Efficient Multi-agent Reinforcement Learning by Planning
2405.11778
0
0

Abstract
Multi-agent reinforcement learning (MARL) algorithms have accomplished remarkable breakthroughs in solving large-scale decision-making tasks. Nonetheless, most existing MARL algorithms are model-free, limiting sample efficiency and hindering their applicability in more challenging scenarios. In contrast, model-based reinforcement learning (MBRL), particularly algorithms integrating planning, such as MuZero, has demonstrated superhuman performance with limited data in many tasks. Hence, we aim to boost the sample efficiency of MARL by adopting model-based approaches. However, incorporating planning and search methods into multi-agent systems poses significant challenges. The expansive action space of multi-agent systems often necessitates leveraging the nearly-independent property of agents to accelerate learning. To tackle this issue, we propose the MAZero algorithm, which combines a centralized model with Monte Carlo Tree Search (MCTS) for policy search. We design a novel network structure to facilitate distributed execution and parameter sharing. To enhance search efficiency in deterministic environments with sizable action spaces, we introduce two novel techniques: Optimistic Search Lambda (OS($lambda$)) and Advantage-Weighted Policy Optimization (AWPO). Extensive experiments on the SMAC benchmark demonstrate that MAZero outperforms model-free approaches in terms of sample efficiency and provides comparable or better performance than existing model-based methods in terms of both sample and computational efficiency. Our code is available at https://github.com/liuqh16/MAZero.
Create account to get full access
Overview
- This paper proposes a novel approach for efficient multi-agent reinforcement learning (MARL) using planning.
- The key idea is to leverage planning to guide the exploration of agents, leading to faster learning and better performance compared to traditional MARL methods.
- The proposed approach, called Efficient Multi-agent Reinforcement Learning by Planning, is evaluated on several challenging multi-agent environments.
Plain English Explanation
In this paper, the researchers developed a new way to help artificial intelligence (AI) agents learn faster and perform better in multi-agent environments. Traditional reinforcement learning approaches for multi-agent systems can be slow and inefficient, as the agents have to explore the environment blindly to learn optimal behaviors.
The researchers' key insight was to use planning algorithms to guide the exploration of the agents. By allowing the agents to plan ahead and reason about the long-term consequences of their actions, they can make more informed decisions and learn more efficiently. This planning-based approach leads to faster convergence to optimal behaviors compared to standard reinforcement learning methods.
The researchers evaluated their Efficient Multi-agent Reinforcement Learning by Planning approach on several challenging multi-agent environments, where the agents needed to cooperate and coordinate their actions to achieve the desired goals. The results showed that their planning-based method outperformed traditional MARL approaches, demonstrating the benefits of incorporating planning into the learning process.
Technical Explanation
The paper Efficient Multi-agent Reinforcement Learning by Planning presents a novel framework for efficient MARL by leveraging planning. The key components of the proposed approach are:
-
Decentralized Planning: Each agent maintains its own planning module, which is responsible for generating action plans based on the agent's local observations and beliefs about the environment and other agents.
-
Centralized Critic: The agents share a centralized critic network that estimates the expected return of the joint actions taken by all agents. This critic network is trained using the planned action sequences from the agents.
-
Guided Exploration: The planned action sequences from the agents' planning modules are used to guide the exploration during the reinforcement learning process, leading to faster convergence to optimal behaviors.
The researchers evaluated their approach on several challenging multi-agent environments, including higher-replay-ratio-empowers-sample-efficient-multi, maexp-generic-platform-rl-based-multi-agent, heterogeneous-multi-agent-reinforcement-learning-zero-shot, marl-lns-cooperative-multi-agent-reinforcement-learning, and randomized-exploration-cooperative-multi-agent-reinforcement-learning. The results demonstrated that their planning-based approach outperformed standard MARL methods in terms of sample efficiency and final performance.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the proposed Efficient Multi-agent Reinforcement Learning by Planning approach. The authors acknowledge that their method relies on the availability of a centralized critic network, which may not be feasible in all real-world scenarios. Additionally, the paper does not discuss the computational complexity of the planning-based approach, which could be a limiting factor in larger-scale multi-agent systems.
Further research could explore ways to make the planning process more scalable and distributed, potentially by leveraging techniques like hierarchical planning or multi-agent coordination algorithms. Additionally, it would be valuable to investigate the robustness of the approach to partial observability, noisy observations, and other realistic challenges in multi-agent environments.
Conclusion
The paper Efficient Multi-agent Reinforcement Learning by Planning presents a novel framework for improving the efficiency and performance of MARL by incorporating planning into the learning process. The key idea of using planning to guide exploration has been shown to outperform standard MARL methods in several challenging environments.
