Efficient World Models with Context-Aware Tokenization
2406.19320
0
0

Abstract
Scaling up deep Reinforcement Learning (RL) methods presents a significant challenge. Following developments in generative modelling, model-based RL positions itself as a strong contender. Recent advances in sequence modelling have led to effective transformer-based world models, albeit at the price of heavy computations due to the long sequences of tokens required to accurately simulate environments. In this work, we propose $Delta$-IRIS, a new agent with a world model architecture composed of a discrete autoencoder that encodes stochastic deltas between time steps and an autoregressive transformer that predicts future deltas by summarizing the current state of the world with continuous tokens. In the Crafter benchmark, $Delta$-IRIS sets a new state of the art at multiple frame budgets, while being an order of magnitude faster to train than previous attention-based approaches. We release our code and models at https://github.com/vmicheli/delta-iris.
Create account to get full access
Overview
- This paper proposes a new approach for efficient world models using context-aware tokenization.
- The key idea is to leverage context information to learn more compact and expressive token representations, improving the efficiency and performance of world models.
- The method is evaluated on several Atari game environments, demonstrating improved sample efficiency and decision-making capabilities compared to previous world model approaches.
Plain English Explanation
In the field of reinforcement learning, world models have emerged as a powerful tool for training agents to interact with and make decisions in complex environments. World models are essentially internal representations that an agent builds to understand and predict how its environment works.
The authors of this paper have developed a new approach to make world models more efficient and effective. The core insight is that by considering the context in which tokens (or small units of information) appear, the agent can learn more compact and meaningful representations. This context-aware tokenization allows the world model to capture relevant details while discarding unnecessary information, leading to improved sample efficiency and decision-making performance.
To evaluate their method, the researchers tested it on several classic Atari video games, where the agent needs to learn to interact with the game environment to achieve its goals. The results show that the context-aware world model outperforms previous approaches, demonstrating its potential to be a more powerful and efficient tool for a wide range of reinforcement learning tasks.
