DataDreamer: A Tool for Synthetic Data Generation and Reproducible LLM Workflows

0
📊
Sign in to get full access
Overview
- Large language models (LLMs) have become an important tool for natural language processing (NLP) researchers
- Researchers use LLMs for tasks like synthetic data generation, task evaluation, fine-tuning, and distillation
- Challenges arise from the scale of LLMs, their closed-source nature, and lack of standardized tooling
- These challenges have negatively impacted open science and reproducibility of research using LLMs
Plain English Explanation
Large language models (LLMs) are a type of artificial intelligence that can understand and generate human-like text. These powerful models have become a crucial tool for researchers working on natural language processing (NLP) problems. Researchers now commonly use LLMs to create synthetic data, evaluate the performance of NLP systems, fine-tune models for specific tasks, and distill knowledge from large models into smaller, more efficient ones.
However, using LLMs in research comes with its own set of challenges. Because these models are extremely large and complex, they can be difficult to work with. Many LLMs are also closed-source, meaning researchers don't have access to the full details of how they work. Additionally, there's a lack of standardized tools and workflows for integrating LLMs into research projects.
These unique challenges have had a negative impact on the field of open science and the reproducibility of research that uses LLMs. Open science refers to the idea that scientific research should be transparent and accessible to everyone. When researchers use closed-source LLMs, it can be harder for others to verify and build upon their findings.
Technical Explanation
The paper introduces DataDreamer, an open-source Python library that aims to address these challenges. DataDreamer provides researchers with a set of simple, standardized tools for implementing powerful workflows using large language models.
The library helps researchers adhere to best practices that the authors propose to encourage open science and reproducibility. For example, DataDreamer allows researchers to easily save and share the prompts, configurations, and other details needed to replicate their experiments.
The paper also discusses the broader implications of the challenges posed by LLMs, and how the DataDreamer library can help address them. The authors argue that by making it easier to work with LLMs in a transparent and reproducible way, DataDreamer can help support the advancement of open science in the field of NLP.
Critical Analysis
The paper highlights some important challenges that the rapid rise of large language models has created for open science and reproducibility. The authors make a compelling case for the need to develop standardized tooling and best practices to address these issues.
One potential limitation of the research is that it focuses mainly on the use of LLMs in NLP research workflows, and does not explore the broader implications or applications of these models. Additionally, the paper does not provide a detailed evaluation of the DataDreamer library itself, such as its performance, usability, or adoption by the research community.
It would be valuable for future research to explore prompting methods for mitigating class imbalance or adapting open-source large language models to better support open science and reproducibility. Additionally, further research on the use of LLMs in symbolic reasoning could provide insights into how these models can be more effectively integrated into a wider range of research workflows.
Conclusion
In summary, this paper highlights the growing importance of large language models in NLP research, as well as the unique challenges that these models pose for open science and reproducibility. The introduction of the DataDreamer library represents an important step towards addressing these challenges and supporting the advancement of open science in the field of NLP. By providing researchers with standardized tools and best practices for working with LLMs, DataDreamer has the potential to significantly improve the transparency and replicability of NLP research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
0
DataDreamer: A Tool for Synthetic Data Generation and Reproducible LLM Workflows
Ajay Patel, Colin Raffel, Chris Callison-Burch
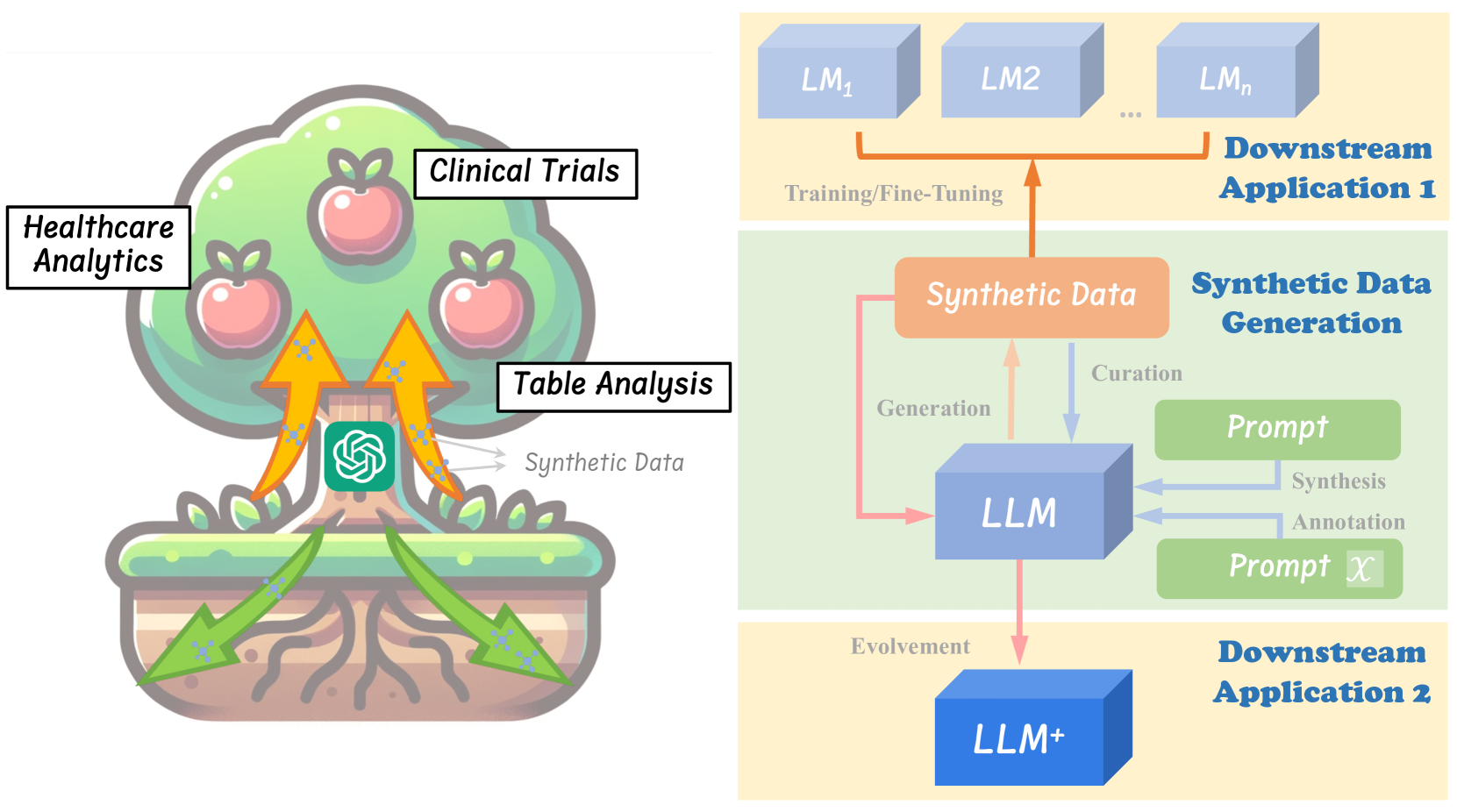
