Deciphering 'What' and 'Where' Visual Pathways from Spectral Clustering of Layer-Distributed Neural Representations

0

Sign in to get full access
Overview
- This paper investigates how neural networks process visual information, particularly the distinction between "what" (object recognition) and "where" (spatial location) pathways in the brain.
- The researchers used spectral clustering, a machine learning technique, to analyze the layer-distributed neural representations in a deep neural network trained on visual tasks.
- Their findings suggest that the neural network developed distinct "what" and "where" pathways, echoing the structure observed in the human visual system.
Plain English Explanation
The human visual system is known to have two main processing pathways: the "what" pathway, which helps us recognize objects, and the "where" pathway, which helps us understand the spatial location of things we see. This paper explores how deep neural networks, which are inspired by the human brain, develop similar "what" and "where" pathways when trained on visual tasks.
The researchers used a technique called "spectral clustering" to analyze how the neural network's internal representations were organized across different layers. Spectral clustering is a way of grouping similar things together by looking at the connections between them.
When they applied this to the neural network, they found that the representations naturally separated into two distinct clusters, one for "what" (object recognition) and one for "where" (spatial location). This suggests that the neural network had spontaneously developed its own version of the "what" and "where" pathways, just like the human visual system. This is an interesting finding that reveals how deep neural networks can mimic certain aspects of biological intelligence.
The researchers also found that these "what" and "where" pathways emerged gradually over the course of the neural network's training, with the "what" pathway developing first and the "where" pathway following later. This aligns with what we know about the human visual system, where the "what" and "where" pathways develop at different rates.
Overall, this study provides insights into how deep neural networks process visual information and how their internal structure can resemble the organization of the human visual system. These findings could have implications for understanding the nature of intelligence and for designing more human-like AI systems.
Technical Explanation
The researchers used a deep neural network trained on visual tasks, such as object recognition and spatial localization, to investigate the emergence of "what" and "where" pathways. They employed spectral clustering, a powerful machine learning technique, to analyze the layer-distributed neural representations within the network.
Spectral clustering works by identifying clusters of similar data points based on the connections between them. When applied to the neural network's internal representations, this method revealed the presence of two distinct clusters - one corresponding to the "what" pathway (object recognition) and the other to the "where" pathway (spatial localization).
Further analysis showed that these "what" and "where" pathways emerged gradually over the course of the neural network's training. The "what" pathway developed first, followed by the "where" pathway. This temporal pattern mirrors the development of the visual processing streams in the human brain, where the "what" and "where" pathways mature at different rates.
The researchers' findings suggest that deep neural networks can spontaneously develop neural representations that resemble the organizational structure of the human visual system, even when trained on generic visual tasks. This is a significant result, as it provides insights into the fundamental principles underlying the processing of visual information in both biological and artificial systems.
Critical Analysis
The paper provides a compelling demonstration of how deep neural networks can exhibit organizational structures that parallel the human visual system, but it is important to note that this is an observational study and does not establish a causal link between the network architecture and the emergent "what" and "where" pathways.
While the researchers' use of spectral clustering is a powerful analytical tool, it is possible that other techniques could reveal different perspectives on the network's internal representations. Additionally, the specific network architecture and training regime used in this study may have influenced the observed patterns, and it remains to be seen whether similar findings would emerge in other neural network models or task domains.
Furthermore, the paper does not delve into the functional significance of the "what" and "where" pathways within the context of the neural network's overall performance. It would be valuable to understand how these pathways contribute to the network's ability to recognize objects and locate them in space, and whether they confer any advantages or disadvantages compared to alternative approaches.
Conclusion
This study provides intriguing evidence that deep neural networks can spontaneously develop internal representations that resemble the "what" and "where" pathways observed in the human visual system, even when trained on generic visual tasks. These findings suggest that the principles underlying biological and artificial intelligence may share common organizational structures, and could have implications for understanding the nature of intelligence and for designing more human-like AI systems.
