DDK: Distilling Domain Knowledge for Efficient Large Language Models

0
Sign in to get full access
Overview
- The paper "DDK: Distilling Domain Knowledge for Efficient Large Language Models" examines ways to reduce the size and improve the efficiency of large language models.
- The key idea is to "distill" or extract the essential domain-specific knowledge from a large pre-trained model and transfer it to a smaller, more efficient model.
- This could enable the deployment of high-performing language models on resource-constrained devices like mobile phones or edge devices.
Plain English Explanation
Large language models like GPT-3 are incredibly powerful, but they can also be massive in size, requiring a lot of computational resources to run. This makes them difficult to deploy on devices with limited processing power, like smartphones or Internet of Things (IoT) devices.
The researchers in this paper developed a technique called "Domain Knowledge Distillation" (DDK) to address this problem. The basic idea is to take the knowledge learned by a large, powerful language model and "distill" it down into a smaller, more efficient model that can run on lower-powered hardware.
The key steps are:
- Train a large, high-performing language model on a broad dataset to give it general language understanding capabilities.
- Identify specific domains or tasks that this model is good at, like answering questions about science or generating creative stories.
- Use a process called "knowledge distillation" to transfer the model's expertise in those domains to a smaller, lightweight model.
The result is a compact model that retains much of the original's capability, but requires far less computational power to run. This could enable deploying high-quality language AI on devices like smartphones, consumer electronics, or edge computing hardware, where the larger models would be too resource-intensive.
The researchers demonstrate the effectiveness of their approach through experiments on several language tasks, showing they can achieve strong performance with much smaller and more efficient models.
Technical Explanation
The paper proposes a technique called "Domain Knowledge Distillation" (DDK) to distill the domain-specific knowledge from a large pre-trained language model into a smaller, more efficient model.
The key steps are:
-
Pre-training a Large Language Model: The authors start by pre-training a large, high-capacity language model (the "teacher" model) on a broad dataset to give it strong general language understanding capabilities.
-
