Decentralized Learning Strategies for Estimation Error Minimization with Graph Neural Networks
2404.03227
0
0

Abstract
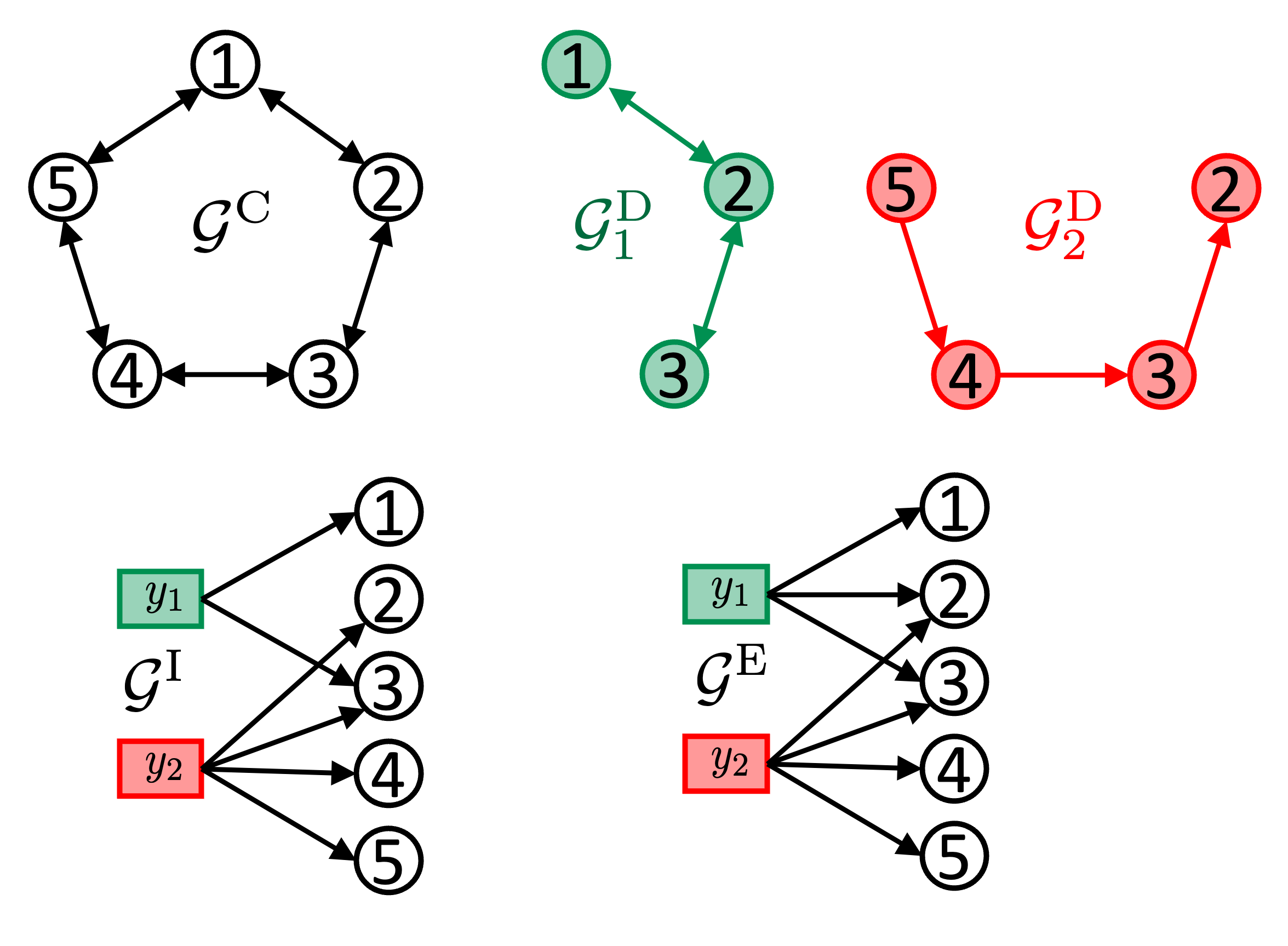
We address the challenge of sampling and remote estimation for autoregressive Markovian processes in a multi-hop wireless network with statistically-identical agents. Agents cache the most recent samples from others and communicate over wireless collision channels governed by an underlying graph topology. Our goal is to minimize time-average estimation error and/or age of information with decentralized scalable sampling and transmission policies, considering both oblivious (where decision-making is independent of the physical processes) and non-oblivious policies (where decision-making depends on physical processes). We prove that in oblivious policies, minimizing estimation error is equivalent to minimizing the age of information. The complexity of the problem, especially the multi-dimensional action spaces and arbitrary network topologies, makes theoretical methods for finding optimal transmission policies intractable. We optimize the policies using a graphical multi-agent reinforcement learning framework, where each agent employs a permutation-equivariant graph neural network architecture. Theoretically, we prove that our proposed framework exhibits desirable transferability properties, allowing transmission policies trained on small- or moderate-size networks to be executed effectively on large-scale topologies. Numerical experiments demonstrate that (i) Our proposed framework outperforms state-of-the-art baselines; (ii) The trained policies are transferable to larger networks, and their performance gains increase with the number of agents; (iii) The training procedure withstands non-stationarity even if we utilize independent learning techniques; and, (iv) Recurrence is pivotal in both independent learning and centralized training and decentralized execution, and improves the resilience to non-stationarity in independent learning.
