DataGpt-SQL-7B: An Open-Source Language Model for Text-to-SQL

0
Sign in to get full access
Overview
- DataGpt-SQL-7B is an open-source language model designed for text-to-SQL tasks
- It aims to improve upon existing text-to-SQL models by leveraging a large language model trained on diverse data
- The paper describes the model architecture, training, and evaluation on various benchmarks
Plain English Explanation
The paper presents DataGpt-SQL-7B, an open-source language model designed to translate natural language queries into SQL queries. Text-to-SQL is a challenging task that requires understanding the structure and semantics of both natural language and SQL.
The researchers developed DataGpt-SQL-7B by fine-tuning a large language model (specifically, GPT-3) on a diverse dataset of SQL queries and natural language descriptions. This allows the model to leverage the broad knowledge and language understanding capabilities of the large language model, while specializing it for the specific task of text-to-SQL conversion.
The paper evaluates DataGpt-SQL-7B on several standard benchmarks for text-to-SQL, showing that it achieves state-of-the-art performance. This suggests that the approach of using a powerful language model as a foundation and fine-tuning it for the text-to-SQL task is an effective way to build high-performing models for this problem.
Technical Explanation
The DataGpt-SQL-7B model is built on top of the GPT-3 language model, which was pre-trained on a large corpus of text data. The researchers then fine-tuned this model on a dataset of natural language descriptions and corresponding SQL queries, allowing the model to learn the mapping between natural language and SQL.
The model architecture follows a standard encoder-decoder structure, with the GPT-3 model serving as the encoder to encode the natural language input, and a custom decoder module to generate the output SQL query. The model was trained using techniques like data augmentation and multi-task learning to improve its performance on the text-to-SQL task.
The researchers evaluated DataGpt-SQL-7B on several benchmark datasets for text-to-SQL, including Spider, WikiSQL, and others. They found that DataGpt-SQL-7B outperformed previous state-of-the-art models on these benchmarks, demonstrating the effectiveness of their approach.
Critical Analysis
