A Survey on Employing Large Language Models for Text-to-SQL Tasks

0

Sign in to get full access
Overview
- This paper provides a comprehensive survey on the use of large language models (LLMs) for text-to-SQL tasks.
- The authors explore various approaches, including prompt engineering and fine-tuning, that leverage LLMs to translate natural language questions into SQL queries.
- The survey covers the key challenges, recent advancements, and potential future directions in this field.
Plain English Explanation
Large Language Models
Large language models are powerful AI systems that have been trained on massive amounts of text data. These models can understand and generate human-like language, making them well-suited for tasks like translating natural language questions into computer-readable SQL queries.
Text-to-SQL Tasks
Text-to-SQL tasks involve converting natural language questions, such as "Show me the sales for the last quarter," into SQL queries that can be executed on a database. This is a challenging problem that requires understanding the user's intent and mapping it to the appropriate database schema and SQL syntax.
Prompt Engineering
Prompt engineering refers to the process of crafting the input prompts that are fed into the LLM to generate the desired output, in this case, the SQL query. Effective prompt engineering can greatly improve the performance of LLMs on text-to-SQL tasks.
Fine-tuning
Fine-tuning is the process of further training an LLM on a specific task or dataset to improve its performance. In the context of text-to-SQL, fine-tuning the LLM on a dataset of natural language questions and their corresponding SQL queries can help the model better understand and translate between the two domains.
Technical Explanation
The paper discusses several key approaches for employing LLMs in text-to-SQL tasks:
-
Prompt Engineering: The authors explore various prompt engineering techniques, such as incorporating database schema information, breaking down the translation process into multiple steps, and using task-specific prompts, to improve the performance of LLMs on text-to-SQL tasks.
-
Fine-tuning: The survey covers recent advancements in fine-tuning LLMs on text-to-SQL datasets, which can help the models better understand the mapping between natural language and SQL syntax.
-
Hybrid Approaches: The paper also discusses hybrid approaches that combine LLMs with other techniques, such as retrieval-based methods or logical reasoning, to further enhance the performance and interpretability of text-to-SQL systems.
The authors also highlight the key challenges in this field, such as handling complex SQL queries, dealing with ambiguous or underspecified natural language inputs, and ensuring the faithfulness and correctness of the generated SQL queries.
Critical Analysis
The paper provides a comprehensive overview of the state-of-the-art in employing LLMs for text-to-SQL tasks, but it also acknowledges several limitations and areas for further research:
- The performance of LLM-based text-to-SQL systems can still be inconsistent, especially for complex queries or edge cases.
- Interpretability and explainability of the LLM's reasoning process remain challenging, making it difficult to understand and debug the system's behavior.
- The reliance on large, high-quality training datasets for fine-tuning LLMs may limit the applicability of these approaches in scenarios with limited data.
The authors suggest that future research should focus on improving the robustness, generalization, and transparency of LLM-based text-to-SQL systems, as well as exploring ways to incorporate domain-specific knowledge and reasoning capabilities into these models.