Technical Explanation
The paper introduces a context-aware tokenization approach to improve the efficiency of world models. The key innovation is the use of a context encoder, which takes into account the surrounding information when representing individual tokens. This allows the model to learn more compact and expressive representations, capturing the relevant contextual cues.
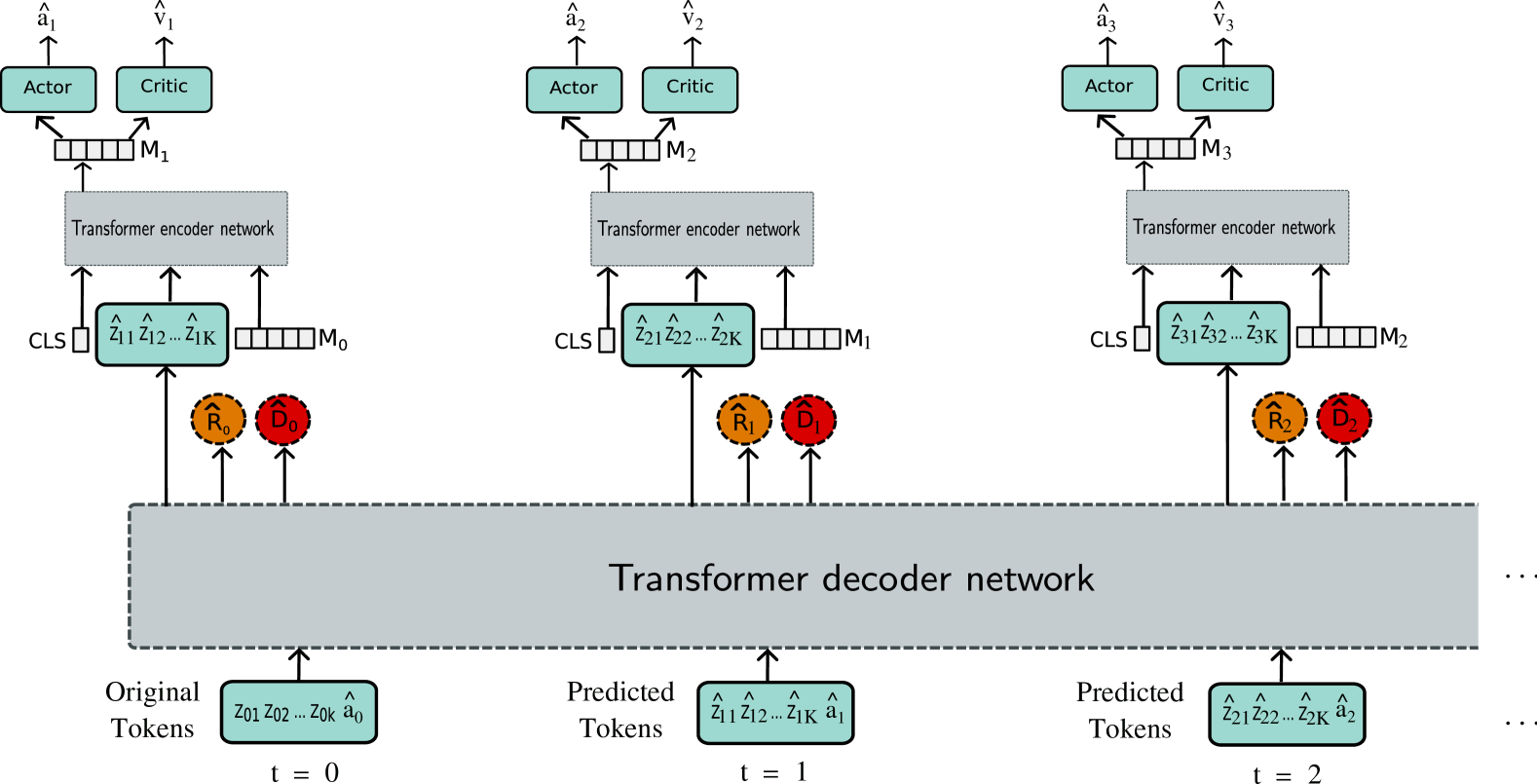
The proposed architecture consists of three main components:
- Encoder: This module takes in the raw observations (e.g., game frames) and encodes them into a latent representation.
- Context Encoder: This component learns to encode the contextual information around each token, using techniques like self-attention and slot encoding.
- Decoder: The decoder takes the latent representation and the context-aware token embeddings to predict the next observation and reward.
The authors demonstrate the effectiveness of their approach on several Atari game environments, where the context-aware world model outperforms previous methods in terms of sample efficiency and decision-making performance. This suggests that leveraging contextual information can lead to more powerful and compact world models, with potential applications in reinforcement learning, decision-making, and physical world modeling.
Critical Analysis
The paper presents a compelling approach to improving the efficiency of world models, and the experimental results on Atari games are promising. However, the authors do not extensively discuss the limitations of their method or potential issues that may arise in more complex or real-world environments.
For example, the context-aware tokenization may be more susceptible to overfitting or brittleness in the face of significant environmental changes or distribution shifts. Additionally, the authors do not explore the scalability of their approach to larger, more complex domains, such as those encountered in natural language or high-fidelity visual environments.
Further research could investigate the robustness of the context-aware world models, their ability to generalize to unseen situations, and their potential applications in real-world decision-making systems. Exploring these aspects would help strengthen the practical relevance and impact of the proposed approach.
Conclusion
This paper introduces a novel context-aware tokenization method for building efficient world models in reinforcement learning. By leveraging contextual information to learn more compact and expressive token representations, the proposed approach demonstrates improved sample efficiency and decision-making capabilities compared to previous world model architectures.