Create account to get full access
Overview
- The paper explores decentralized learning strategies for minimizing estimation error using graph neural networks.
- It investigates methods for distributed learning on graph-structured data to improve accuracy and reduce communication overhead.
- The authors propose several decentralized algorithms and analyze their theoretical properties and performance on real-world datasets.
Plain English Explanation
The research paper looks at ways to improve how machine learning models can learn from data that is spread out across different locations, rather than having all the data in one place. This is an important problem because in many real-world situations, data is distributed across multiple devices or organizations and can't be easily centralized.
The key idea is to use graph neural networks, which are a type of machine learning model that can handle data organized in a graph structure (nodes connected by edges). The researchers develop several decentralized algorithms that allow multiple parties to collaboratively train a graph neural network model without having to share all their private data.
The goal is to minimize the overall error in the model's estimates or predictions, while also reducing the amount of communication needed between the different parties. This is important because in many applications, like wireless networks, the communication bandwidth is limited and excessive back-and-forth can be costly or slow.
The paper provides a mathematical analysis of these decentralized learning strategies and tests them on real-world datasets to see how well they perform compared to more centralized approaches. The results suggest these decentralized techniques can be effective at training accurate models while keeping communication and coordination costs low.
Technical Explanation
The paper presents several decentralized learning algorithms for minimizing estimation error using graph neural networks. The key idea is to leverage the graph structure of the data to enable distributed training, where multiple parties can collaboratively learn a shared model without fully sharing their private data.
The authors first provide a formal problem formulation, modeling the data as a graph where nodes represent agents or parties, and edges encode dependencies or relationships between them. The goal is to train a graph neural network that can accurately estimate some target variable of interest, while minimizing the overall estimation error across all the nodes.
The researchers then propose three decentralized algorithms:
-
Demand sampling: This method allows each node to selectively share relevant data with its neighbors, reducing communication overhead.
-
[Dual averaging]: This is an optimization-based approach that uses a decentralized averaging scheme to coordinate the model updates across nodes.
-
[Reinforcement learning-based]: This algorithm frames the decentralized learning problem as a Markov decision process and uses reinforcement learning techniques to learn an optimal communication policy.
The authors provide theoretical analysis of these algorithms, deriving bounds on the estimation error and communication complexity. They also conduct experiments on real-world datasets, including road traffic prediction and topic modeling, demonstrating the effectiveness of the proposed decentralized strategies compared to centralized baselines.
Critical Analysis
The paper makes a valuable contribution by exploring decentralized learning techniques for graph-structured data, which has important practical applications in areas like wireless networks, social networks, and sensor networks. The proposed algorithms offer a principled way to train accurate models while preserving data privacy and reducing communication overhead.
However, the paper does not address some potential limitations and challenges:
-
The theoretical analysis relies on strong assumptions, such as convexity and smoothness of the objective function, which may not hold in more complex real-world scenarios.
-
The experiments are conducted on relatively small-scale datasets, and it's unclear how the methods would scale to truly large-scale, heterogeneous data sources.
-
The paper does not consider potential issues around incentive alignment, Byzantine failures, or other robustness concerns that can arise in decentralized settings.
-
The proposed algorithms may still require a significant amount of coordination and information sharing between nodes, which could be impractical in some applications.
Future research could explore more flexible and robust decentralized learning approaches, perhaps drawing inspiration from federated learning or multiagent reinforcement learning. Additionally, it would be valuable to study the performance of these methods on larger, more diverse datasets and in real-world testbeds.
Conclusion
This paper presents an important step forward in developing decentralized learning strategies for graph-structured data. The proposed algorithms offer a principled approach to training accurate models while preserving data privacy and reducing communication overhead, which is a crucial requirement in many real-world applications.
