On LLMs-Driven Synthetic Data Generation, Curation, and Evaluation: A Survey
2406.15126
0
0
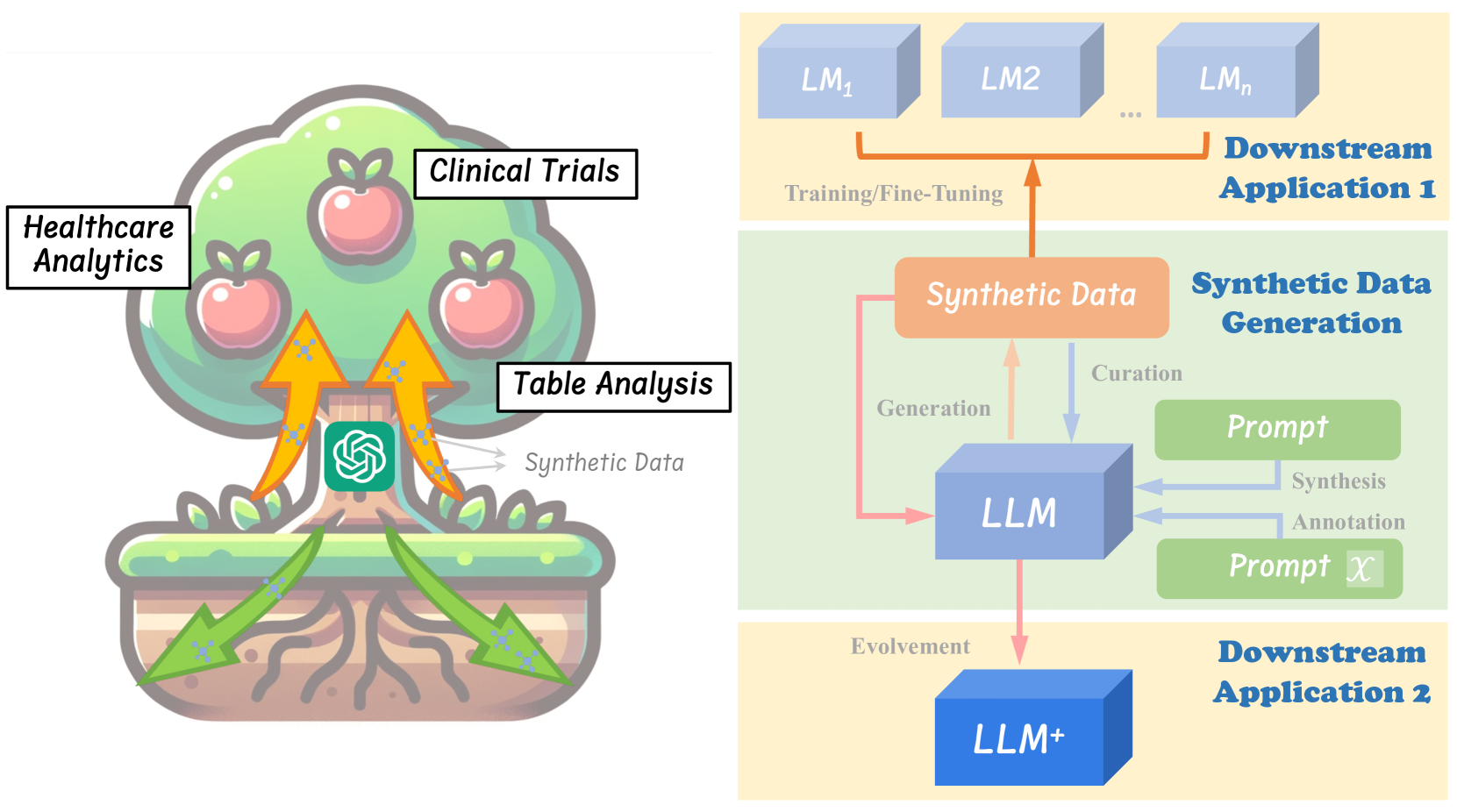
Abstract
Within the evolving landscape of deep learning, the dilemma of data quantity and quality has been a long-standing problem. The recent advent of Large Language Models (LLMs) offers a data-centric solution to alleviate the limitations of real-world data with synthetic data generation. However, current investigations into this field lack a unified framework and mostly stay on the surface. Therefore, this paper provides an organization of relevant studies based on a generic workflow of synthetic data generation. By doing so, we highlight the gaps within existing research and outline prospective avenues for future study. This work aims to shepherd the academic and industrial communities towards deeper, more methodical inquiries into the capabilities and applications of LLMs-driven synthetic data generation.