The findings of this research suggest that context-aware modeling can be a powerful tool for developing more robust and effective agents, with potential applications in a wide range of domains, from video games to real-world decision-making systems. As the field of reinforcement learning continues to advance, techniques like the one presented in this paper will be crucial for building agents that can navigate complex environments and make informed decisions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Learning to Play Atari in a World of Tokens
Pranav Agarwal, Sheldon Andrews, Samira Ebrahimi Kahou
0
0
Model-based reinforcement learning agents utilizing transformers have shown improved sample efficiency due to their ability to model extended context, resulting in more accurate world models. However, for complex reasoning and planning tasks, these methods primarily rely on continuous representations. This complicates modeling of discrete properties of the real world such as disjoint object classes between which interpolation is not plausible. In this work, we introduce discrete abstract representations for transformer-based learning (DART), a sample-efficient method utilizing discrete representations for modeling both the world and learning behavior. We incorporate a transformer-decoder for auto-regressive world modeling and a transformer-encoder for learning behavior by attending to task-relevant cues in the discrete representation of the world model. For handling partial observability, we aggregate information from past time steps as memory tokens. DART outperforms previous state-of-the-art methods that do not use look-ahead search on the Atari 100k sample efficiency benchmark with a median human-normalized score of 0.790 and beats humans in 9 out of 26 games. We release our code at https://pranaval.github.io/DART/.
6/4/2024

Decentralized Transformers with Centralized Aggregation are Sample-Efficient Multi-Agent World Models
Yang Zhang, Chenjia Bai, Bin Zhao, Junchi Yan, Xiu Li, Xuelong Li
0
0
Learning a world model for model-free Reinforcement Learning (RL) agents can significantly improve the sample efficiency by learning policies in imagination. However, building a world model for Multi-Agent RL (MARL) can be particularly challenging due to the scalability issue in a centralized architecture arising from a large number of agents, and also the non-stationarity issue in a decentralized architecture stemming from the inter-dependency among agents. To address both challenges, we propose a novel world model for MARL that learns decentralized local dynamics for scalability, combined with a centralized representation aggregation from all agents. We cast the dynamics learning as an auto-regressive sequence modeling problem over discrete tokens by leveraging the expressive Transformer architecture, in order to model complex local dynamics across different agents and provide accurate and consistent long-term imaginations. As the first pioneering Transformer-based world model for multi-agent systems, we introduce a Perceiver Transformer as an effective solution to enable centralized representation aggregation within this context. Results on Starcraft Multi-Agent Challenge (SMAC) show that it outperforms strong model-free approaches and existing model-based methods in both sample efficiency and overall performance.
6/26/2024

Transformers and Slot Encoding for Sample Efficient Physical World Modelling
Francesco Petri, Luigi Asprino, Aldo Gangemi
0
0
World modelling, i.e. building a representation of the rules that govern the world so as to predict its evolution, is an essential ability for any agent interacting with the physical world. Recent applications of the Transformer architecture to the problem of world modelling from video input show notable improvements in sample efficiency. However, existing approaches tend to work only at the image level thus disregarding that the environment is composed of objects interacting with each other. In this paper, we propose an architecture combining Transformers for world modelling with the slot-attention paradigm, an approach for learning representations of objects appearing in a scene. We describe the resulting neural architecture and report experimental results showing an improvement over the existing solutions in terms of sample efficiency and a reduction of the variation of the performance over the training examples. The code for our architecture and experiments is available at https://github.com/torchipeppo/transformers-and-slot-encoding-for-wm
5/31/2024
🌀
Diffusion for World Modeling: Visual Details Matter in Atari
Eloi Alonso, Adam Jelley, Vincent Micheli, Anssi Kanervisto, Amos Storkey, Tim Pearce, Franc{c}ois Fleuret
0
0
World models constitute a promising approach for training reinforcement learning agents in a safe and sample-efficient manner. Recent world models predominantly operate on sequences of discrete latent variables to model environment dynamics. However, this compression into a compact discrete representation may ignore visual details that are important for reinforcement learning. Concurrently, diffusion models have become a dominant approach for image generation, challenging well-established methods modeling discrete latents. Motivated by this paradigm shift, we introduce DIAMOND (DIffusion As a Model Of eNvironment Dreams), a reinforcement learning agent trained in a diffusion world model. We analyze the key design choices that are required to make diffusion suitable for world modeling, and demonstrate how improved visual details can lead to improved agent performance. DIAMOND achieves a mean human normalized score of 1.46 on the competitive Atari 100k benchmark; a new best for agents trained entirely within a world model. To foster future research on diffusion for world modeling, we release our code, agents and playable world models at https://github.com/eloialonso/diamond.
5/22/2024