While further research is needed to fully understand the significance and generalizability of these results, this paper represents an important step in bridging the gap between our understanding of biological and artificial visual processing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Deciphering 'What' and 'Where' Visual Pathways from Spectral Clustering of Layer-Distributed Neural Representations
Xiao Zhang, David Yunis, Michael Maire
We present an approach for analyzing grouping information contained within a neural network's activations, permitting extraction of spatial layout and semantic segmentation from the behavior of large pre-trained vision models. Unlike prior work, our method conducts a holistic analysis of a network's activation state, leveraging features from all layers and obviating the need to guess which part of the model contains relevant information. Motivated by classic spectral clustering, we formulate this analysis in terms of an optimization objective involving a set of affinity matrices, each formed by comparing features within a different layer. Solving this optimization problem using gradient descent allows our technique to scale from single images to dataset-level analysis, including, in the latter, both intra- and inter-image relationships. Analyzing a pre-trained generative transformer provides insight into the computational strategy learned by such models. Equating affinity with key-query similarity across attention layers yields eigenvectors encoding scene spatial layout, whereas defining affinity by value vector similarity yields eigenvectors encoding object identity. This result suggests that key and query vectors coordinate attentional information flow according to spatial proximity (a `where' pathway), while value vectors refine a semantic category representation (a `what' pathway).
Read more6/21/2024
✨
0
Feature Accentuation: Revealing 'What' Features Respond to in Natural Images
Chris Hamblin, Thomas Fel, Srijani Saha, Talia Konkle, George Alvarez
Efforts to decode neural network vision models necessitate a comprehensive grasp of both the spatial and semantic facets governing feature responses within images. Most research has primarily centered around attribution methods, which provide explanations in the form of heatmaps, showing where the model directs its attention for a given feature. However, grasping 'where' alone falls short, as numerous studies have highlighted the limitations of those methods and the necessity to understand 'what' the model has recognized at the focal point of its attention. In parallel, 'Feature visualization' offers another avenue for interpreting neural network features. This approach synthesizes an optimal image through gradient ascent, providing clearer insights into 'what' features respond to. However, feature