The DataGpt-SQL-7B paper presents a promising approach to building high-performing text-to-SQL models. The use of a large language model like GPT-3 as a foundation and fine-tuning it for the specific task seems to be a effective strategy.
However, the paper does not discuss the potential limitations or caveats of this approach. For example, the model may still struggle with complex SQL queries or edge cases not covered in the training data. Additionally, the performance of the model may be heavily dependent on the quality and diversity of the training data used for fine-tuning.
Further research is needed to explore the robustness and generalizability of the DataGpt-SQL-7B model, as well as potential ways to enhance its capabilities. Incorporating more advanced techniques like few-shot learning or meta-learning could be an interesting direction for future work.
Conclusion
The DataGpt-SQL-7B paper presents an open-source text-to-SQL model that leverages a large language model (GPT-3) to achieve state-of-the-art performance on several benchmarks. This approach of using a powerful pre-trained model as a foundation and fine-tuning it for a specific task shows promise for building high-performing AI systems.
The availability of an open-source model like DataGpt-SQL-7B can help accelerate research and development in the field of natural language interfaces for databases, potentially leading to improved user experiences and more efficient data management. As the authors note, further research is needed to explore the limits and potential enhancements of this approach, but this work represents an important step forward.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
DataGpt-SQL-7B: An Open-Source Language Model for Text-to-SQL
Lixia Wu, Peng Li, Junhong Lou, Lei Fu
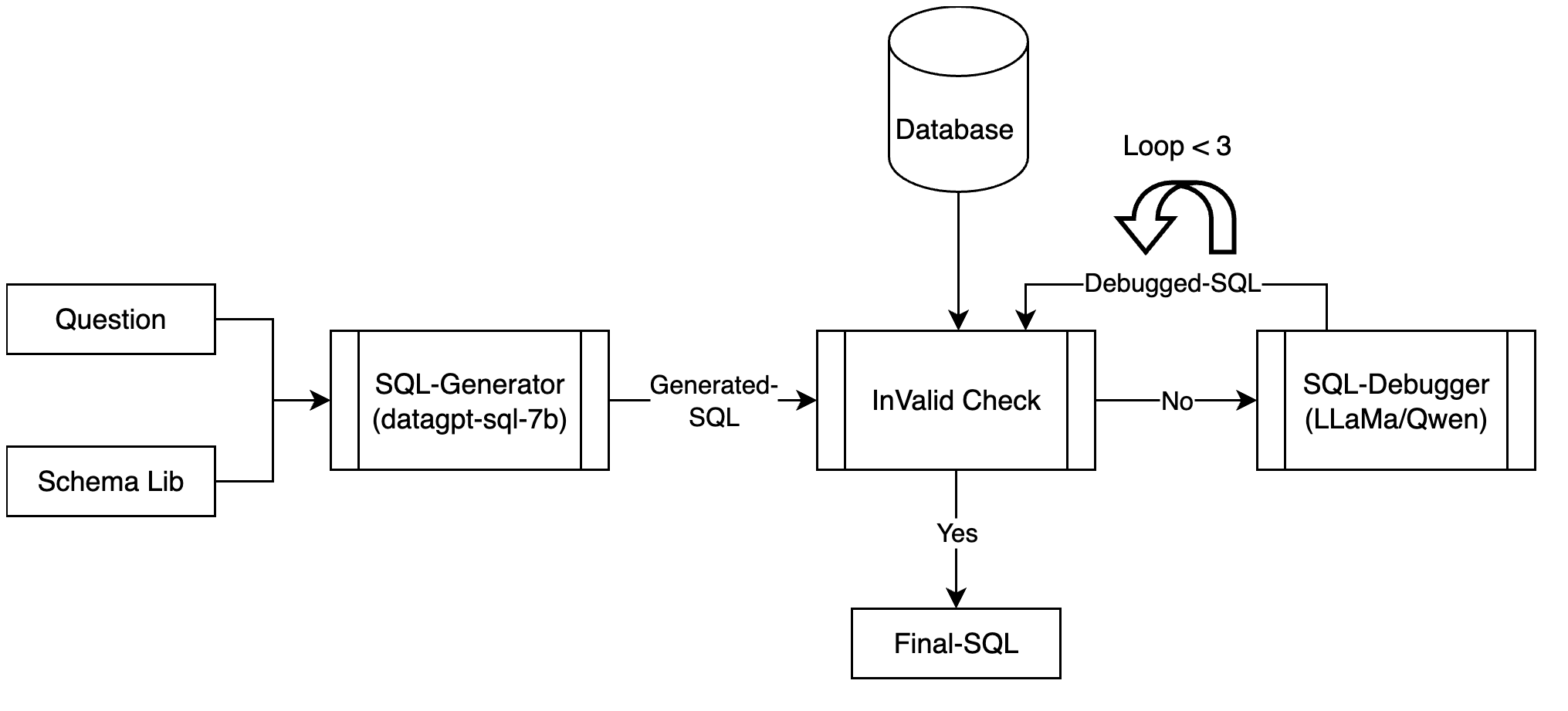
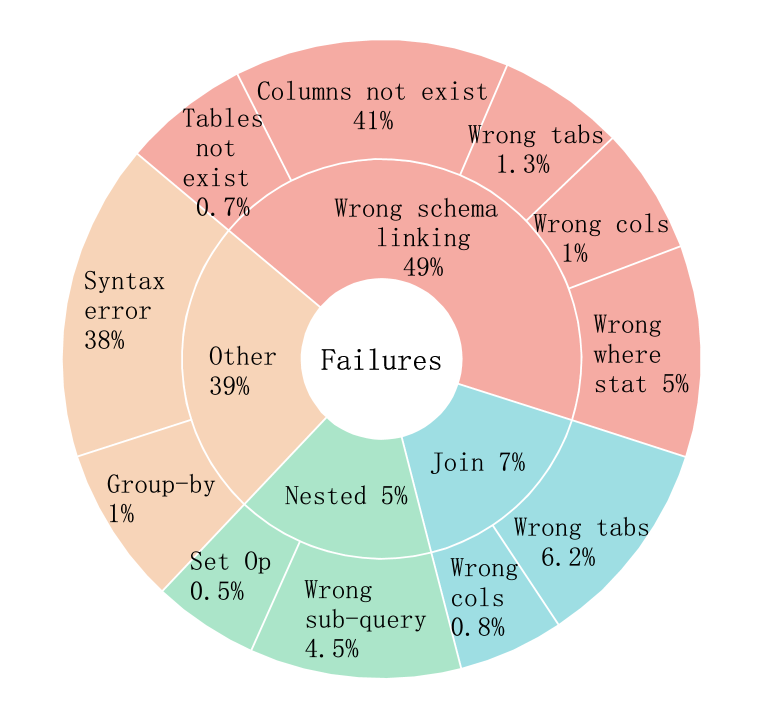
In addressing the pivotal role of translating natural language queries into SQL commands, we propose a suite of compact, fine-tuned models and self-refine mechanisms to democratize data access and analysis for non-expert users, mitigating risks associated with closed-source Large Language Models. Specifically, we constructed a dataset of over 20K sample for Text-to-SQL as well as the preference dateset, to improve the efficiency in the domain of SQL generation. To further ensure code validity, a code corrector was integrated into the model. Our system, DataGpt-sql, achieved 87.2% accuracy on the spider-dev, respectively, showcasing the effectiveness of our solution in text-to-SQL conversion tasks. Our code, data, and models are available at url{https://github.com/CainiaoTechAi/datagpt-sql-7b}
