Transformers and Slot Encoding for Sample Efficient Physical World Modelling
2405.20180
0
0

Abstract
World modelling, i.e. building a representation of the rules that govern the world so as to predict its evolution, is an essential ability for any agent interacting with the physical world. Recent applications of the Transformer architecture to the problem of world modelling from video input show notable improvements in sample efficiency. However, existing approaches tend to work only at the image level thus disregarding that the environment is composed of objects interacting with each other. In this paper, we propose an architecture combining Transformers for world modelling with the slot-attention paradigm, an approach for learning representations of objects appearing in a scene. We describe the resulting neural architecture and report experimental results showing an improvement over the existing solutions in terms of sample efficiency and a reduction of the variation of the performance over the training examples. The code for our architecture and experiments is available at https://github.com/torchipeppo/transformers-and-slot-encoding-for-wm
Create account to get full access
Introduction
Problem statement
The paper explores the use of transformers and slot encoding to create sample-efficient models for physical world modelling. Transformers, a type of neural network architecture, have shown promising results in various domains, including natural language processing and computer vision. The authors aim to investigate how transformers and slot encoding can be leveraged to build models that can learn from a small number of samples, which is crucial for practical applications in the physical world.
Overview
- The paper investigates the use of transformers and slot encoding for sample-efficient physical world modelling.
- Transformers have demonstrated success in various domains, and the authors explore how they can be applied to physical world modelling.
- Slot encoding is a technique used to represent and reason about structured data, which the authors hypothesize can improve sample efficiency.
Plain English Explanation
The paper is exploring a way to create machine learning models that can learn about the physical world using a small number of examples. This is important because in the real world, we often don't have access to large datasets, and we need models that can learn quickly from limited information.
The researchers are using a type of machine learning model called a transformer, which has been successful in areas like natural language processing and computer vision. They are also using a technique called "slot encoding" to represent and reason about structured data, which they think can help improve the sample efficiency of the models.
The goal is to develop models that can accurately simulate or predict how the physical world works, even when they only have a small number of examples to learn from. This could have important applications in areas like robotics, where the models need to be able to adapt to new environments and situations quickly.
Technical Explanation
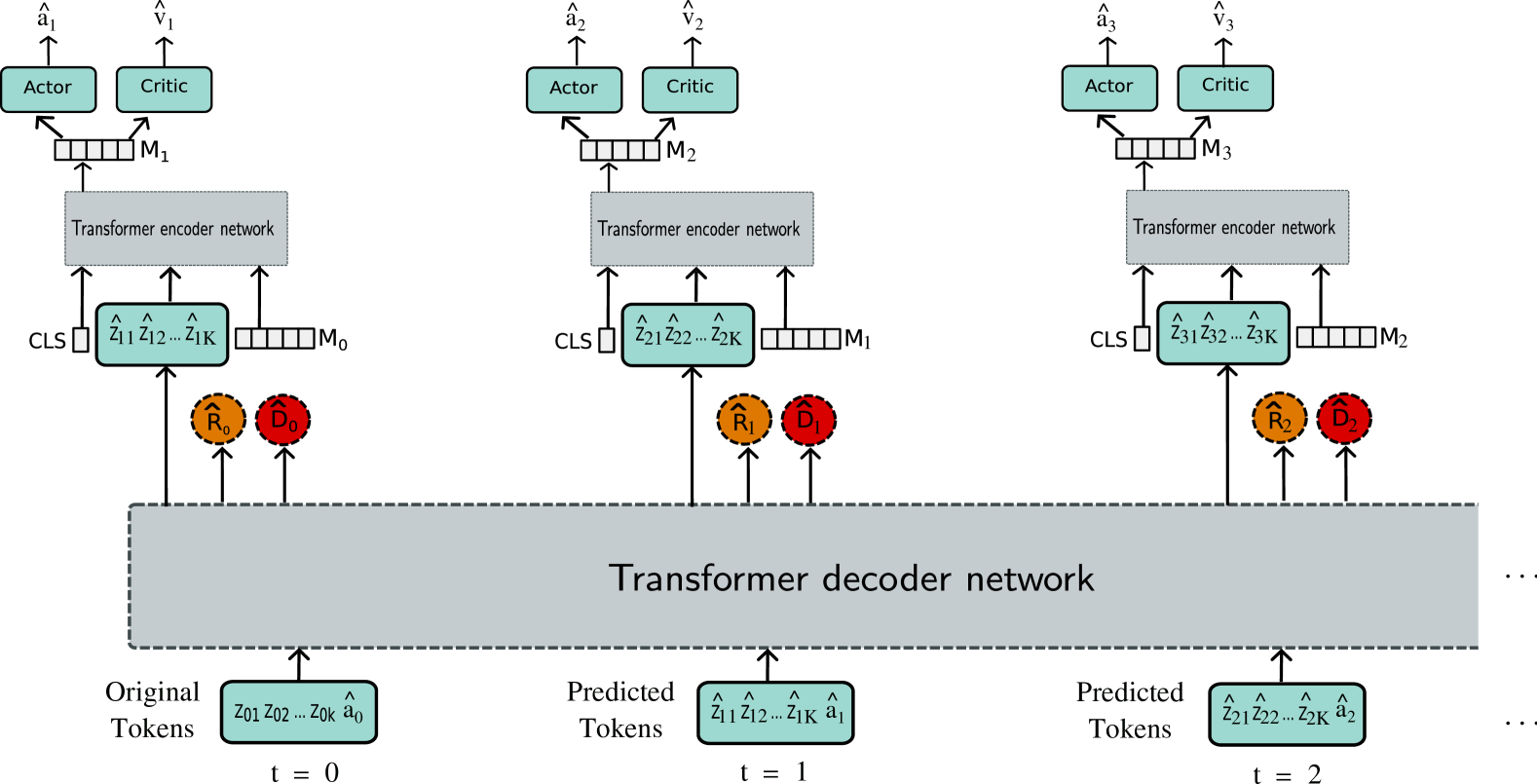
The paper investigates the use of transformers and slot encoding for sample-efficient physical world modelling. Transformers are a type of neural network architecture that has shown impressive results in various domains, including natural language processing and computer vision. The authors hypothesize that the relational inductive bias and attention mechanism of transformers can be leveraged to build models that can learn from a small number of samples, which is crucial for practical applications in the physical world.
