Generalization Bounds for Message Passing Networks on Mixture of Graphons
2404.03473
0
0
🐍
Abstract
We study the generalization capabilities of Message Passing Neural Networks (MPNNs), a prevalent class of Graph Neural Networks (GNN). We derive generalization bounds specifically for MPNNs with normalized sum aggregation and mean aggregation. Our analysis is based on a data generation model incorporating a finite set of template graphons. Each graph within this framework is generated by sampling from one of the graphons with a certain degree of perturbation. In particular, we extend previous MPNN generalization results to a more realistic setting, which includes the following modifications: 1) we analyze simple random graphs with Bernoulli-distributed edges instead of weighted graphs; 2) we sample both graphs and graph signals from perturbed graphons instead of clean graphons; and 3) we analyze sparse graphs instead of dense graphs. In this more realistic and challenging scenario, we provide a generalization bound that decreases as the average number of nodes in the graphs increases. Our results imply that MPNNs with higher complexity than the size of the training set can still generalize effectively, as long as the graphs are sufficiently large.
Create account to get full access
Overview
- The paper studies the generalization capabilities of Message Passing Neural Networks (MPNNs), a type of Graph Neural Network (GNN).
- The researchers derive generalization bounds specifically for MPNNs with normalized sum aggregation and mean aggregation.
- The analysis is based on a data generation model that incorporates a finite set of template graphons, where each graph is generated by sampling from one of the graphons with a certain degree of perturbation.
- The study explores a more realistic setting compared to previous MPNN generalization results, including analyzing simple random graphs with Bernoulli-distributed edges, sampling both graphs and graph signals from perturbed graphons, and analyzing sparse graphs instead of dense graphs.
Plain English Explanation
Graph Neural Networks (GNNs) are a powerful class of machine learning models that can process and learn from data represented as graphs, such as social networks, biological molecules, or transportation networks. GNNs can generalize across different graph structures, but understanding their generalization capabilities is an important challenge.
This paper focuses on a specific type of GNN called Message Passing Neural Networks (MPNNs). The researchers wanted to understand how well MPNNs can generalize to new graphs, especially in more realistic scenarios where the graphs might be sparse and slightly different from the training data.
To do this, the researchers developed a data generation model that starts with a set of "template" graphs, called graphons, and then generates new graphs by introducing some random perturbations. This allows them to study how well MPNNs can learn from a limited set of training graphs and generalize to new, slightly different graphs.
The analysis shows that MPNNs can still generalize effectively, even if the complexity of the model is higher than the size of the training set, as long as the graphs are sufficiently large. This is an important result, as it suggests that MPNNs can be applied to real-world problems with limited training data, as long as the graphs involved are large enough.
Technical Explanation
The paper analyzes the generalization capabilities of Message Passing Neural Networks (MPNNs), a prevalent class of Graph Neural Networks (GNNs). The researchers derive generalization bounds specifically for MPNNs with normalized sum aggregation and mean aggregation.
The analysis is based on a data generation model that incorporates a finite set of template graphons. Each graph within this framework is generated by sampling from one of the graphons with a certain degree of perturbation. This allows the researchers to study a more realistic setting compared to previous MPNN generalization results.
Specifically, the researchers analyze:
- Simple random graphs with Bernoulli-distributed edges, instead of weighted graphs.
- Graphs and graph signals sampled from perturbed graphons, instead of clean graphons.
- Sparse graphs, instead of dense graphs.
In this more challenging scenario, the researchers provide a generalization bound that decreases as the average number of nodes in the graphs increases. This implies that MPNNs with higher complexity than the size of the training set can still generalize effectively, as long as the graphs are sufficiently large.
The researchers' approach builds on previous work on generalization bounds for GNNs and the VC-dimension of GNNs with Pfaffian activation functions.
Critical Analysis
The paper provides a thorough analysis of the generalization capabilities of MPNNs in a more realistic setting, which is a valuable contribution to the field. However, there are a few aspects that could be further explored or addressed:
-
Sensitivity to hyperparameters: The paper does not investigate how the generalization bounds might be affected by the choice of hyperparameters, such as the number of layers or the size of the hidden representations. Understanding the sensitivity of MPNNs to these design choices could provide additional insights.
-
Practical implications: While the theoretical analysis is rigorous, the paper could benefit from a more detailed discussion of the practical implications of the results. For example, how do the findings translate to real-world applications of MPNNs, and what are the key considerations for practitioners?
-
Comparison to other GNN architectures: The paper focuses solely on MPNNs, but it would be interesting to see how the generalization capabilities of MPNNs compare to other GNN architectures, such as Graph Convolutional Networks or Graph Attention Networks.
Overall, the paper presents an important step forward in understanding the generalization properties of MPNNs, which is crucial for the broader adoption and effective application of GNNs in real-world scenarios.
Conclusion
This paper provides a thorough analysis of the generalization capabilities of Message Passing Neural Networks (MPNNs), a prevalent class of Graph Neural Networks (GNNs). The researchers derive generalization bounds for MPNNs with normalized sum aggregation and mean aggregation, and they explore a more realistic setting that includes simple random graphs, perturbed graphons, and sparse graphs.