Large language models (LLMs) have become a dominant and important tool for NLP researchers in a wide range of tasks. Today, many researchers use LLMs in synthetic data generation, task evaluation, fine-tuning, distillation, and other model-in-the-loop research workflows. However, challenges arise when using these models that stem from their scale, their closed source nature, and the lack of standardized tooling for these new and emerging workflows. The rapid rise to prominence of these models and these unique challenges has had immediate adverse impacts on open science and on the reproducibility of work that uses them. In this paper, we introduce DataDreamer, an open source Python library that allows researchers to write simple code to implement powerful LLM workflows. DataDreamer also helps researchers adhere to best practices that we propose to encourage open science and reproducibility. The library and documentation are available at https://github.com/datadreamer-dev/DataDreamer .
Read more5/29/2024
0
On LLMs-Driven Synthetic Data Generation, Curation, and Evaluation: A Survey
Lin Long, Rui Wang, Ruixuan Xiao, Junbo Zhao, Xiao Ding, Gang Chen, Haobo Wang
Within the evolving landscape of deep learning, the dilemma of data quantity and quality has been a long-standing problem. The recent advent of Large Language Models (LLMs) offers a data-centric solution to alleviate the limitations of real-world data with synthetic data generation. However, current investigations into this field lack a unified framework and mostly stay on the surface. Therefore, this paper provides an organization of relevant studies based on a generic workflow of synthetic data generation. By doing so, we highlight the gaps within existing research and outline prospective avenues for future study. This work aims to shepherd the academic and industrial communities towards deeper, more methodical inquiries into the capabilities and applications of LLMs-driven synthetic data generation.
Read more6/24/2024

0
DataDream: Few-shot Guided Dataset Generation
Jae Myung Kim, Jessica Bader, Stephan Alaniz, Cordelia Schmid, Zeynep Akata
While text-to-image diffusion models have been shown to achieve state-of-the-art results in image synthesis, they have yet to prove their effectiveness in downstream applications. Previous work has proposed to generate data for image classifier training given limited real data access. However, these methods struggle to generate in-distribution images or depict fine-grained features, thereby hindering the generalization of classification models trained on synthetic datasets. We propose DataDream, a framework for synthesizing classification datasets that more faithfully represents the real data distribution when guided by few-shot examples of the target classes. DataDream fine-tunes LoRA weights for the image generation model on the few real images before generating the training data using the adapted model. We then fine-tune LoRA weights for CLIP using the synthetic data to improve downstream image classification over previous approaches on a large variety of datasets. We demonstrate the efficacy of DataDream through extensive experiments, surpassing state-of-the-art classification accuracy with few-shot data across 7 out of 10 datasets, while being competitive on the other 3. Additionally, we provide insights into the impact of various factors, such as the number of real-shot and generated images as well as the fine-tuning compute on model performance. The code is available at https://github.com/ExplainableML/DataDream.
Read more7/17/2024
🛸
0
LLMs for Science: Usage for Code Generation and Data Analysis
Mohamed Nejjar, Luca Zacharias, Fabian Stiehle, Ingo Weber
Large language models (LLMs) have been touted to enable increased productivity in many areas of today's work life. Scientific research as an area of work is no exception: the potential of LLM-based tools to assist in the daily work of scientists has become a highly discussed topic across disciplines. However, we are only at the very onset of this subject of study. It is still unclear how the potential of LLMs will materialise in research practice. With this study, we give first empirical evidence on the use of LLMs in the research process. We have investigated a set of use cases for LLM-based tools in scientific research, and conducted a first study to assess to which degree current tools are helpful. In this paper we report specifically on use cases related to software engineering, such as generating application code and developing scripts for data analytics. While we studied seemingly simple use cases, results across tools differ significantly. Our results highlight the promise of LLM-based tools in general, yet we also observe various issues, particularly regarding the integrity of the output these tools provide.
Read more4/24/2024