DRED: Zero-Shot Transfer in Reinforcement Learning via Data-Regularised Environment Design

0
🔄
Sign in to get full access
Overview
- The paper discusses the challenges of HTML conversion and the limitations of the current conversion tool in handling certain LaTeX packages.
- It acknowledges that the HTML conversion process sometimes displays errors due to content that did not convert correctly from the source.
- The paper highlights that the HTML conversion tool is not yet able to support certain packages used in the paper, such as the
shellescpackage.
Plain English Explanation
The provided paper discusses the difficulties in converting technical documents from their original format (such as LaTeX) into HTML, which is a more widely accessible format. The authors explain that the process of converting these documents to HTML can sometimes result in errors or issues, particularly when the document uses specialized packages or features that the conversion tool is not yet equipped to handle.
In this case, the paper indicates that it uses the shellesc package, which is not yet supported by the HTML conversion tool. This means that some aspects of the document may not have translated correctly when converted to HTML. The authors acknowledge this limitation and provide a note to readers, encouraging them not to provide feedback on these known issues, as they are already being addressed.
The key message is that while the goal of making technical papers more accessible through HTML conversion is laudable, the process is not yet perfect, and there are still some challenges to overcome. The authors are transparent about these limitations and are likely working to improve the conversion process over time.
Technical Explanation
The paper discusses the challenges faced when converting technical documents, such as those published on arXiv, from their original format (e.g., LaTeX) into HTML. The authors acknowledge that the HTML conversion process sometimes displays errors due to content that did not convert correctly from the source.
Specifically, the paper highlights that the HTML conversion tool is not yet able to support certain packages used in the document, such as the shellesc package. The shellesc package is a LaTeX package that provides a portable way of executing shell commands within a LaTeX document.
The authors provide a clear message to readers, stating that feedback on these known issues is not necessary, as they are already being worked on. This transparency and acknowledgment of the limitations of the current conversion process is a valuable aspect of the paper.
Critical Analysis
The paper's focus on the limitations of the HTML conversion process is a necessary and important aspect of making technical documents more accessible. By acknowledging these challenges upfront, the authors demonstrate a commitment to transparency and show that they are aware of the ongoing work required to improve the conversion tools.
However, the paper does not provide much detail on the specific challenges or the potential solutions being explored. It would be helpful if the authors could elaborate on the technical complexities involved in handling specialized LaTeX packages, the trade-offs between preserving the original formatting and ensuring accessibility, and the potential avenues for enhancing the conversion process.
Additionally, the paper could benefit from a more comprehensive discussion of the broader implications of these conversion challenges. For example, the authors could explore how these issues might impact the accessibility and discoverability of technical research, especially for readers who rely on HTML as their primary access point.
Conclusion
The provided paper highlights the challenges faced in converting technical documents from their original formats, such as LaTeX, into more accessible HTML formats. The authors are transparent about the limitations of the current HTML conversion tool, which is unable to handle certain specialized packages used in the document, such as shellesc.
While the paper does not delve deeply into the technical details or provide a comprehensive analysis of the broader implications, it serves as a valuable acknowledgment of the ongoing work required to improve the accessibility of technical research. By being upfront about these conversion challenges, the authors demonstrate a commitment to transparency and a recognition that the process of making technical content more accessible is an evolving and complex endeavor.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔄
0
DRED: Zero-Shot Transfer in Reinforcement Learning via Data-Regularised Environment Design
Samuel Garcin, James Doran, Shangmin Guo, Christopher G. Lucas, Stefano V. Albrecht
Autonomous agents trained using deep reinforcement learning (RL) often lack the ability to successfully generalise to new environments, even when these environments share characteristics with the ones they have encountered during training. In this work, we investigate how the sampling of individual environment instances, or levels, affects the zero-shot generalisation (ZSG) ability of RL agents. We discover that, for deep actor-critic architectures sharing their base layers, prioritising levels according to their value loss minimises the mutual information between the agent's internal representation and the set of training levels in the generated training data. This provides a novel theoretical justification for the regularisation achieved by certain adaptive sampling strategies. We then turn our attention to unsupervised environment design (UED) methods, which assume control over level generation. We find that existing UED methods can significantly shift the training distribution, which translates to low ZSG performance. To prevent both overfitting and distributional shift, we introduce data-regularised environment design (DRED). DRED generates levels using a generative model trained to approximate the ground truth distribution of an initial set of level parameters. Through its grounding, DRED achieves significant improvements in ZSG over adaptive level sampling strategies and UED methods. Our code and experimental data are available at https://github.com/uoe-agents/dred.
Read more6/17/2024

0
No Regrets: Investigating and Improving Regret Approximations for Curriculum Discovery
Alexander Rutherford, Michael Beukman, Timon Willi, Bruno Lacerda, Nick Hawes, Jakob Foerster
What data or environments to use for training to improve downstream performance is a longstanding and very topical question in reinforcement learning. In particular, Unsupervised Environment Design (UED) methods have gained recent attention as their adaptive curricula enable agents to be robust to in- and out-of-distribution tasks. We ask to what extent these methods are themselves robust when applied to a novel setting, closely inspired by a real-world robotics problem. Surprisingly, we find that the state-of-the-art UED methods either do not improve upon the na{i}ve baseline of Domain Randomisation (DR), or require substantial hyperparameter tuning to do so. Our analysis shows that this is due to their underlying scoring functions failing to predict intuitive measures of ``learnability'', i.e., in finding the settings that the agent sometimes solves, but not always. Based on this, we instead directly train on levels with high learnability and find that this simple and intuitive approach outperforms UED methods and DR in several binary-outcome environments, including on our domain and the standard UED domain of Minigrid. We further introduce a new adversarial evaluation procedure for directly measuring robustness, closely mirroring the conditional value at risk (CVaR). We open-source all our code and present visualisations of final policies here: https://github.com/amacrutherford/sampling-for-learnability.
Read more8/30/2024