Identifying Relevant Domains: They then identify specific domains or tasks that the teacher model is particularly adept at, such as answering science questions or generating creative stories.
-
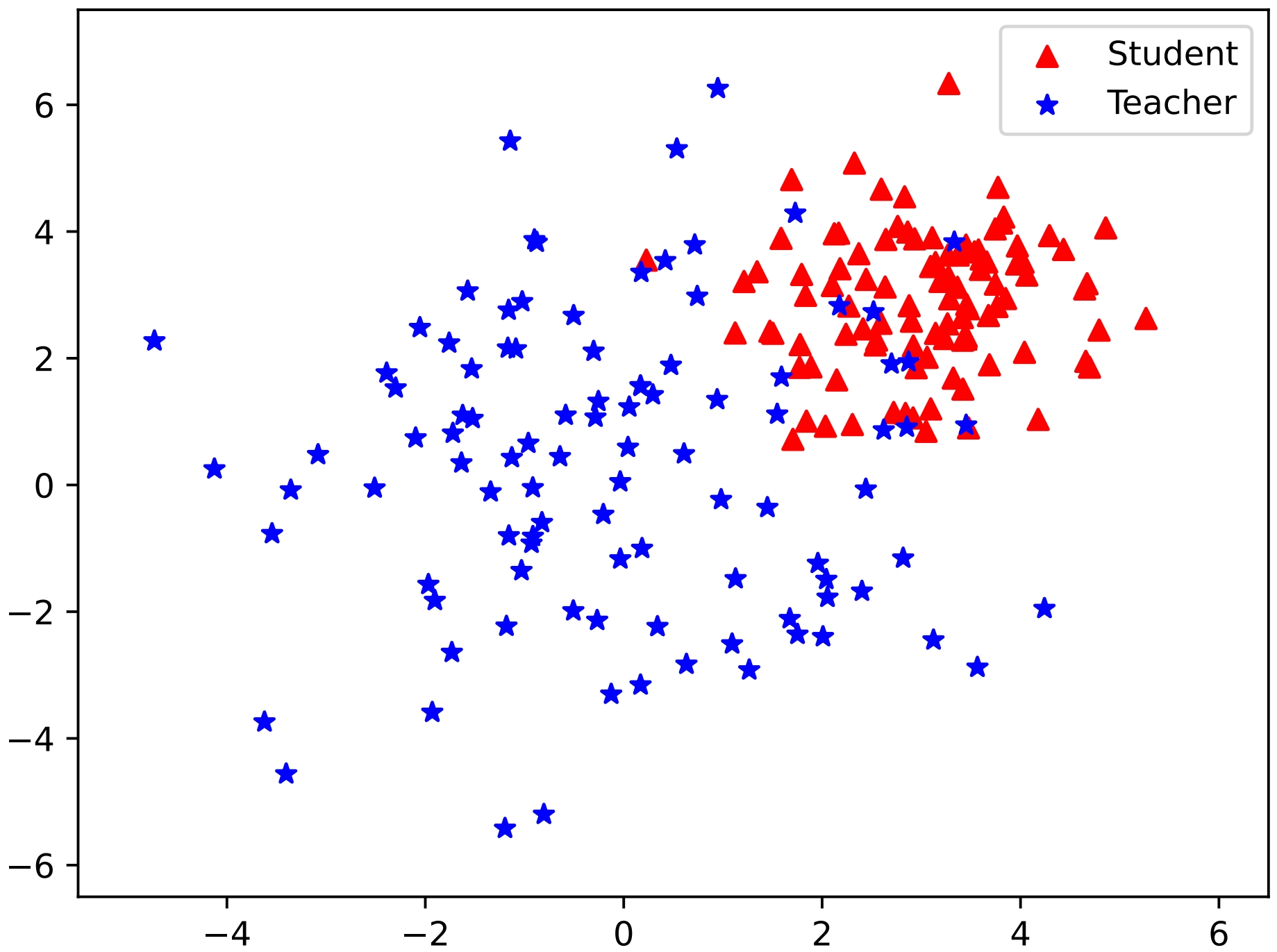
Knowledge Distillation: Using a knowledge distillation process, the authors transfer the teacher model's expertise in these targeted domains to a smaller "student" model. This allows the student model to retain much of the teacher's domain-specific capabilities while being much more efficient.
The knowledge distillation process involves training the student model to mimic the outputs of the teacher model on the relevant domain-specific tasks, rather than just training it on the original dataset. This allows the student to learn the teacher's relevant knowledge and skills in a more direct way.
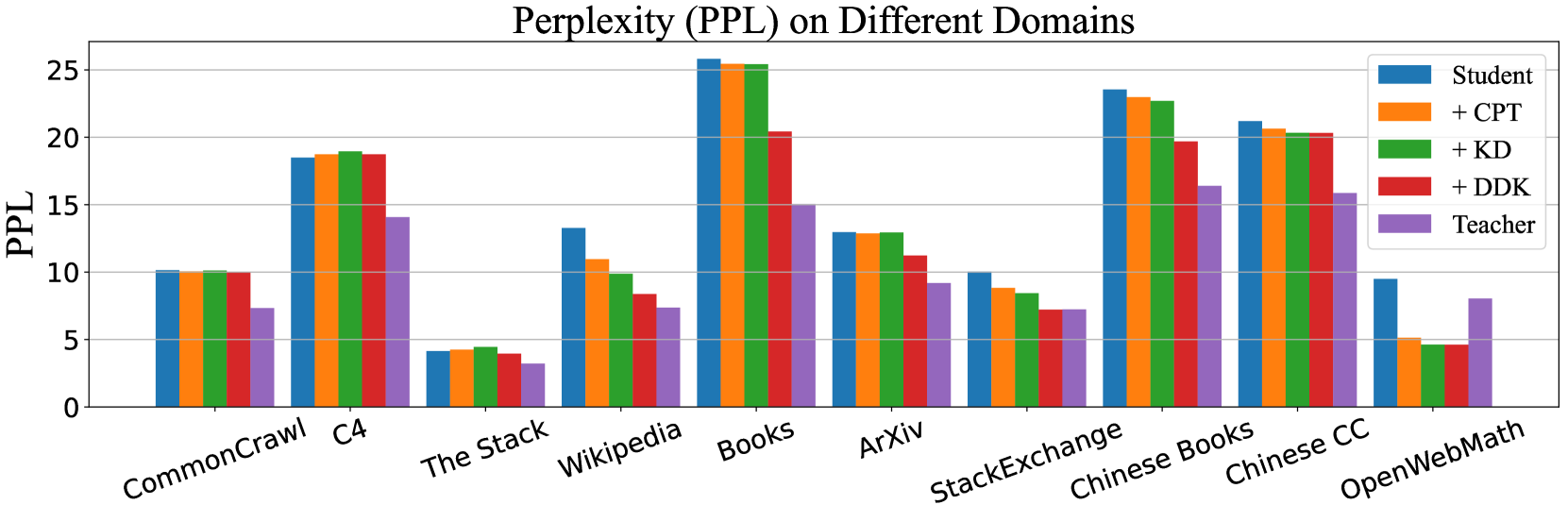
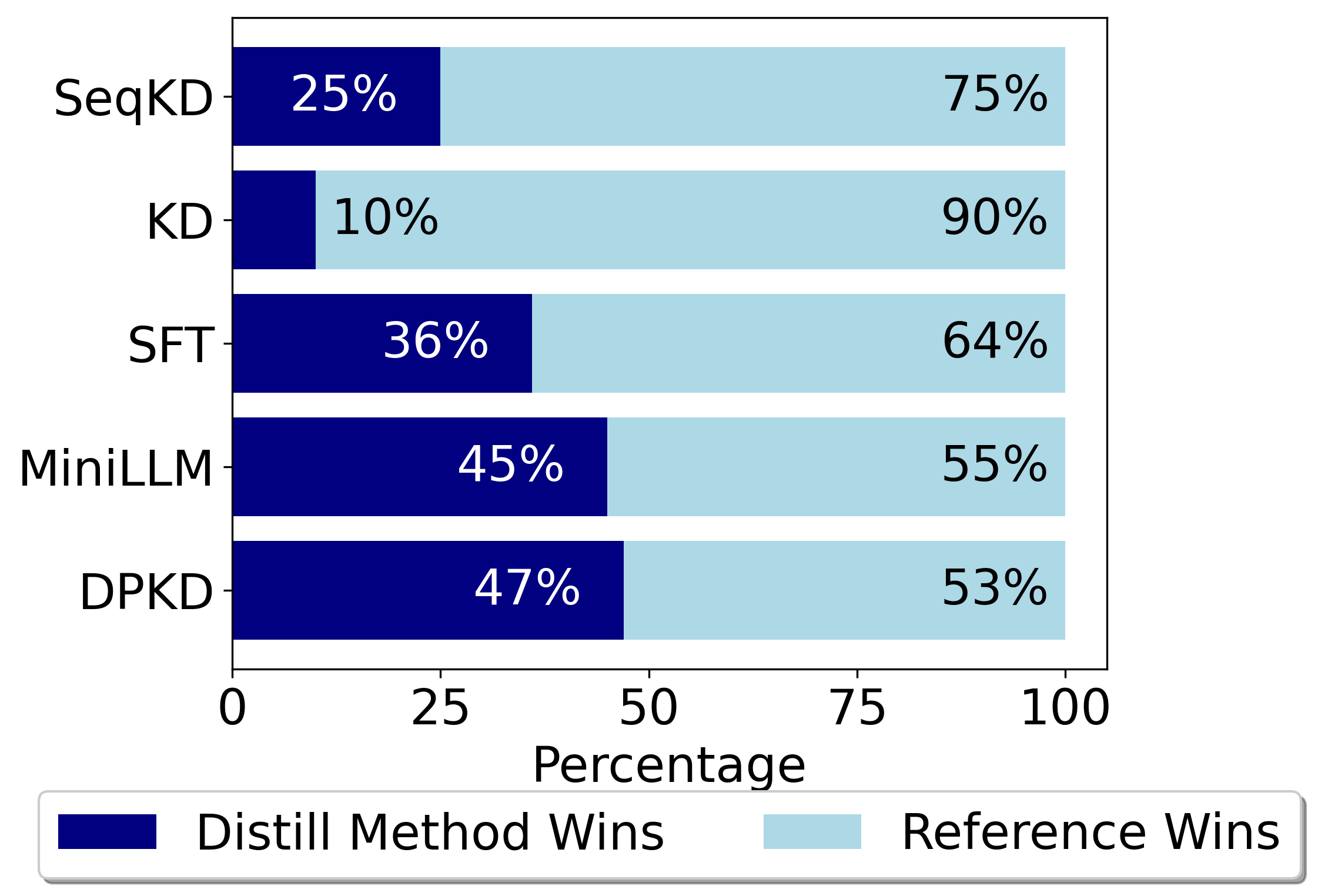
The authors evaluate their DDK approach on several language understanding and generation tasks, and show that the student models are able to achieve strong performance while being significantly smaller and more efficient than the original teacher models. This suggests DDK could enable deploying high-quality language AI on resource-constrained devices like mobile phones or edge computing hardware.