Create account to get full access
Overview
- This paper provides a comprehensive survey on the use of large language models (LLMs) for synthetic data generation, curation, and evaluation.
- It explores the current state of the art, highlighting key research trends, best practices, and lessons learned in this rapidly evolving field.
- The paper covers a wide range of applications, from tabular data generation to code synthesis, and discusses the multi-faceted evaluation frameworks used to assess the quality and utility of LLM-generated synthetic data.
Plain English Explanation
This paper examines how advanced AI language models, called large language models (LLMs), are being used to create artificial or "synthetic" data. Synthetic data can be a valuable tool for tasks like training machine learning models, testing software, or conducting research, especially when real-world data is scarce or sensitive.
The paper outlines the current state of the art in using LLMs for synthetic data generation, curation, and evaluation. It highlights the key research trends and best practices in this rapidly evolving field. For example, the paper discusses multi-faceted evaluation frameworks that are used to assess the quality and usefulness of the synthetic data generated by LLMs.
The paper covers a wide range of applications, from generating synthetic tabular data to synthesizing computer code. It explores the strengths and limitations of LLMs in these different domains, and discusses the lessons learned from researchers working at the forefront of this technology.
Overall, the paper provides a comprehensive overview of how LLMs are transforming the way we think about data generation and curation, with important implications for a wide range of industries and research areas.
Technical Explanation
The paper begins by providing an introduction to the field of synthetic data generation, highlighting the growing importance of LLMs in this domain. It then delves into the preliminaries, discussing the key concepts and techniques underlying LLM-driven synthetic data generation.
The core of the paper focuses on surveying the state of the art in this field. It examines various use cases, such as tabular data generation, text synthesis, and code synthesis, exploring the strengths and limitations of LLMs in each domain. The paper also reviews the multi-faceted evaluation frameworks that researchers have developed to assess the quality and utility of the synthetic data produced by LLMs.
Throughout the survey, the paper highlights the best practices and lessons learned from researchers working in this field. It discusses the importance of careful data curation, the need for robust evaluation metrics, and the challenges of scaling LLM-based synthetic data generation to larger and more complex datasets.
The paper concludes by discussing the broader implications of LLM-driven synthetic data generation, including its potential impact on various industries and research areas, as well as the ethical considerations that must be addressed as this technology continues to evolve.
Critical Analysis
The paper provides a comprehensive and well-researched overview of the current state of LLM-driven synthetic data generation, curation, and evaluation. The authors have done an excellent job of synthesizing the key research trends and best practices in this rapidly evolving field.
One potential limitation of the paper is its broad scope, which may leave some readers wishing for more in-depth discussion of specific use cases or technical approaches. However, the authors have done a commendable job of balancing breadth and depth, providing enough detail to give readers a solid understanding of the field while also highlighting important areas for further research and development.
The paper's multi-faceted evaluation framework is a particularly notable contribution, as it underscores the importance of holistic assessment when it comes to synthetic data. By considering factors such as realism, diversity, and utility, this framework can help guide researchers and practitioners in developing more robust and impactful synthetic data solutions.
That said, the paper could have delved deeper into the ethical implications of LLM-driven synthetic data generation, especially as it relates to issues like bias, privacy, and the potential misuse of this technology. As the use of synthetic data continues to grow, it will be crucial for the research community to grapple with these complex questions.
Overall, this paper is a valuable resource for anyone interested in the current state of LLM-driven synthetic data generation, and it lays the groundwork for further research and innovation in this important and rapidly evolving field.
Conclusion
This comprehensive survey paper provides a detailed overview of the use of large language models (LLMs) for synthetic data generation, curation, and evaluation. The authors have done an excellent job of synthesizing the key research trends, best practices, and lessons learned in this rapidly evolving field.
The paper covers a wide range of applications, from tabular data generation to code synthesis, and discusses the multi-faceted evaluation frameworks used to assess the quality and utility of LLM-generated synthetic data. The authors have also highlighted the broader implications of this technology, including its potential impact on various industries and research areas, as well as the ethical considerations that must be addressed.
