DEAR: Disentangled Environment and Agent Representations for Reinforcement Learning without Reconstruction

0
Sign in to get full access
Overview
- This paper proposes a novel reinforcement learning (RL) framework called DEAR (Disentangled Environment and Agent Representations) that can learn effective policies without relying on environment reconstruction.
- DEAR aims to disentangle the representation of the environment and the agent, allowing for more efficient and generalizable learning.
- The key idea is to learn representations that capture the relevant factors of the environment and the agent's state, without the need to reconstruct the full environment.
Plain English Explanation
In reinforcement learning, an agent (such as a robot or a computer program) learns to make decisions by interacting with its environment and receiving rewards or penalties for its actions. Traditionally, many RL methods have tried to learn a "reconstruction" of the environment, meaning they try to build a detailed model of the environment based on the agent's observations.
The DEAR: Disentangled Environment and Agent Representations for Reinforcement Learning without Reconstruction paper introduces a new approach called DEAR that avoids the need for environment reconstruction. Instead, DEAR focuses on learning separate, disentangled representations for the environment and the agent's own state.
The key idea is that by learning these disentangled representations, the agent can more effectively and efficiently learn how to navigate the environment and make good decisions, without needing to build a complete model of the environment. This can lead to faster learning, better generalization to new situations, and overall more effective reinforcement learning.
The paper builds on previous work on disentangled representation learning and shows how this approach can be applied to reinforcement learning in a way that avoids the need for environment reconstruction.
Technical Explanation
The DEAR: Disentangled Environment and Agent Representations for Reinforcement Learning without Reconstruction paper proposes a novel reinforcement learning framework that learns separate, disentangled representations for the environment and the agent's state, without the need for environment reconstruction.
The key elements of the DEAR framework are:
-
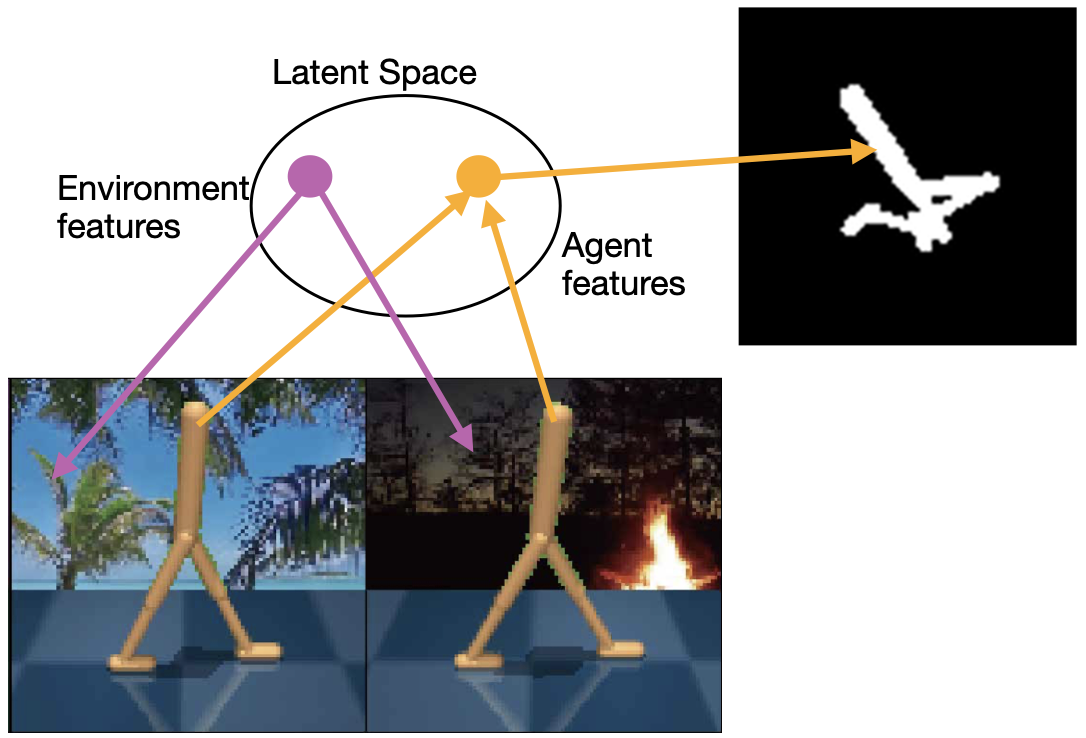
Disentangled Representation Learning: The model learns two separate encoder networks - one for the environment and one for the agent's state. These encoders extract disentangled representations that capture the relevant factors of the environment and the agent's state, respectively.