To enhance the sample efficiency of the transformer-based models, the authors introduce a slot encoding scheme. Slot encoding is a technique used to represent and reason about structured data, where each slot corresponds to a specific entity or part of the input. By using slot encoding, the model can more effectively capture the underlying structure of the physical world, leading to improved sample efficiency.
The paper presents experiments that demonstrate the effectiveness of the proposed approach. The authors compare the performance of transformer-based models with slot encoding to other baselines, such as convolutional neural networks and recurrent neural networks, on various physical world tasks. The results show that the transformer-based models with slot encoding outperform the baselines in terms of sample efficiency, suggesting that this approach is a promising direction for building practical physical world models.
Critical Analysis
The paper presents a compelling approach to improving the sample efficiency of physical world modelling using transformers and slot encoding. The authors make a strong case for the potential benefits of this approach, citing the relational inductive bias and attention mechanism of transformers, as well as the structured representation afforded by slot encoding.
However, the paper does not address some potential limitations or concerns. For example, the authors do not discuss the scalability of the proposed approach, particularly as the complexity of the physical world tasks increases. Additionally, the paper does not explore the interpretability and transparency of the transformer-based models, which could be important for understanding and verifying the models' behavior in safety-critical applications.
Furthermore, the authors could have provided more detailed insights into the specific mechanisms and architectural choices that contribute to the improved sample efficiency. A deeper analysis of the model's internal workings and how the slot encoding scheme interacts with the transformer's attention mechanism would help readers better understand the underlying principles driving the performance gains.
Despite these potential limitations, the paper presents a valuable contribution to the field of physical world modelling by demonstrating the potential of transformers and slot encoding to address the challenge of sample efficiency. The results are promising and warrant further investigation and exploration by the research community.
Conclusion
The paper explores the use of transformers and slot encoding to develop sample-efficient models for physical world modelling. The authors hypothesize that the relational inductive bias and attention mechanism of transformers, combined with the structured representation of slot encoding, can lead to improved sample efficiency compared to other neural network architectures.
The experimental results presented in the paper support this hypothesis, with the transformer-based models with slot encoding outperforming the baselines in terms of sample efficiency on various physical world tasks. This suggests that this approach could have important implications for practical applications in fields such as robotics, where models need to quickly adapt to new environments and situations.