This work contributes to the ongoing efforts to develop more scalable and effective MARL algorithms, which have important applications in areas like robotics, autonomous systems, and multi-agent simulations. The planning-based approach offers a promising direction for further research and development in this field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Representation Learning For Efficient Deep Multi-Agent Reinforcement Learning
Dom Huh, Prasant Mohapatra
0
0
Sample efficiency remains a key challenge in multi-agent reinforcement learning (MARL). A promising approach is to learn a meaningful latent representation space through auxiliary learning objectives alongside the MARL objective to aid in learning a successful control policy. In our work, we present MAPO-LSO (Multi-Agent Policy Optimization with Latent Space Optimization) which applies a form of comprehensive representation learning devised to supplement MARL training. Specifically, MAPO-LSO proposes a multi-agent extension of transition dynamics reconstruction and self-predictive learning that constructs a latent state optimization scheme that can be trivially extended to current state-of-the-art MARL algorithms. Empirical results demonstrate MAPO-LSO to show notable improvements in sample efficiency and learning performance compared to its vanilla MARL counterpart without any additional MARL hyperparameter tuning on a diverse suite of MARL tasks.
6/6/2024
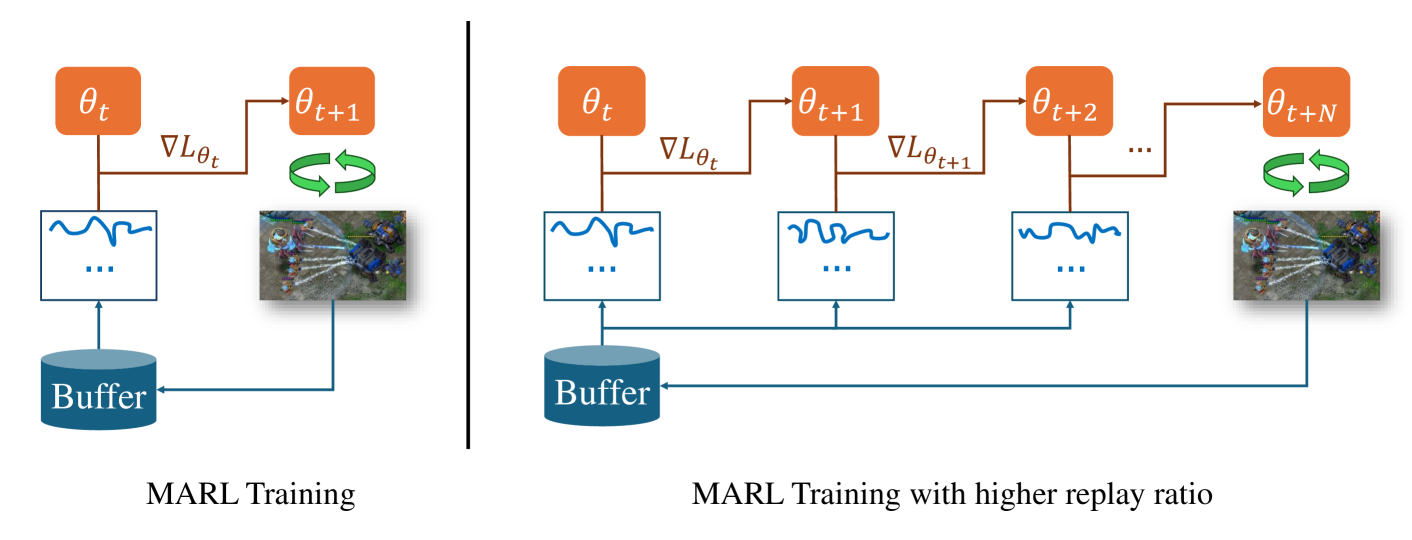
Higher Replay Ratio Empowers Sample-Efficient Multi-Agent Reinforcement Learning
Linjie Xu, Zichuan Liu, Alexander Dockhorn, Diego Perez-Liebana, Jinyu Wang, Lei Song, Jiang Bian
0
0
One of the notorious issues for Reinforcement Learning (RL) is poor sample efficiency. Compared to single agent RL, the sample efficiency for Multi-Agent Reinforcement Learning (MARL) is more challenging because of its inherent partial observability, non-stationary training, and enormous strategy space. Although much effort has been devoted to developing new methods and enhancing sample efficiency, we look at the widely used episodic training mechanism. In each training step, tens of frames are collected, but only one gradient step is made. We argue that this episodic training could be a source of poor sample efficiency. To better exploit the data already collected, we propose to increase the frequency of the gradient updates per environment interaction (a.k.a. Replay Ratio or Update-To-Data ratio). To show its generality, we evaluate $3$ MARL methods on $6$ SMAC tasks. The empirical results validate that a higher replay ratio significantly improves the sample efficiency for MARL algorithms. The codes to reimplement the results presented in this paper are open-sourced at https://anonymous.4open.science/r/rr_for_MARL-0D83/.