-
Reinforcement Learning: The agent's policy is learned using the disentangled representations, without the need to reconstruct the full environment. The policy network takes the agent's representation as input and outputs actions.
-
Auxiliary Tasks: The paper introduces several auxiliary tasks, such as predicting reward and next-state, to further encourage the learning of disentangled representations that are useful for reinforcement learning.
The paper demonstrates the effectiveness of the DEAR framework through experiments on several benchmark environments, including Disentangled Representation Learning for Environment-Agnostic Speaker Recognition and DRED: Zero-Shot Transfer in Reinforcement Learning via Disentangled Representations. The results show that DEAR can learn effective policies without the need for environment reconstruction, and that the disentangled representations can lead to better generalization and transfer learning.
Critical Analysis
The DEAR: Disentangled Environment and Agent Representations for Reinforcement Learning without Reconstruction paper presents a promising approach to reinforcement learning, but it also has some potential limitations and areas for further research:
-
Complexity of Disentanglement: Achieving true disentanglement of environment and agent representations can be challenging, especially in complex environments. The paper does not discuss in depth the challenges of ensuring that the learned representations are fully disentangled.
-
Scalability to Large-scale Environments: The experiments in the paper are conducted on relatively simple environments. It remains to be seen how well the DEAR framework would scale to more complex, large-scale environments, where the challenges of disentanglement and representation learning may be more pronounced.
-
Interpretability of Learned Representations: While the disentangled representations can be beneficial for learning and generalization, the paper does not explore the interpretability of these representations. Understanding the specific factors captured by the learned representations could be valuable for further analysis and development.
-
Comparison to Other Disentanglement Approaches: The paper could have provided a more comprehensive comparison to other disentanglement-based RL approaches, such as Unsupervised Representation Learning for Deep Reinforcement Learning: A Review, to better contextualize the contributions of the DEAR framework.
Overall, the DEAR: Disentangled Environment and Agent Representations for Reinforcement Learning without Reconstruction paper presents an interesting and potentially impactful approach to reinforcement learning. However, further research is needed to address the limitations and explore the broader applicability of the DEAR framework.
Conclusion
The DEAR: Disentangled Environment and Agent Representations for Reinforcement Learning without Reconstruction paper proposes a novel reinforcement learning framework that learns separate, disentangled representations for the environment and the agent's state, without the need for environment reconstruction. This approach can lead to more efficient and generalizable learning, as the agent can focus on the relevant factors of the environment and its own state, rather than having to build a complete model of the environment.
The key contributions of the DEAR framework include the use of disentangled representation learning, the incorporation of auxiliary tasks to further encourage the learning of useful representations, and the demonstration of improved performance and generalization on several benchmark environments.
While the paper presents a promising approach, there are also some potential limitations and areas for further research, such as the complexity of achieving true disentanglement, the scalability to large-scale environments, and the interpretability of the learned representations. Addressing these challenges could further strengthen the DEAR framework and its impact on the field of reinforcement learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
DEAR: Disentangled Environment and Agent Representations for Reinforcement Learning without Reconstruction
Ameya Pore, Riccardo Muradore, Diego Dall'Alba
Reinforcement Learning (RL) algorithms can learn robotic control tasks from visual observations, but they often require a large amount of data, especially when the visual scene is complex and unstructured. In this paper, we explore how the agent's knowledge of its shape can improve the sample efficiency of visual RL methods. We propose a novel method, Disentangled Environment and Agent Representations (DEAR), that uses the segmentation mask of the agent as supervision to learn disentangled representations of the environment and the agent through feature separation constraints. Unlike previous approaches, DEAR does not require reconstruction of visual observations. These representations are then used as an auxiliary loss to the RL objective, encouraging the agent to focus on the relevant features of the environment. We evaluate DEAR on two challenging benchmarks: Distracting DeepMind control suite and Franka Kitchen manipulation tasks. Our findings demonstrate that DEAR surpasses state-of-the-art methods in sample efficiency, achieving comparable or superior performance with reduced parameters. Our results indicate that integrating agent knowledge into visual RL methods has the potential to enhance their learning efficiency and robustness.