Read more9/25/2024
0
Open-SQL Framework: Enhancing Text-to-SQL on Open-source Large Language Models
Xiaojun Chen, Tianle Wang, Tianhao Qiu, Jianbin Qin, Min Yang
Despite the success of large language models (LLMs) in Text-to-SQL tasks, open-source LLMs encounter challenges in contextual understanding and response coherence. To tackle these issues, we present ours, a systematic methodology tailored for Text-to-SQL with open-source LLMs. Our contributions include a comprehensive evaluation of open-source LLMs in Text-to-SQL tasks, the openprompt strategy for effective question representation, and novel strategies for supervised fine-tuning. We explore the benefits of Chain-of-Thought in step-by-step inference and propose the openexample method for enhanced few-shot learning. Additionally, we introduce token-efficient techniques, such as textbf{Variable-length Open DB Schema}, textbf{Target Column Truncation}, and textbf{Example Column Truncation}, addressing challenges in large-scale databases. Our findings emphasize the need for further investigation into the impact of supervised fine-tuning on contextual learning capabilities. Remarkably, our method significantly improved Llama2-7B from 2.54% to 41.04% and Code Llama-7B from 14.54% to 48.24% on the BIRD-Dev dataset. Notably, the performance of Code Llama-7B surpassed GPT-4 (46.35%) on the BIRD-Dev dataset.
Read more5/14/2024
0
Demonstration of DB-GPT: Next Generation Data Interaction System Empowered by Large Language Models
Siqiao Xue, Danrui Qi, Caigao Jiang, Wenhui Shi, Fangyin Cheng, Keting Chen, Hongjun Yang, Zhiping Zhang, Jianshan He, Hongyang Zhang, Ganglin Wei, Wang Zhao, Fan Zhou, Hong Yi, Shaodong Liu, Hongjun Yang, Faqiang Chen
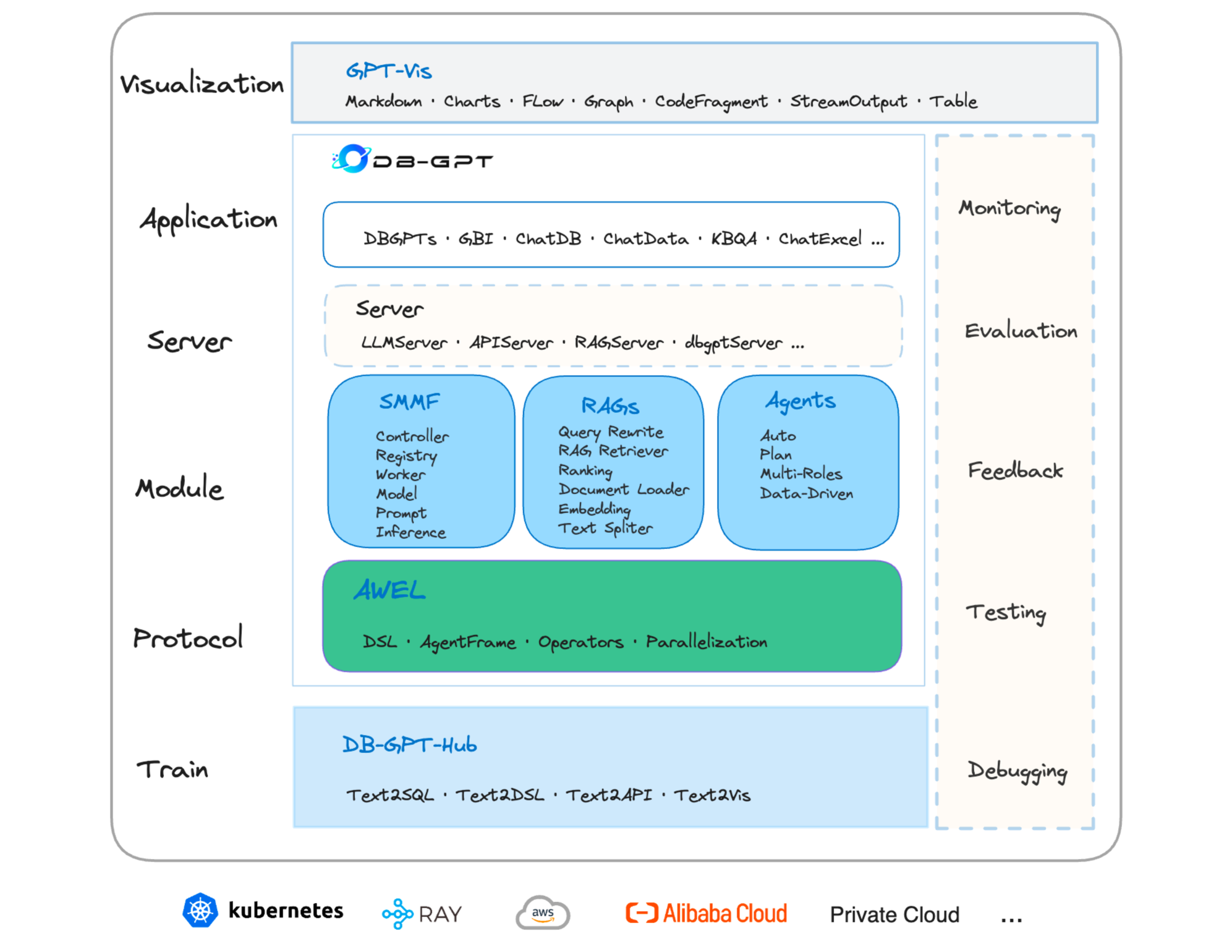
The recent breakthroughs in large language models (LLMs) are positioned to transition many areas of software. The technologies of interacting with data particularly have an important entanglement with LLMs as efficient and intuitive data interactions are paramount. In this paper, we present DB-GPT, a revolutionary and product-ready Python library that integrates LLMs