Critical Analysis
The DDK approach presented in this paper is a promising technique for improving the efficiency of large language models while retaining their capabilities. The ability to distill domain-specific knowledge into smaller, more streamlined models is an important step towards making these powerful AI systems more accessible and deployable on a wider range of hardware.
However, the paper does not address some potential limitations and areas for further research:
- The distillation process may not be able to fully capture all the nuances and contextual knowledge present in the large teacher model. There could be some loss of performance or capabilities when transferring to the smaller student model.
- The approach relies on first pre-training a large teacher model, which can itself be computationally intensive and resource-heavy. Techniques to reduce the cost of this initial pre-training step could further improve the overall efficiency.
- The experiments in the paper focus on a limited set of domains and tasks. More research is needed to understand how well DDK generalizes to a broader range of applications and real-world scenarios.
Additionally, the broader societal implications of deploying highly capable language models on edge devices and consumer electronics are worth considering. Careful consideration of potential misuse, bias, and privacy/security concerns will be important as this technology matures.
Overall, the DDK technique represents an important advance in making large language models more practically deployable. But continued research and responsible development will be key to realizing the full potential of this approach.
Conclusion
The "DDK: Distilling Domain Knowledge for Efficient Large Language Models" paper presents a novel approach to improving the efficiency of large language models by distilling their domain-specific knowledge into smaller, more streamlined student models.
This could enable the deployment of high-performing language AI on resource-constrained devices like mobile phones or edge computing hardware, where the full-scale models would be too computationally intensive to run.
The paper demonstrates the effectiveness of this DDK technique through experiments on several language tasks, showing the student models can achieve strong performance while being significantly smaller and more efficient than the original teacher models.
While the approach has some limitations that require further research, it represents an important step forward in making powerful language AI systems more accessible and practically deployable. Continued innovation in this area could have significant implications for the real-world applications of large language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
DDK: Distilling Domain Knowledge for Efficient Large Language Models
Jiaheng Liu, Chenchen Zhang, Jinyang Guo, Yuanxing Zhang, Haoran Que, Ken Deng, Zhiqi Bai, Jie Liu, Ge Zhang, Jiakai Wang, Yanan Wu, Congnan Liu, Wenbo Su, Jiamang Wang, Lin Qu, Bo Zheng
Despite the advanced intelligence abilities of large language models (LLMs) in various applications, they still face significant computational and storage demands. Knowledge Distillation (KD) has emerged as an effective strategy to improve the performance of a smaller LLM (i.e., the student model) by transferring knowledge from a high-performing LLM (i.e., the teacher model). Prevailing techniques in LLM distillation typically use a black-box model API to generate high-quality pretrained and aligned datasets, or utilize white-box distillation by altering the loss function to better transfer knowledge from the teacher LLM. However, these methods ignore the knowledge differences between the student and teacher LLMs across domains. This results in excessive focus on domains with minimal performance gaps and insufficient attention to domains with large gaps, reducing overall performance. In this paper, we introduce a new LLM distillation framework called DDK, which dynamically adjusts the composition of the distillation dataset in a smooth manner according to the domain performance differences between the teacher and student models, making the distillation process more stable and effective. Extensive evaluations show that DDK significantly improves the performance of student models, outperforming both continuously pretrained baselines and existing knowledge distillation methods by a large margin.
