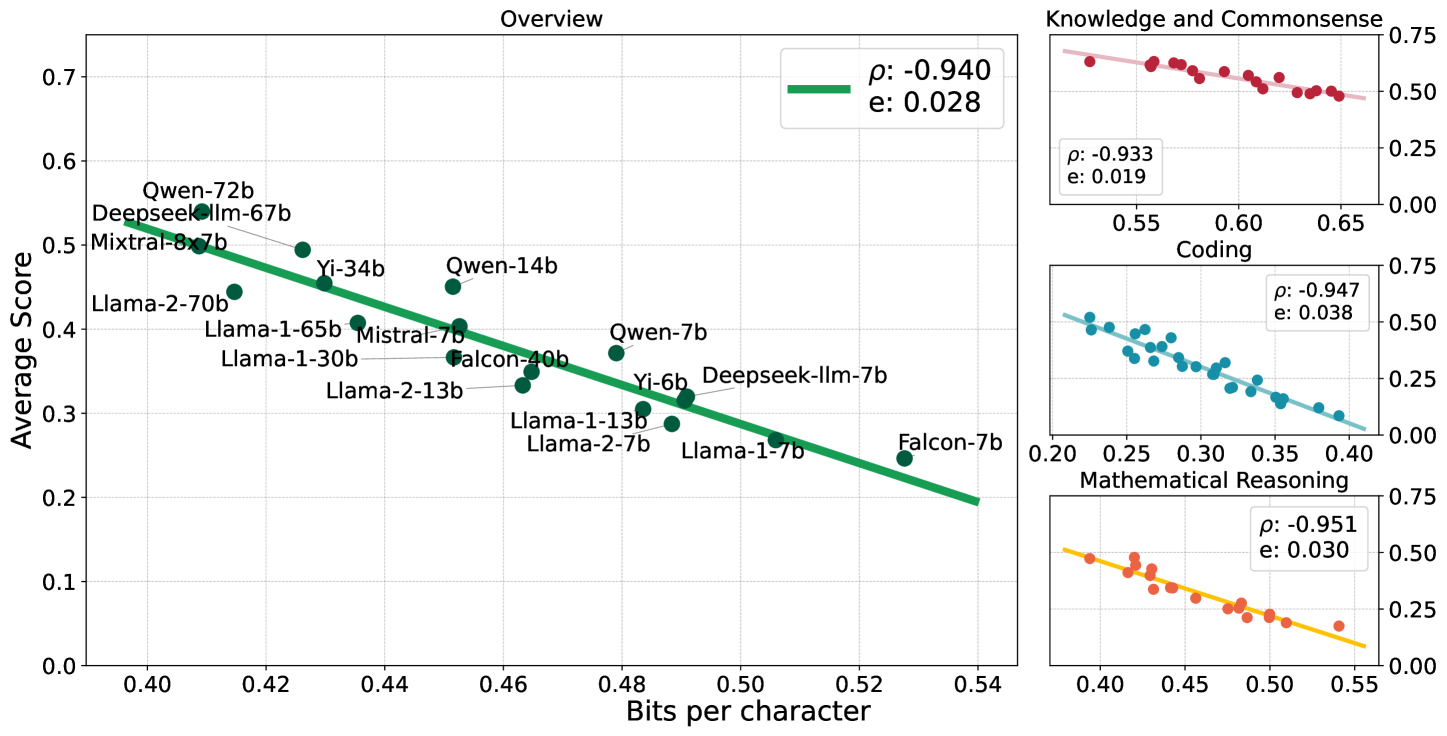
0
Compression Represents Intelligence Linearly
Yuzhen Huang, Jinghan Zhang, Zifei Shan, Junxian He
There is a belief that learning to compress well will lead to intelligence. Recently, language modeling has been shown to be equivalent to compression, which offers a compelling rationale for the success of large language models (LLMs): the development of more advanced language models is essentially enhancing compression which facilitates intelligence. Despite such appealing discussions, little empirical evidence is present for the interplay between compression and intelligence. In this work, we examine their relationship in the context of LLMs, treating LLMs as data compressors. Given the abstract concept of intelligence, we adopt the average downstream benchmark scores as a surrogate, specifically targeting intelligence related to knowledge and commonsense, coding, and mathematical reasoning. Across 12 benchmarks, our study brings together 31 public LLMs that originate from diverse organizations. Remarkably, we find that LLMs' intelligence -- reflected by average benchmark scores -- almost linearly correlates with their ability to compress external text corpora. These results provide concrete evidence supporting the belief that superior compression indicates greater intelligence. Furthermore, our findings suggest that compression efficiency, as an unsupervised metric derived from raw text corpora, serves as a reliable evaluation measure that is linearly associated with the model capabilities. We open-source our compression datasets as well as our data collection pipelines to facilitate future researchers to assess compression properly.
Read more8/20/2024
🏷️
0
Ranking LLMs by compression
Peijia Guo, Ziguang Li, Haibo Hu, Chao Huang, Ming Li, Rui Zhang
We conceptualize the process of understanding as information compression, and propose a method for ranking large language models (LLMs) based on lossless data compression. We demonstrate the equivalence of compression length under arithmetic coding with cumulative negative log probabilities when using a large language model as a prior, that is, the pre-training phase of the model is essentially the process of learning the optimal coding length. At the same time, the evaluation metric compression ratio can be obtained without actual compression, which greatly saves overhead. In this paper, we use five large language models as priors for compression, then compare their performance on challenging natural language processing tasks, including sentence completion, question answering, and coreference resolution. Experimental results show that compression ratio and model performance are positively correlated, so it can be used as a general metric to evaluate large language models.
Read more6/21/2024