Developing Lagrangian-based Methods for Nonsmooth Nonconvex Optimization
2404.09438
0
0

Abstract
In this paper, we consider the minimization of a nonsmooth nonconvex objective function $f(x)$ over a closed convex subset $mathcal{X}$ of $mathbb{R}^n$, with additional nonsmooth nonconvex constraints $c(x) = 0$. We develop a unified framework for developing Lagrangian-based methods, which takes a single-step update to the primal variables by some subgradient methods in each iteration. These subgradient methods are ``embedded'' into our framework, in the sense that they are incorporated as black-box updates to the primal variables. We prove that our proposed framework inherits the global convergence guarantees from these embedded subgradient methods under mild conditions. In addition, we show that our framework can be extended to solve constrained optimization problems with expectation constraints. Based on the proposed framework, we show that a wide range of existing stochastic subgradient methods, including the proximal SGD, proximal momentum SGD, and proximal ADAM, can be embedded into Lagrangian-based methods. Preliminary numerical experiments on deep learning tasks illustrate that our proposed framework yields efficient variants of Lagrangian-based methods with convergence guarantees for nonconvex nonsmooth constrained optimization problems.
Create account to get full access
Overview
- This paper presents new Lagrangian-based methods for solving nonsmooth and nonconvex optimization problems.
- The authors embed stochastic subgradient techniques into Lagrangian-based frameworks to handle challenges posed by nonsmooth and nonconvex functions.
- The proposed methods aim to achieve better convergence guarantees and practical performance compared to existing approaches.
Plain English Explanation
Optimization problems come in many forms, including those with non-smooth (not continuously differentiable) and non-convex (not bowl-shaped) objective functions. Solving these types of problems is challenging, as traditional optimization techniques may not work well.
This paper introduces new methods that combine Lagrangian-based approaches with stochastic subgradient techniques. The Lagrangian framework helps handle constraints, while the stochastic subgradient methods can deal with the non-smoothness and non-convexity of the objective function.
By integrating these two ideas, the authors aim to develop more effective optimization algorithms that can converge faster and perform better in practice compared to existing methods. The proposed techniques build on prior work in areas like near-optimal closed-loop control and accelerated forward-backward algorithms.
Overall, the paper presents new tools for tackling challenging optimization problems that arise in many real-world applications, from engineering to machine learning.
Technical Explanation
The authors consider general nonsmooth, nonconvex optimization problems with both equality and inequality constraints. To solve these problems, they propose novel Lagrangian-based methods that embed stochastic subgradient techniques.
The key idea is to reformulate the original problem into an equivalent saddle-point problem using Lagrange multipliers. This allows the authors to leverage the strengths of Lagrangian methods, which can handle constraints effectively, while also incorporating stochastic subgradient updates to cope with the non-smoothness and non-convexity of the objective function.
The proposed algorithms extend prior work on randomized Bregman Kaczmarz methods and stochastic online optimization to the Lagrangian setting. The authors provide convergence guarantees for their methods, showing that they can achieve stationary points or local minima under suitable assumptions.
Through numerical experiments, the authors demonstrate the practical performance of their Lagrangian-based algorithms on a variety of nonsmooth, nonconvex optimization problems, including those arising in machine learning and signal processing applications.
Critical Analysis
The paper presents a promising approach for tackling nonsmooth, nonconvex optimization problems, which are ubiquitous in many real-world applications. By embedding stochastic subgradient methods into Lagrangian-based frameworks, the authors aim to develop more robust and effective optimization techniques.
However, the paper does not fully address the potential limitations of the proposed methods. For example, the convergence guarantees rely on certain assumptions, such as the existence of saddle points and the ability to solve the subproblems efficiently. In practice, these assumptions may not always hold, and the performance of the algorithms may be sensitive to the choice of parameters and initialization.
Moreover, the paper does not provide a detailed comparison to other state-of-the-art methods for nonsmooth, nonconvex optimization, such as proximal gradient algorithms or alternating direction methods of multipliers (ADMM). A more comprehensive empirical evaluation would help readers understand the relative strengths and weaknesses of the Lagrangian-based approaches presented in this work.
Nevertheless, the paper makes a valuable contribution by introducing a new class of optimization methods that can potentially address a wide range of challenging problems. Further research may focus on relaxing the assumptions, improving the practical robustness of the algorithms, and exploring their applications in diverse domains.
Conclusion
This paper introduces novel Lagrangian-based optimization methods for solving nonsmooth, nonconvex problems with both equality and inequality constraints. By embedding stochastic subgradient techniques into the Lagrangian framework, the authors develop optimization algorithms that can handle the challenges posed by non-smooth and non-convex objective functions.
The proposed methods offer theoretical convergence guarantees and demonstrate promising practical performance on a variety of optimization problems. This work expands the toolbox of techniques available for tackling complex real-world optimization challenges, with potential applications in fields such as machine learning, signal processing, and engineering.
While the paper does not fully address the limitations of the proposed methods, it represents a significant step forward in the development of effective optimization algorithms for nonsmooth, nonconvex problems. Future research in this direction may lead to further advancements and the widespread adoption of these techniques in diverse applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛠️
SGD-type Methods with Guaranteed Global Stability in Nonsmooth Nonconvex Optimization
Nachuan Xiao, Xiaoyin Hu, Kim-Chuan Toh
0
0
In this paper, we focus on providing convergence guarantees for variants of the stochastic subgradient descent (SGD) method in minimizing nonsmooth nonconvex functions. We first develop a general framework to establish global stability for general stochastic subgradient methods, where the corresponding differential inclusion admits a coercive Lyapunov function. We prove that, with sufficiently small stepsizes and controlled noises, the iterates asymptotically stabilize around the stable set of its corresponding differential inclusion. Then we introduce a scheme for developing SGD-type methods with regularized update directions for the primal variables. Based on our developed framework, we prove the global stability of our proposed scheme under mild conditions. We further illustrate that our scheme yields variants of SGD-type methods, which enjoy guaranteed convergence in training nonsmooth neural networks. In particular, by employing the sign map to regularize the update directions, we propose a novel subgradient method named the Sign-map Regularized SGD method (SRSGD). Preliminary numerical experiments exhibit the high efficiency of SRSGD in training deep neural networks.