The key finding is that MPNNs can still generalize effectively, even if the complexity of the model is higher than the size of the training set, as long as the graphs are sufficiently large. This is an important result, as it suggests that MPNNs can be applied to real-world problems with limited training data, as long as the graphs involved are large enough.
The paper contributes to the ongoing effort to understand the generalization capabilities of GNNs, which is crucial for the broader adoption and effective application of these powerful models in a wide range of domains, from social network analysis to drug discovery.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🧠
Generalization Error of Graph Neural Networks in the Mean-field Regime
Gholamali Aminian, Yixuan He, Gesine Reinert, {L}ukasz Szpruch, Samuel N. Cohen
0
0
This work provides a theoretical framework for assessing the generalization error of graph neural networks in the over-parameterized regime, where the number of parameters surpasses the quantity of data points. We explore two widely utilized types of graph neural networks: graph convolutional neural networks and message passing graph neural networks. Prior to this study, existing bounds on the generalization error in the over-parametrized regime were uninformative, limiting our understanding of over-parameterized network performance. Our novel approach involves deriving upper bounds within the mean-field regime for evaluating the generalization error of these graph neural networks. We establish upper bounds with a convergence rate of $O(1/n)$, where $n$ is the number of graph samples. These upper bounds offer a theoretical assurance of the networks' performance on unseen data in the challenging over-parameterized regime and overall contribute to our understanding of their performance.
6/18/2024
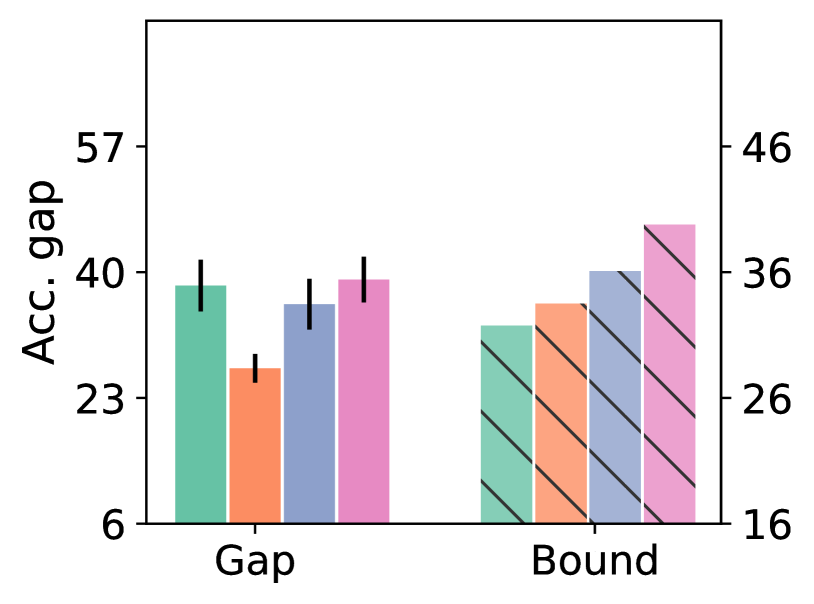
Generalization of Graph Neural Networks through the Lens of Homomorphism
Shouheng Li, Dongwoo Kim, Qing Wang
0
0
Despite the celebrated popularity of Graph Neural Networks (GNNs) across numerous applications, the ability of GNNs to generalize remains less explored. In this work, we propose to study the generalization of GNNs through a novel perspective - analyzing the entropy of graph homomorphism. By linking graph homomorphism with information-theoretic measures, we derive generalization bounds for both graph and node classifications. These bounds are capable of capturing subtleties inherent in various graph structures, including but not limited to paths, cycles and cliques. This enables a data-dependent generalization analysis with robust theoretical guarantees. To shed light on the generality of of our proposed bounds, we present a unifying framework that can characterize a broad spectrum of GNN models through the lens of graph homomorphism. We validate the practical applicability of our theoretical findings by showing the alignment between the proposed bounds and the empirically observed generalization gaps over both real-world and synthetic datasets.
4/17/2024
🧠
Transferability of Graph Neural Networks using Graphon and Sampling Theories
A. Martina Neuman, Jason J. Bramburger
0
0
Graph neural networks (GNNs) have become powerful tools for processing graph-based information in various domains. A desirable property of GNNs is transferability, where a trained network can swap in information from a different graph without retraining and retain its accuracy. A recent method of capturing transferability of GNNs is through the use of graphons, which are symmetric, measurable functions representing the limit of large dense graphs. In this work, we contribute to the application of graphons to GNNs by presenting an explicit two-layer graphon neural network (WNN) architecture. We prove its ability to approximate bandlimited graphon signals within a specified error tolerance using a minimal number of network weights. We then leverage this result, to establish the transferability of an explicit two-layer GNN over all sufficiently large graphs in a convergent sequence. Our work addresses transferability between both deterministic weighted graphs and simple random graphs and overcomes issues related to the curse of dimensionality that arise in other GNN results. The proposed WNN and GNN architectures offer practical solutions for handling graph data of varying sizes while maintaining performance guarantees without extensive retraining.