The theoretical analysis and experimental results demonstrate the potential of these techniques, but also highlight the need for further research to address the limitations and scale the methods to more realistic, large-scale scenarios. By continuing to explore decentralized learning on graphs, researchers can help unlock the power of distributed data sources and enable more efficient, privacy-preserving machine learning systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤯
Random Inverse Problems Over Graphs: Decentralized Online Learning
Tao Li, Xiwei Zhang
0
0
We establish a framework of distributed random inverse problems over network graphs with online measurements, and propose a decentralized online learning algorithm. This unifies the distributed parameter estimation in Hilbert spaces and the least mean square problem in reproducing kernel Hilbert spaces (RKHS-LMS). We transform the convergence of the algorithm into the asymptotic stability of a class of inhomogeneous random difference equations in Hilbert spaces with L2-bounded martingale difference terms and develop the L2 -asymptotic stability theory in Hilbert spaces. It is shown that if the network graph is connected and the sequence of forward operators satisfies the infinite-dimensional spatio-temporal persistence of excitation condition, then the estimates of all nodes are mean square and almost surely strongly consistent. Moreover, we propose a decentralized online learning algorithm in RKHS based on non-stationary and non-independent online data streams, and prove that the algorithm is mean square and almost surely strongly consistent if the operators induced by the random input data satisfy the infinite-dimensional spatio-temporal persistence of excitation condition.
5/30/2024
🌿
Decentralized Online Regularized Learning Over Random Time-Varying Graphs
Xiwei Zhang, Tao Li, Xiaozheng Fu
0
0
We study the decentralized online regularized linear regression algorithm over random time-varying graphs. At each time step, every node runs an online estimation algorithm consisting of an innovation term processing its own new measurement, a consensus term taking a weighted sum of estimations of its own and its neighbors with additive and multiplicative communication noises and a regularization term preventing over-fitting. It is not required that the regression matrices and graphs satisfy special statistical assumptions such as mutual independence, spatio-temporal independence or stationarity. We develop the nonnegative supermartingale inequality of the estimation error, and prove that the estimations of all nodes converge to the unknown true parameter vector almost surely if the algorithm gains, graphs and regression matrices jointly satisfy the sample path spatio-temporal persistence of excitation condition. Especially, this condition holds by choosing appropriate algorithm gains if the graphs are uniformly conditionally jointly connected and conditionally balanced, and the regression models of all nodes are uniformly conditionally spatio-temporally jointly observable, under which the algorithm converges in mean square and almost surely. In addition, we prove that the regret upper bound is $O(T^{1-tau}ln T)$, where $tauin (0.5,1)$ is a constant depending on the algorithm gains.
4/23/2024
🔎
Goal-oriented Estimation of Multiple Markov Sources in Resource-constrained Systems
Jiping Luo, Nikolaos Pappas
0
0
This paper investigates goal-oriented communication for remote estimation of multiple Markov sources in resource-constrained networks. An agent decides the updating times of the sources and transmits the packet to a remote destination over an unreliable channel with delay. The destination is tasked with source reconstruction for actuation. We utilize the metric textit{cost of actuation error} (CAE) to capture the state-dependent actuation costs. We aim for a sampling policy that minimizes the long-term average CAE subject to an average resource constraint. We formulate this problem as an average-cost constrained Markov Decision Process (CMDP) and relax it into an unconstrained problem by utilizing textit{Lyapunov drift} techniques. Then, we propose a low-complexity textit{drift-plus-penalty} (DPP) policy for systems with known source/channel statistics and a Lyapunov optimization-based deep reinforcement learning (LO-DRL) policy for unknown environments. Our policies significantly reduce the number of uninformative transmissions by exploiting the timing of the important information.
6/4/2024
Estimation Network Design framework for efficient distributed optimization
Mattia Bianchi, Sergio Grammatico
0
0
Distributed decision problems features a group of agents that can only communicate over a peer-to-peer network, without a central memory. In applications such as network control and data ranking, each agent is only affected by a small portion of the decision vector: this sparsity is typically ignored in distributed algorithms, while it could be leveraged to improve efficiency and scalability. To address this issue, our recent paper introduces Estimation Network Design (END), a graph theoretical language for the analysis and design of distributed iterations. END algorithms can be tuned to exploit the sparsity of specific problem instances, reducing communication overhead and minimizing redundancy, yet without requiring case-by-case convergence analysis. In this paper, we showcase the flexility of END in the context of distributed optimization. In particular, we study the sparsity-aware version of many established methods, including ADMM, AugDGM and Push-Sum DGD. Simulations on an estimation problem in sensor networks demonstrate that END algorithms can boost convergence speed and greatly reduce the communication and memory cost.
4/24/2024