While the paper does not address all potential limitations, it represents a valuable contribution to the ongoing research on sample-efficient physical world modelling. The findings pave the way for further exploration and development of transformer-based models with structured representations, which could lead to more robust and practical solutions for simulating and predicting the behavior of the physical world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Decentralized Transformers with Centralized Aggregation are Sample-Efficient Multi-Agent World Models
Yang Zhang, Chenjia Bai, Bin Zhao, Junchi Yan, Xiu Li, Xuelong Li
0
0
Learning a world model for model-free Reinforcement Learning (RL) agents can significantly improve the sample efficiency by learning policies in imagination. However, building a world model for Multi-Agent RL (MARL) can be particularly challenging due to the scalability issue in a centralized architecture arising from a large number of agents, and also the non-stationarity issue in a decentralized architecture stemming from the inter-dependency among agents. To address both challenges, we propose a novel world model for MARL that learns decentralized local dynamics for scalability, combined with a centralized representation aggregation from all agents. We cast the dynamics learning as an auto-regressive sequence modeling problem over discrete tokens by leveraging the expressive Transformer architecture, in order to model complex local dynamics across different agents and provide accurate and consistent long-term imaginations. As the first pioneering Transformer-based world model for multi-agent systems, we introduce a Perceiver Transformer as an effective solution to enable centralized representation aggregation within this context. Results on Starcraft Multi-Agent Challenge (SMAC) show that it outperforms strong model-free approaches and existing model-based methods in both sample efficiency and overall performance.
6/26/2024

Efficient World Models with Context-Aware Tokenization
Vincent Micheli, Eloi Alonso, Franc{c}ois Fleuret
0
0
Scaling up deep Reinforcement Learning (RL) methods presents a significant challenge. Following developments in generative modelling, model-based RL positions itself as a strong contender. Recent advances in sequence modelling have led to effective transformer-based world models, albeit at the price of heavy computations due to the long sequences of tokens required to accurately simulate environments. In this work, we propose $Delta$-IRIS, a new agent with a world model architecture composed of a discrete autoencoder that encodes stochastic deltas between time steps and an autoregressive transformer that predicts future deltas by summarizing the current state of the world with continuous tokens. In the Crafter benchmark, $Delta$-IRIS sets a new state of the art at multiple frame budgets, while being an order of magnitude faster to train than previous attention-based approaches. We release our code and models at https://github.com/vmicheli/delta-iris.
6/28/2024
Learning to Play Atari in a World of Tokens
Pranav Agarwal, Sheldon Andrews, Samira Ebrahimi Kahou
0
0
Model-based reinforcement learning agents utilizing transformers have shown improved sample efficiency due to their ability to model extended context, resulting in more accurate world models. However, for complex reasoning and planning tasks, these methods primarily rely on continuous representations. This complicates modeling of discrete properties of the real world such as disjoint object classes between which interpolation is not plausible. In this work, we introduce discrete abstract representations for transformer-based learning (DART), a sample-efficient method utilizing discrete representations for modeling both the world and learning behavior. We incorporate a transformer-decoder for auto-regressive world modeling and a transformer-encoder for learning behavior by attending to task-relevant cues in the discrete representation of the world model. For handling partial observability, we aggregate information from past time steps as memory tokens. DART outperforms previous state-of-the-art methods that do not use look-ahead search on the Atari 100k sample efficiency benchmark with a median human-normalized score of 0.790 and beats humans in 9 out of 26 games. We release our code at https://pranaval.github.io/DART/.
6/4/2024
👨🏫
Transformer-Aided Semantic Communications
Matin Mortaheb, Erciyes Karakaya, Mohammad A. Amir Khojastepour, Sennur Ulukus
0
0
The transformer structure employed in large language models (LLMs), as a specialized category of deep neural networks (DNNs) featuring attention mechanisms, stands out for their ability to identify and highlight the most relevant aspects of input data. Such a capability is particularly beneficial in addressing a variety of communication challenges, notably in the realm of semantic communication where proper encoding of the relevant data is critical especially in systems with limited bandwidth. In this work, we employ vision transformers specifically for the purpose of compression and compact representation of the input image, with the goal of preserving semantic information throughout the transmission process. Through the use of the attention mechanism inherent in transformers, we create an attention mask. This mask effectively prioritizes critical segments of images for transmission, ensuring that the reconstruction phase focuses on key objects highlighted by the mask. Our methodology significantly improves the quality of semantic communication and optimizes bandwidth usage by encoding different parts of the data in accordance with their semantic information content, thus enhancing overall efficiency. We evaluate the effectiveness of our proposed framework using the TinyImageNet dataset, focusing on both reconstruction quality and accuracy. Our evaluation results demonstrate that our framework successfully preserves semantic information, even when only a fraction of the encoded data is transmitted, according to the intended compression rates.
5/3/2024