6/24/2024
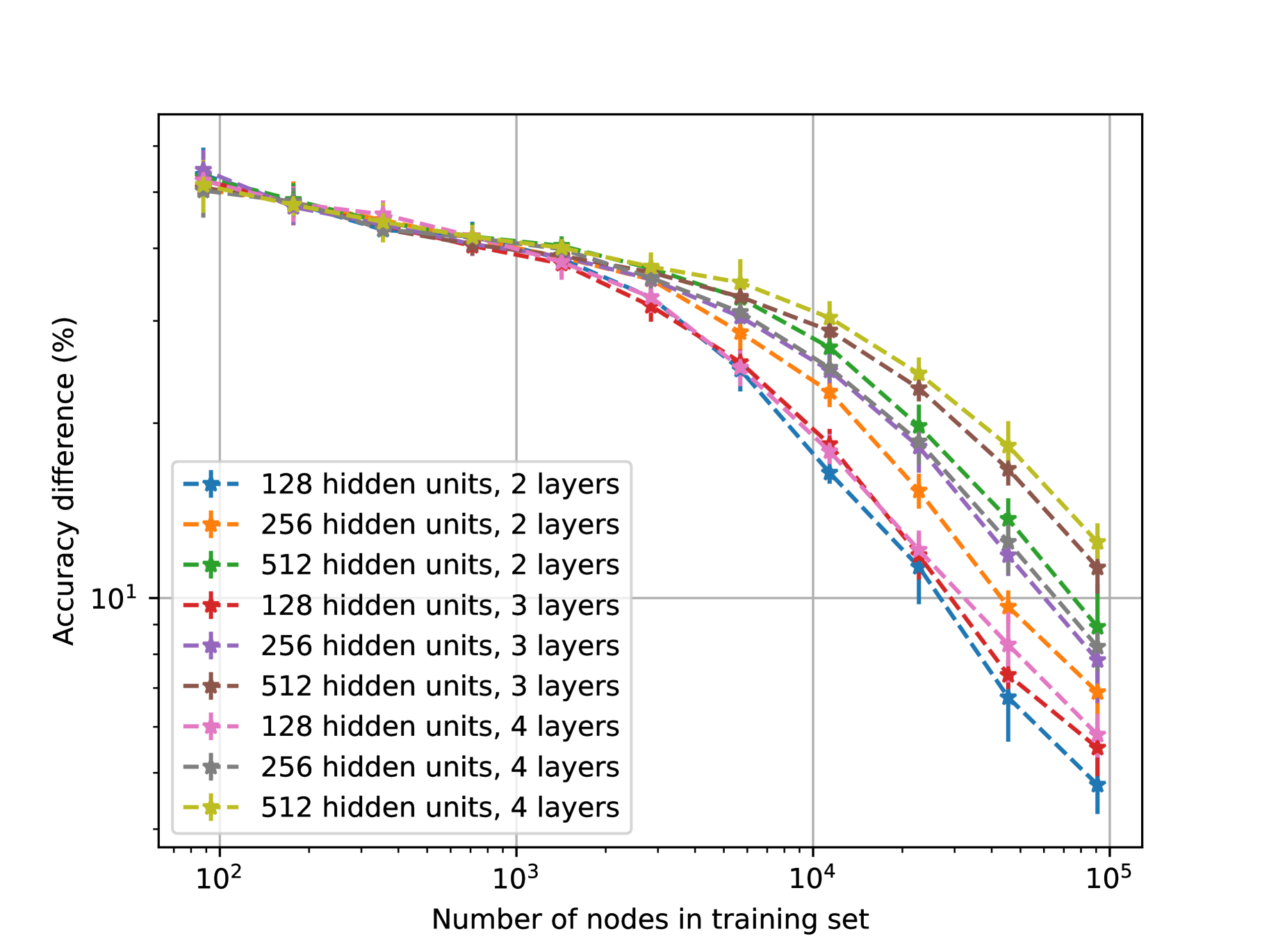
A Manifold Perspective on the Statistical Generalization of Graph Neural Networks
Zhiyang Wang, Juan Cervino, Alejandro Ribeiro
0
0
Convolutional neural networks have been successfully extended to operate on graphs, giving rise to Graph Neural Networks (GNNs). GNNs combine information from adjacent nodes by successive applications of graph convolutions. GNNs have been implemented successfully in various learning tasks while the theoretical understanding of their generalization capability is still in progress. In this paper, we leverage manifold theory to analyze the statistical generalization gap of GNNs operating on graphs constructed on sampled points from manifolds. We study the generalization gaps of GNNs on both node-level and graph-level tasks. We show that the generalization gaps decrease with the number of nodes in the training graphs, which guarantees the generalization of GNNs to unseen points over manifolds. We validate our theoretical results in multiple real-world datasets.
6/11/2024