0
Inferring Behavior-Specific Context Improves Zero-Shot Generalization in Reinforcement Learning
Tidiane Camaret Ndir, Andr'e Biedenkapp, Noor Awad
In this work, we address the challenge of zero-shot generalization (ZSG) in Reinforcement Learning (RL), where agents must adapt to entirely novel environments without additional training. We argue that understanding and utilizing contextual cues, such as the gravity level of the environment, is critical for robust generalization, and we propose to integrate the learning of context representations directly with policy learning. Our algorithm demonstrates improved generalization on various simulated domains, outperforming prior context-learning techniques in zero-shot settings. By jointly learning policy and context, our method acquires behavior-specific context representations, enabling adaptation to unseen environments and marks progress towards reinforcement learning systems that generalize across diverse real-world tasks. Our code and experiments are available at https://github.com/tidiane-camaret/contextual_rl_zero_shot.
Read more4/16/2024
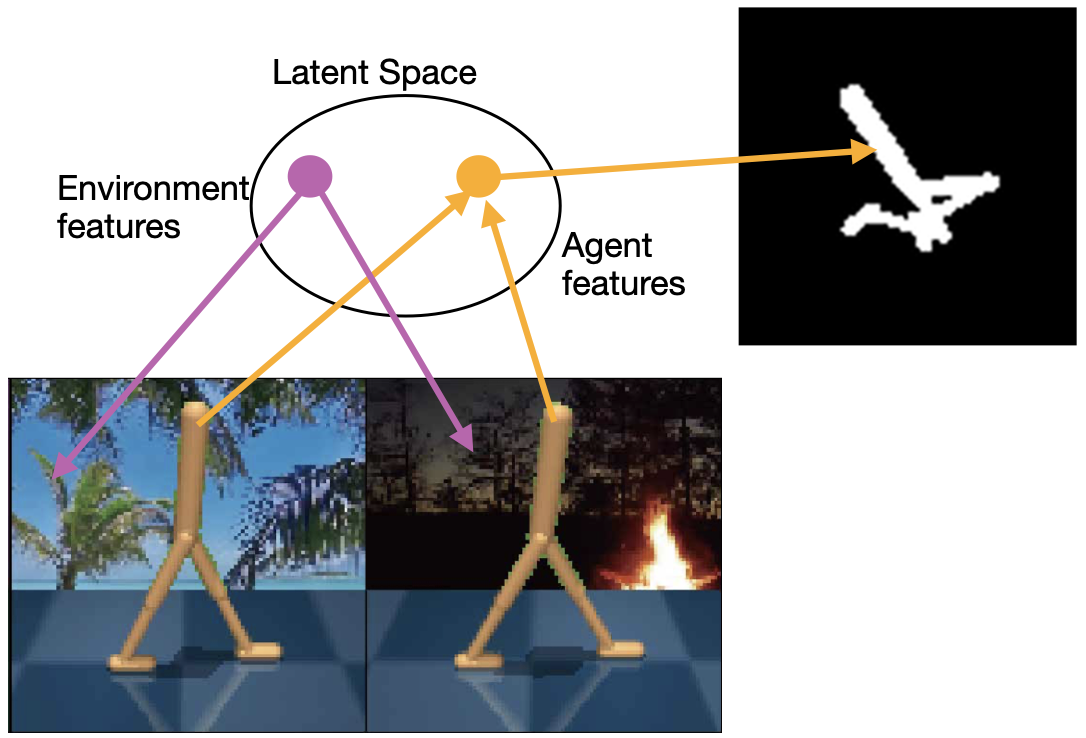
0
DEAR: Disentangled Environment and Agent Representations for Reinforcement Learning without Reconstruction
Ameya Pore, Riccardo Muradore, Diego Dall'Alba
Reinforcement Learning (RL) algorithms can learn robotic control tasks from visual observations, but they often require a large amount of data, especially when the visual scene is complex and unstructured. In this paper, we explore how the agent's knowledge of its shape can improve the sample efficiency of visual RL methods. We propose a novel method, Disentangled Environment and Agent Representations (DEAR), that uses the segmentation mask of the agent as supervision to learn disentangled representations of the environment and the agent through feature separation constraints. Unlike previous approaches, DEAR does not require reconstruction of visual observations. These representations are then used as an auxiliary loss to the RL objective, encouraging the agent to focus on the relevant features of the environment. We evaluate DEAR on two challenging benchmarks: Distracting DeepMind control suite and Franka Kitchen manipulation tasks. Our findings demonstrate that DEAR surpasses state-of-the-art methods in sample efficiency, achieving comparable or superior performance with reduced parameters. Our results indicate that integrating agent knowledge into visual RL methods has the potential to enhance their learning efficiency and robustness.
Read more7/2/2024