Overall, this paper is a valuable resource for anyone interested in the current state of LLM-driven synthetic data generation, and it lays the groundwork for further research and innovation in this important and rapidly evolving field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Curated LLM: Synergy of LLMs and Data Curation for tabular augmentation in low-data regimes
Nabeel Seedat, Nicolas Huynh, Boris van Breugel, Mihaela van der Schaar
0
0
Machine Learning (ML) in low-data settings remains an underappreciated yet crucial problem. Hence, data augmentation methods to increase the sample size of datasets needed for ML are key to unlocking the transformative potential of ML in data-deprived regions and domains. Unfortunately, the limited training set constrains traditional tabular synthetic data generators in their ability to generate a large and diverse augmented dataset needed for ML tasks. To address this challenge, we introduce CLLM, which leverages the prior knowledge of Large Language Models (LLMs) for data augmentation in the low-data regime. However, not all the data generated by LLMs will improve downstream utility, as for any generative model. Consequently, we introduce a principled curation mechanism, leveraging learning dynamics, coupled with confidence and uncertainty metrics, to obtain a high-quality dataset. Empirically, on multiple real-world datasets, we demonstrate the superior performance of CLLM in the low-data regime compared to conventional generators. Additionally, we provide insights into the LLM generation and curation mechanism, shedding light on the features that enable them to output high-quality augmented datasets.
7/2/2024

Best Practices and Lessons Learned on Synthetic Data for Language Models
Ruibo Liu, Jerry Wei, Fangyu Liu, Chenglei Si, Yanzhe Zhang, Jinmeng Rao, Steven Zheng, Daiyi Peng, Diyi Yang, Denny Zhou, Andrew M. Dai
0
0
The success of AI models relies on the availability of large, diverse, and high-quality datasets, which can be challenging to obtain due to data scarcity, privacy concerns, and high costs. Synthetic data has emerged as a promising solution by generating artificial data that mimics real-world patterns. This paper provides an overview of synthetic data research, discussing its applications, challenges, and future directions. We present empirical evidence from prior art to demonstrate its effectiveness and highlight the importance of ensuring its factuality, fidelity, and unbiasedness. We emphasize the need for responsible use of synthetic data to build more powerful, inclusive, and trustworthy language models.