Conclusion
This survey paper offers a detailed exploration of the use of large language models for text-to-SQL tasks, highlighting the various approaches, challenges, and potential future directions in this field. The insights provided can help researchers and practitioners better understand the current state of the art and inform the development of more advanced, reliable, and interpretable text-to-SQL systems powered by LLMs.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
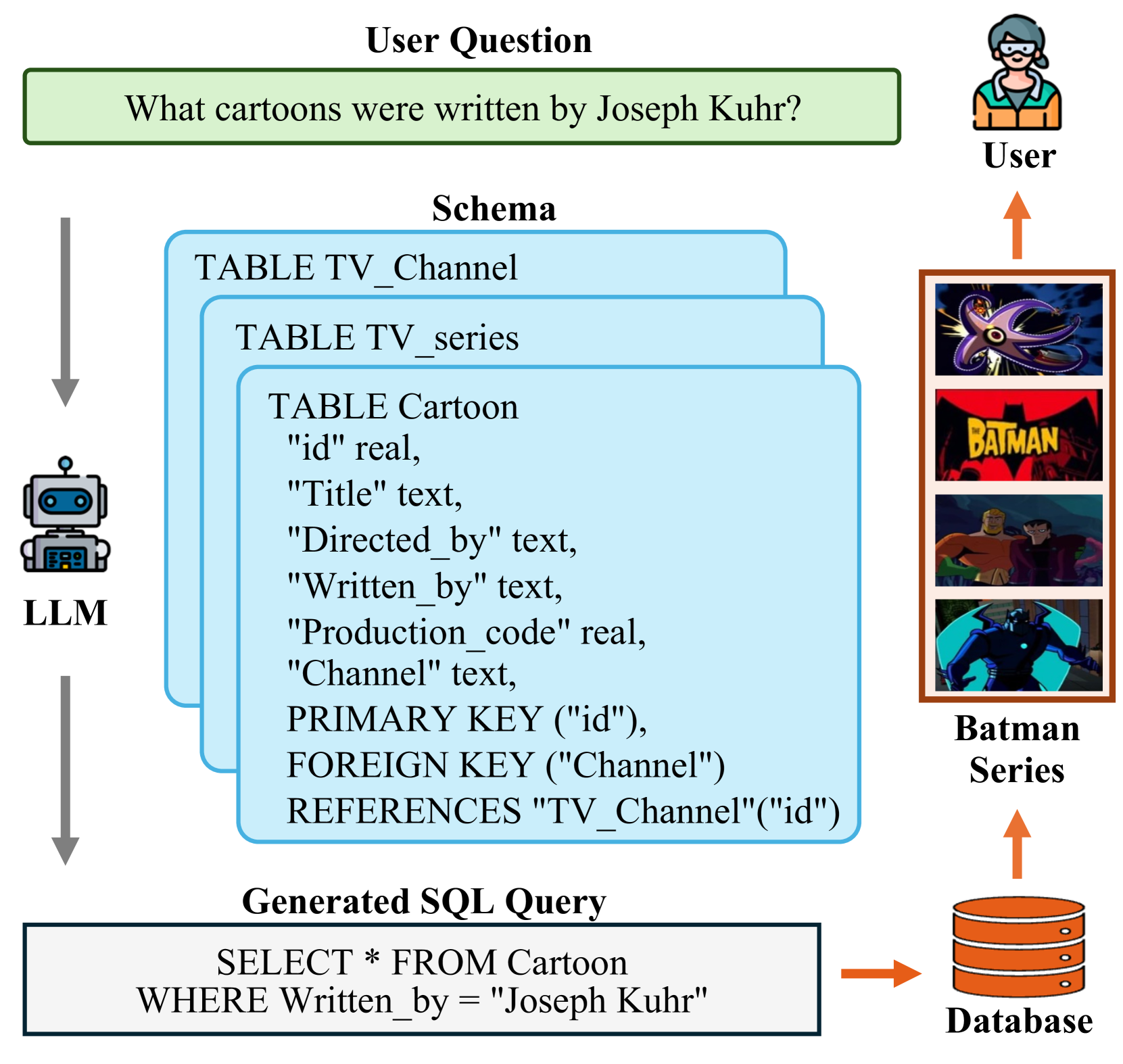
A Survey on Employing Large Language Models for Text-to-SQL Tasks
Liang Shi, Zhengju Tang, Nan Zhang, Xiaotong Zhang, Zhi Yang
The increasing volume of data stored in relational databases has led to the need for efficient querying and utilization of this data in various sectors. However, writing SQL queries requires specialized knowledge, which poses a challenge for non-professional users trying to access and query databases. Text-to-SQL parsing solves this issue by converting natural language queries into SQL queries, thus making database access more accessible for non-expert users. To take advantage of the recent developments in Large Language Models (LLMs), a range of new methods have emerged, with a primary focus on prompt engineering and fine-tuning. This survey provides a comprehensive overview of LLMs in text-to-SQL tasks, discussing benchmark datasets, prompt engineering, fine-tuning methods, and future research directions. We hope this review will enable readers to gain a broader understanding of the recent advances in this field and offer some insights into its future trajectory.