Read more7/2/2024
❗
0
Disentangled Representation Learning
Xin Wang, Hong Chen, Si'ao Tang, Zihao Wu, Wenwu Zhu
Disentangled Representation Learning (DRL) aims to learn a model capable of identifying and disentangling the underlying factors hidden in the observable data in representation form. The process of separating underlying factors of variation into variables with semantic meaning benefits in learning explainable representations of data, which imitates the meaningful understanding process of humans when observing an object or relation. As a general learning strategy, DRL has demonstrated its power in improving the model explainability, controlability, robustness, as well as generalization capacity in a wide range of scenarios such as computer vision, natural language processing, and data mining. In this article, we comprehensively investigate DRL from various aspects including motivations, definitions, methodologies, evaluations, applications, and model designs. We first present two well-recognized definitions, i.e., Intuitive Definition and Group Theory Definition for disentangled representation learning. We further categorize the methodologies for DRL into four groups from the following perspectives, the model type, representation structure, supervision signal, and independence assumption. We also analyze principles to design different DRL models that may benefit different tasks in practical applications. Finally, we point out challenges in DRL as well as potential research directions deserving future investigations. We believe this work may provide insights for promoting the DRL research in the community.
Read more6/28/2024

0
Collision Avoidance for Multiple UAVs in Unknown Scenarios with Causal Representation Disentanglement
Jiafan Zhuang, Zihao Xia, Gaofei Han, Boxi Wang, Wenji Li, Dongliang Wang, Zhifeng Hao, Ruichu Cai, Zhun Fan
Deep reinforcement learning (DRL) has achieved remarkable progress in online path planning tasks for multi-UAV systems. However, existing DRL-based methods often suffer from performance degradation when tackling unseen scenarios, since the non-causal factors in visual representations adversely affect policy learning. To address this issue, we propose a novel representation learning approach, ie, causal representation disentanglement, which can identify the causal and non-causal factors in representations. After that, we only pass causal factors for subsequent policy learning and thus explicitly eliminate the influence of non-causal factors, which effectively improves the generalization ability of DRL models. Experimental results show that our proposed method can achieve robust navigation performance and effective collision avoidance especially in unseen scenarios, which significantly outperforms existing SOTA algorithms.
Read more7/16/2024
0
Multi-view Disentanglement for Reinforcement Learning with Multiple Cameras
Mhairi Dunion, Stefano V. Albrecht
The performance of image-based Reinforcement Learning (RL) agents can vary depending on the position of the camera used to capture the images. Training on multiple cameras simultaneously, including a first-person egocentric camera, can leverage information from different camera perspectives to improve the performance of RL. However, hardware constraints may limit the availability of multiple cameras in real-world deployment. Additionally, cameras may become damaged in the real-world preventing access to all cameras that were used during training. To overcome these hardware constraints, we propose Multi-View Disentanglement (MVD), which uses multiple cameras to learn a policy that is robust to a reduction in the number of cameras to generalise to any single camera from the training set. Our approach is a self-supervised auxiliary task for RL that learns a disentangled representation from multiple cameras, with a shared representation that is aligned across all cameras to allow generalisation to a single camera, and a private representation that is camera-specific. We show experimentally that an RL agent trained on a single third-person camera is unable to learn an optimal policy in many control tasks; but, our approach, benefiting from multiple cameras during training, is able to solve the task using only the same single third-person camera.
Read more6/24/2024