5/15/2024
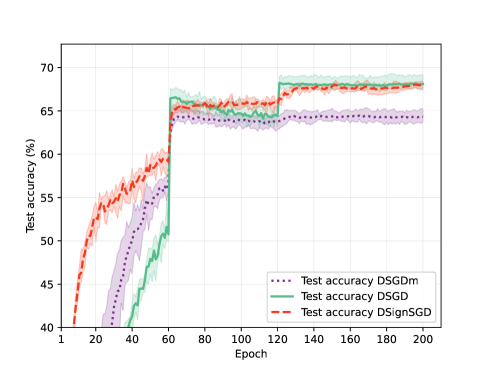
Decentralized Stochastic Subgradient Methods for Nonsmooth Nonconvex Optimization
Siyuan Zhang, Nachuan Xiao, Xin Liu
0
0
In this paper, we concentrate on decentralized optimization problems with nonconvex and nonsmooth objective functions, especially on the decentralized training of nonsmooth neural networks. We introduce a unified framework to analyze the global convergence of decentralized stochastic subgradient-based methods. We prove the global convergence of our proposed framework under mild conditions, by establishing that the generated sequence asymptotically approximates the trajectories of its associated differential inclusion. Furthermore, we establish that our proposed framework covers a wide range of existing efficient decentralized subgradient-based methods, including decentralized stochastic subgradient descent (DSGD), DSGD with gradient-tracking technique (DSGD-T), and DSGD with momentum (DSGD-M). In addition, we introduce the sign map to regularize the update directions in DSGD-M, and show it is enclosed in our proposed framework. Consequently, our convergence results establish, for the first time, global convergence of these methods when applied to nonsmooth nonconvex objectives. Preliminary numerical experiments demonstrate that our proposed framework yields highly efficient decentralized subgradient-based methods with convergence guarantees in the training of nonsmooth neural networks.
6/28/2024
A Functional Model Method for Nonconvex Nonsmooth Conditional Stochastic Optimization
Andrzej Ruszczy'nski, Shangzhe Yang
0
0
We consider stochastic optimization problems involving an expected value of a nonlinear function of a base random vector and a conditional expectation of another function depending on the base random vector, a dependent random vector, and the decision variables. We call such problems conditional stochastic optimization problems. They arise in many applications, such as uplift modeling, reinforcement learning, and contextual optimization. We propose a specialized single time-scale stochastic method for nonconvex constrained conditional stochastic optimization problems with a Lipschitz smooth outer function and a generalized differentiable inner function. In the method, we approximate the inner conditional expectation with a rich parametric model whose mean squared error satisfies a stochastic version of a {L}ojasiewicz condition. The model is used by an inner learning algorithm. The main feature of our approach is that unbiased stochastic estimates of the directions used by the method can be generated with one observation from the joint distribution per iteration, which makes it applicable to real-time learning. The directions, however, are not gradients or subgradients of any overall objective function. We prove the convergence of the method with probability one, using the method of differential inclusions and a specially designed Lyapunov function, involving a stochastic generalization of the Bregman distance. Finally, a numerical illustration demonstrates the viability of our approach.
5/20/2024
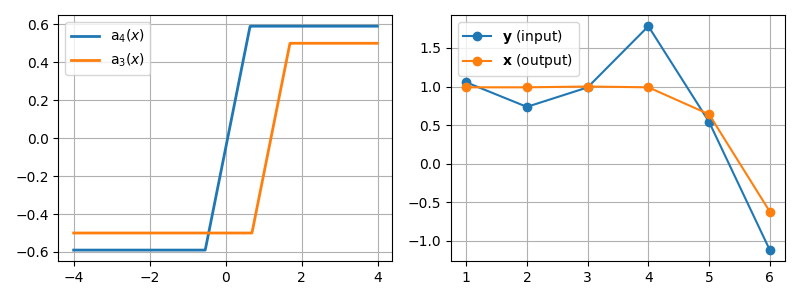
Untangling Lariats: Subgradient Following of Variationally Penalized Objectives
Kai-Chia Mo, Shai Shalev-Shwartz, Nis{ae}l Sh'artov
0
0
We describe a novel subgradient following apparatus for calculating the optimum of convex problems with variational penalties. In this setting, we receive a sequence $y_i,ldots,y_n$ and seek a smooth sequence $x_1,ldots,x_n$. The smooth sequence attains the minimum Bregman divergence to an input sequence with additive variational penalties in the general form of $sum_i g_i(x_{i+1}-x_i)$. We derive, as special cases of our apparatus, known algorithms for the fused lasso and isotonic regression. Our approach also facilitates new variational penalties such as non-smooth barrier functions. We next derive and analyze multivariate problems in which $mathbf{x}_i,mathbf{y}_iinmathbb{R}^d$ and variational penalties that depend on $|mathbf{x}_{i+1}-mathbf{x}_i|$. The norms we consider are $ell_2$ and $ell_infty$ which promote group sparsity. Last but not least, we derive a lattice-based subgradient following for variational penalties characterized through the output of arbitrary convolutional filters. This paradigm yields efficient solvers for problems in which sparse high-order discrete derivatives such as acceleration and jerk are desirable.
5/9/2024