Read more9/10/2024
0
Next-Generation Database Interfaces: A Survey of LLM-based Text-to-SQL
Zijin Hong, Zheng Yuan, Qinggang Zhang, Hao Chen, Junnan Dong, Feiran Huang, Xiao Huang
Generating accurate SQL from natural language questions (text-to-SQL) is a long-standing challenge due to the complexities in user question understanding, database schema comprehension, and SQL generation. Conventional text-to-SQL systems, comprising human engineering and deep neural networks, have made substantial progress. Subsequently, pre-trained language models (PLMs) have been developed and utilized for text-to-SQL tasks, achieving promising performance. As modern databases become more complex, the corresponding user questions also grow more challenging, causing PLMs with parameter constraints to produce incorrect SQL. This necessitates more sophisticated and tailored optimization methods, which, in turn, restricts the applications of PLM-based systems. Recently, large language models (LLMs) have demonstrated significant capabilities in natural language understanding as the model scale increases. Therefore, integrating LLM-based implementation can bring unique opportunities, improvements, and solutions to text-to-SQL research. In this survey, we present a comprehensive review of LLM-based text-to-SQL. Specifically, we propose a brief overview of the technical challenges and the evolutionary process of text-to-SQL. Then, we provide a detailed introduction to the datasets and metrics designed to evaluate text-to-SQL systems. After that, we present a systematic analysis of recent advances in LLM-based text-to-SQL. Finally, we discuss the remaining challenges in this field and propose expectations for future research directions.
Read more7/17/2024
0
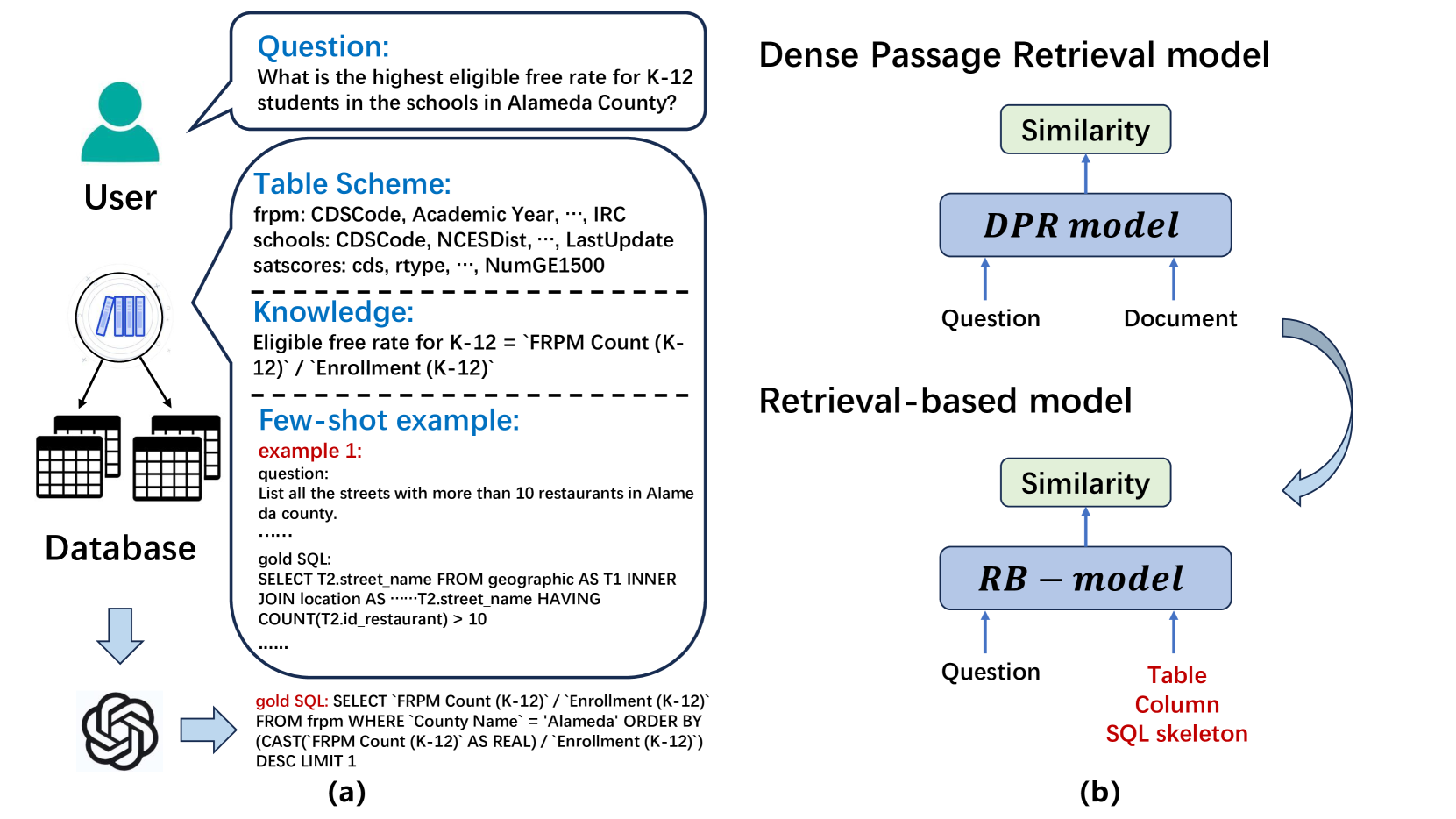
RB-SQL: A Retrieval-based LLM Framework for Text-to-SQL
Zhenhe Wu, Zhongqiu Li, Jie Zhang, Mengxiang Li, Yu Zhao, Ruiyu Fang, Zhongjiang He, Xuelong Li, Zhoujun Li, Shuangyong Song