into traditional data interaction tasks to enhance user experience and accessibility. DB-GPT is designed to understand data interaction tasks described by natural language and provide context-aware responses powered by LLMs, making it an indispensable tool for users ranging from novice to expert. Its system design supports deployment across local, distributed, and cloud environments. Beyond handling basic data interaction tasks like Text-to-SQL with LLMs, it can handle complex tasks like generative data analysis through a Multi-Agents framework and the Agentic Workflow Expression Language (AWEL). The Service-oriented Multi-model Management Framework (SMMF) ensures data privacy and security, enabling users to employ DB-GPT with private LLMs. Additionally, DB-GPT offers a series of product-ready features designed to enable users to integrate DB-GPT within their product environments easily. The code of DB-GPT is available at Github(https://github.com/eosphoros-ai/DB-GPT) which already has over 10.7k stars. Please install DB-GPT for your own usage with the instructions(https://github.com/eosphoros-ai/DB-GPT#install) and watch a 5-minute introduction video on Youtube(https://youtu.be/n_8RI1ENyl4) to further investigate DB-GPT.
Read more4/26/2024

0
A Survey on Employing Large Language Models for Text-to-SQL Tasks
Liang Shi, Zhengju Tang, Nan Zhang, Xiaotong Zhang, Zhi Yang
The increasing volume of data stored in relational databases has led to the need for efficient querying and utilization of this data in various sectors. However, writing SQL queries requires specialized knowledge, which poses a challenge for non-professional users trying to access and query databases. Text-to-SQL parsing solves this issue by converting natural language queries into SQL queries, thus making database access more accessible for non-expert users. To take advantage of the recent developments in Large Language Models (LLMs), a range of new methods have emerged, with a primary focus on prompt engineering and fine-tuning. This survey provides a comprehensive overview of LLMs in text-to-SQL tasks, discussing benchmark datasets, prompt engineering, fine-tuning methods, and future research directions. We hope this review will enable readers to gain a broader understanding of the recent advances in this field and offer some insights into its future trajectory.
Read more9/10/2024