Read more7/24/2024

0
MiniLLM: Knowledge Distillation of Large Language Models
Yuxian Gu, Li Dong, Furu Wei, Minlie Huang
Knowledge Distillation (KD) is a promising technique for reducing the high computational demand of large language models (LLMs). However, previous KD methods are primarily applied to white-box classification models or training small models to imitate black-box model APIs like ChatGPT. How to effectively distill the knowledge of white-box LLMs into small models is still under-explored, which becomes more important with the prosperity of open-source LLMs. In this work, we propose a KD approach that distills LLMs into smaller language models. We first replace the forward Kullback-Leibler divergence (KLD) objective in the standard KD approaches with reverse KLD, which is more suitable for KD on generative language models, to prevent the student model from overestimating the low-probability regions of the teacher distribution. Then, we derive an effective optimization approach to learn this objective. The student models are named MiniLLM. Extensive experiments in the instruction-following setting show that MiniLLM generates more precise responses with higher overall quality, lower exposure bias, better calibration, and higher long-text generation performance than the baselines. Our method is scalable for different model families with 120M to 13B parameters. Our code, data, and model checkpoints can be found in https://github.com/microsoft/LMOps/tree/main/minillm.
Read more4/11/2024
0
Dual-Space Knowledge Distillation for Large Language Models
Songming Zhang, Xue Zhang, Zengkui Sun, Yufeng Chen, Jinan Xu
Knowledge distillation (KD) is known as a promising solution to compress large language models (LLMs) via transferring their knowledge to smaller models. During this process, white-box KD methods usually minimize the distance between the output distributions of the two models so that more knowledge can be transferred. However, in the current white-box KD framework, the output distributions are from the respective output spaces of the two models, using their own prediction heads. We argue that the space discrepancy will lead to low similarity between the teacher model and the student model on both representation and distribution levels. Furthermore, this discrepancy also hinders the KD process between models with different vocabularies, which is common for current LLMs. To address these issues, we propose a dual-space knowledge distillation (DSKD) framework that unifies the output spaces of the two models for KD. On the basis of DSKD, we further develop a cross-model attention mechanism, which can automatically align the representations of the two models with different vocabularies. Thus, our framework is not only compatible with various distance functions for KD (e.g., KL divergence) like the current framework, but also supports KD between any two LLMs regardless of their vocabularies. Experiments on task-agnostic instruction-following benchmarks show that DSKD significantly outperforms the current white-box KD framework with various distance functions, and also surpasses existing KD methods for LLMs with different vocabularies.
Read more8/14/2024
0
Direct Preference Knowledge Distillation for Large Language Models
Yixing Li, Yuxian Gu, Li Dong, Dequan Wang, Yu Cheng, Furu Wei
In the field of large language models (LLMs), Knowledge Distillation (KD) is a critical technique for transferring capabilities from teacher models to student models. However, existing KD methods face limitations and challenges in distillation of LLMs, including efficiency and insufficient measurement capabilities of traditional KL divergence. It is shown that LLMs can serve as an implicit reward function, which we define as a supplement to KL divergence. In this work, we propose Direct Preference Knowledge Distillation (DPKD) for LLMs. DPKD utilizes distribution divergence to represent the preference loss and implicit reward function. We re-formulate KD of LLMs into two stages: first optimizing and objective consisting of implicit reward and reverse KL divergence and then improving the preference probability of teacher outputs over student outputs. We conducted experiments and analysis on various datasets with LLM parameters ranging from 120M to 13B and demonstrate the broad applicability and effectiveness of our DPKD approach. Meanwhile, we prove the value and effectiveness of the introduced implicit reward and output preference in KD through experiments and theoretical analysis. The DPKD method outperforms the baseline method in both output response precision and exact match percentage. Code and data are available at https://aka.ms/dpkd.
Read more7/1/2024