Large language models (LLMs) with in-context learning have significantly improved the performance of text-to-SQL task. Previous works generally focus on using exclusive SQL generation prompt to improve the LLMs' reasoning ability. However, they are mostly hard to handle large databases with numerous tables and columns, and usually ignore the significance of pre-processing database and extracting valuable information for more efficient prompt engineering. Based on above analysis, we propose RB-SQL, a novel retrieval-based LLM framework for in-context prompt engineering, which consists of three modules that retrieve concise tables and columns as schema, and targeted examples for in-context learning. Experiment results demonstrate that our model achieves better performance than several competitive baselines on public datasets BIRD and Spider.
Read more7/15/2024

0
Large Language Model for Table Processing: A Survey
Weizheng Lu, Jing Zhang, Ju Fan, Zihao Fu, Yueguo Chen, Xiaoyong Du
Tables, typically two-dimensional and structured to store large amounts of data, are essential in daily activities like database queries, spreadsheet manipulations, web table question answering, and image table information extraction. Automating these table-centric tasks with Large Language Models (LLMs) or Visual Language Models (VLMs) offers significant public benefits, garnering interest from academia and industry. This survey provides a comprehensive overview of table-related tasks, examining both user scenarios and technical aspects. It covers traditional tasks like table question answering as well as emerging fields such as spreadsheet manipulation and table data analysis. We summarize the training techniques for LLMs and VLMs tailored for table processing. Additionally, we discuss prompt engineering, particularly the use of LLM-powered agents, for various table-related tasks. Finally, we highlight several challenges, including processing implicit user intentions and extracting information from various table sources.
Read more7/29/2024