4/12/2024
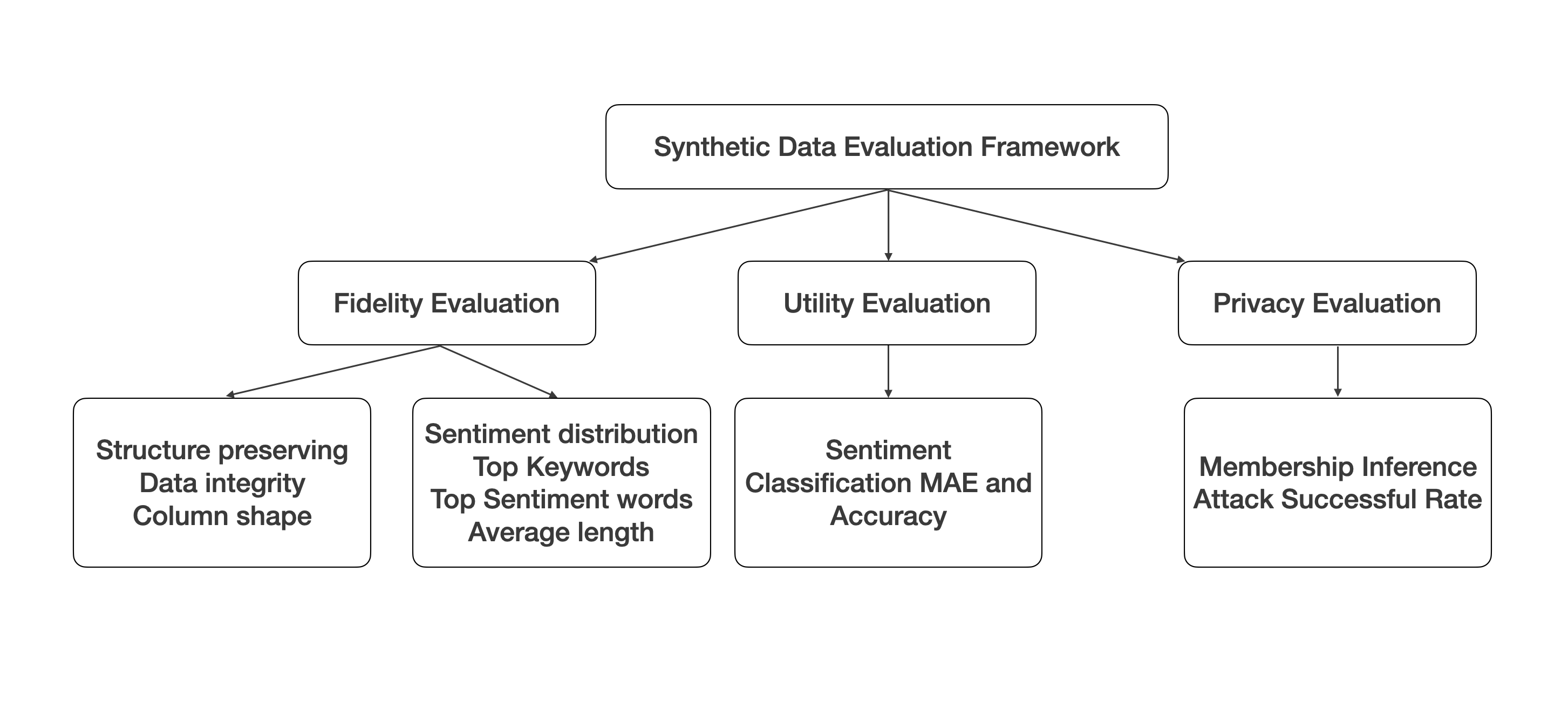
A Multi-Faceted Evaluation Framework for Assessing Synthetic Data Generated by Large Language Models
Yefeng Yuan, Yuhong Liu, Liang Cheng
0
0
The rapid advancements in generative AI and large language models (LLMs) have opened up new avenues for producing synthetic data, particularly in the realm of structured tabular formats, such as product reviews. Despite the potential benefits, concerns regarding privacy leakage have surfaced, especially when personal information is utilized in the training datasets. In addition, there is an absence of a comprehensive evaluation framework capable of quantitatively measuring the quality of the generated synthetic data and their utility for downstream tasks. In response to this gap, we introduce SynEval, an open-source evaluation framework designed to assess the fidelity, utility, and privacy preservation of synthetically generated tabular data via a suite of diverse evaluation metrics. We validate the efficacy of our proposed framework - SynEval - by applying it to synthetic product review data generated by three state-of-the-art LLMs: ChatGPT, Claude, and Llama. Our experimental findings illuminate the trade-offs between various evaluation metrics in the context of synthetic data generation. Furthermore, SynEval stands as a critical instrument for researchers and practitioners engaged with synthetic tabular data,, empowering them to judiciously determine the suitability of the generated data for their specific applications, with an emphasis on upholding user privacy.
4/24/2024
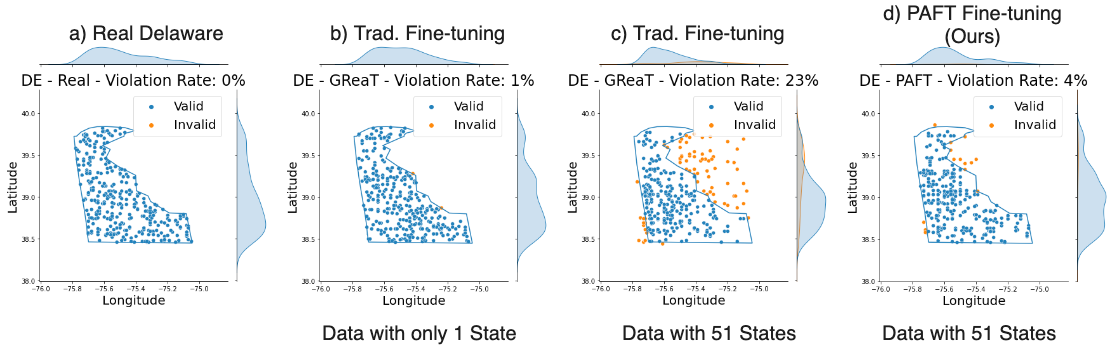
Are LLMs Naturally Good at Synthetic Tabular Data Generation?
Shengzhe Xu, Cho-Ting Lee, Mandar Sharma, Raquib Bin Yousuf, Nikhil Muralidhar, Naren Ramakrishnan
0
0
Large language models (LLMs) have demonstrated their prowess in generating synthetic text and images; however, their potential for generating tabular data -- arguably the most common data type in business and scientific applications -- is largely underexplored. This paper demonstrates that LLMs, used as-is, or after traditional fine-tuning, are severely inadequate as synthetic table generators. Due to the autoregressive nature of LLMs, fine-tuning with random order permutation runs counter to the importance of modeling functional dependencies, and renders LLMs unable to model conditional mixtures of distributions (key to capturing real world constraints). We showcase how LLMs can be made to overcome some of these deficiencies by making them permutation-aware.
6/24/2024