4/16/2024

Heterogeneous Multi-Agent Reinforcement Learning for Zero-Shot Scalable Collaboration
Xudong Guo, Daming Shi, Junjie Yu, Wenhui Fan
0
0
The rise of multi-agent systems, especially the success of multi-agent reinforcement learning (MARL), is reshaping our future across diverse domains like autonomous vehicle networks. However, MARL still faces significant challenges, particularly in achieving zero-shot scalability, which allows trained MARL models to be directly applied to unseen tasks with varying numbers of agents. In addition, real-world multi-agent systems usually contain agents with different functions and strategies, while the existing scalable MARL methods only have limited heterogeneity. To address this, we propose a novel MARL framework named Scalable and Heterogeneous Proximal Policy Optimization (SHPPO), integrating heterogeneity into parameter-shared PPO-based MARL networks. we first leverage a latent network to adaptively learn strategy patterns for each agent. Second, we introduce a heterogeneous layer for decision-making, whose parameters are specifically generated by the learned latent variables. Our approach is scalable as all the parameters are shared except for the heterogeneous layer, and gains both inter-individual and temporal heterogeneity at the same time. We implement our approach based on the state-of-the-art backbone PPO-based algorithm as SHPPO, while our approach is agnostic to the backbone and can be seamlessly plugged into any parameter-shared MARL method. SHPPO exhibits superior performance over the baselines such as MAPPO and HAPPO in classic MARL environments like Starcraft Multi-Agent Challenge (SMAC) and Google Research Football (GRF), showcasing enhanced zero-shot scalability and offering insights into the learned latent representation's impact on team performance by visualization.
4/8/2024
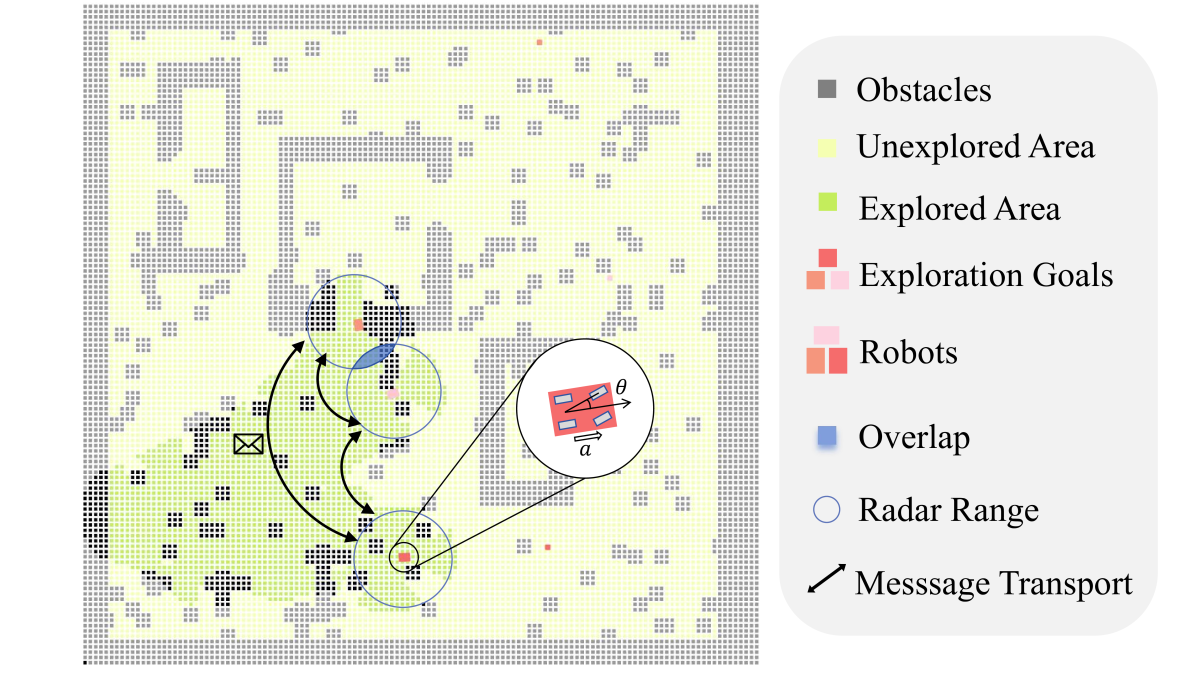
MAexp: A Generic Platform for RL-based Multi-Agent Exploration
Shaohao Zhu, Jiacheng Zhou, Anjun Chen, Mingming Bai, Jiming Chen, Jinming Xu
0
0
The sim-to-real gap poses a significant challenge in RL-based multi-agent exploration due to scene quantization and action discretization. Existing platforms suffer from the inefficiency in sampling and the lack of diversity in Multi-Agent Reinforcement Learning (MARL) algorithms across different scenarios, restraining their widespread applications. To fill these gaps, we propose MAexp, a generic platform for multi-agent exploration that integrates a broad range of state-of-the-art MARL algorithms and representative scenarios. Moreover, we employ point clouds to represent our exploration scenarios, leading to high-fidelity environment mapping and a sampling speed approximately 40 times faster than existing platforms. Furthermore, equipped with an attention-based Multi-Agent Target Generator and a Single-Agent Motion Planner, MAexp can work with arbitrary numbers of agents and accommodate various types of robots. Extensive experiments are conducted to establish the first benchmark featuring several high-performance MARL algorithms across typical scenarios for robots with continuous actions, which highlights the distinct strengths of each algorithm in different scenarios.
4/22/2024