visualizations only provide one global explanation per feature; they do not explain why features activate for particular images. In this work, we introduce a new method to the interpretability tool-kit, 'feature accentuation', which is capable of conveying both where and what in arbitrary input images induces a feature's response. At its core, feature accentuation is image-seeded (rather than noise-seeded) feature visualization. We find a particular combination of parameterization, augmentation, and regularization yields naturalistic visualizations that resemble the seed image and target feature simultaneously. Furthermore, we validate these accentuations are processed along a natural circuit by the model. We make our precise implementation of feature accentuation available to the community as the Faccent library, an extension of Lucent.
Read more6/11/2024
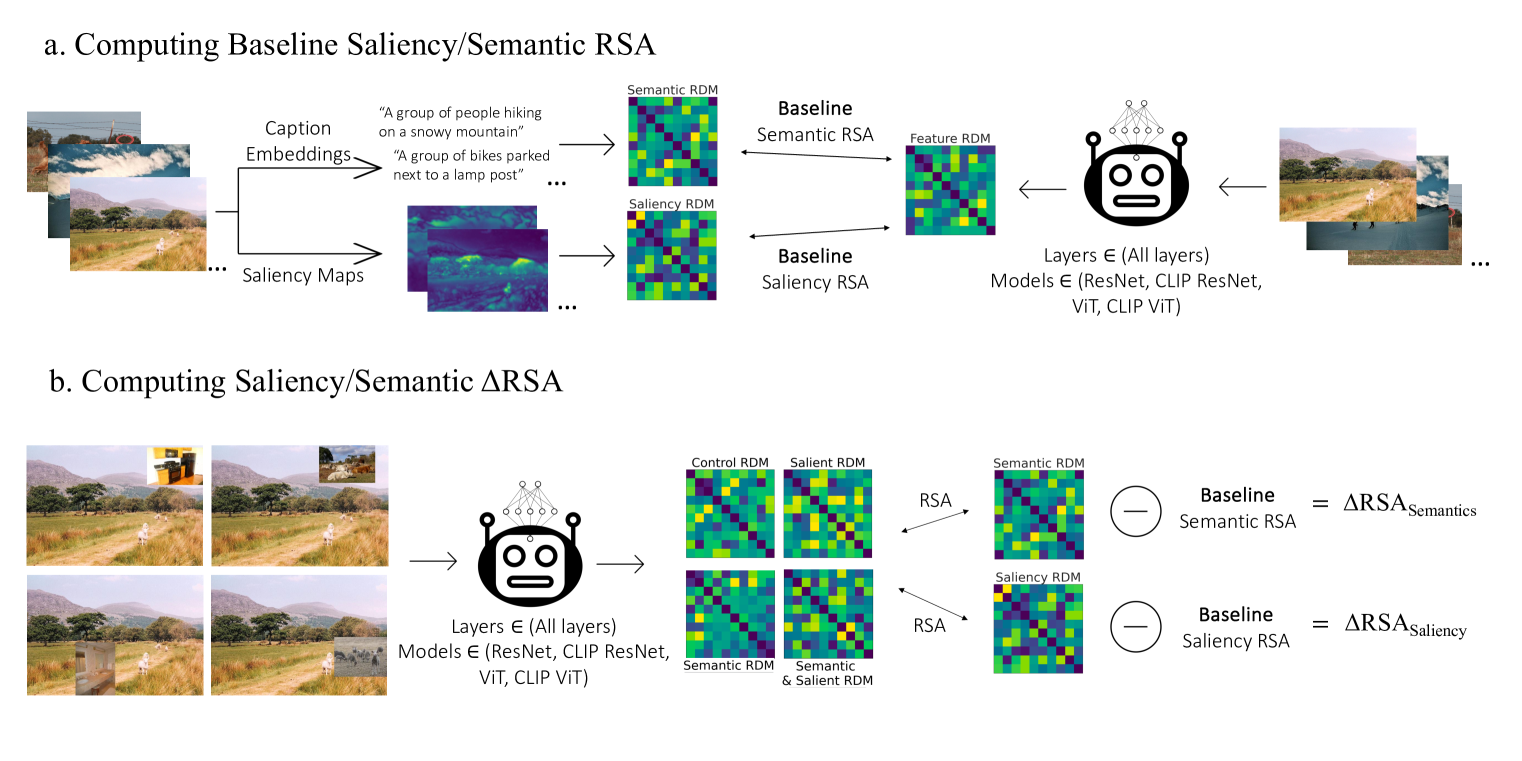
0
Saliency Suppressed, Semantics Surfaced: Visual Transformations in Neural Networks and the Brain
Gustaw Opie{l}ka, Jessica Loke, Steven Scholte
Deep learning algorithms lack human-interpretable accounts of how they transform raw visual input into a robust semantic understanding, which impedes comparisons between different architectures, training objectives, and the human brain. In this work, we take inspiration from neuroscience and employ representational approaches to shed light on how neural networks encode information at low (visual saliency) and high (semantic similarity) levels of abstraction. Moreover, we introduce a custom image dataset where we systematically manipulate salient and semantic information. We find that ResNets are more sensitive to saliency information than ViTs, when trained with object classification objectives. We uncover that networks suppress saliency in early layers, a process enhanced by natural language supervision (CLIP) in ResNets. CLIP also enhances semantic encoding in both architectures. Finally, we show that semantic encoding is a key factor in aligning AI with human visual perception, while saliency suppression is a non-brain-like strategy.
Read more4/30/2024

0
Parallel Backpropagation for Shared-Feature Visualization
Alexander Lappe, Anna Bogn'ar, Ghazaleh Ghamkhari Nejad, Albert Mukovskiy, Lucas Martini, Martin A. Giese, Rufin Vogels
High-level visual brain regions contain subareas in which neurons appear to respond more strongly to examples of a particular semantic category, like faces or bodies, rather than objects. However, recent work has shown that while this finding holds on average, some out-of-category stimuli also activate neurons in these regions. This may be due to visual features common among the preferred class also being present in other images. Here, we propose a deep-learning-based approach for visualizing these features. For each neuron, we identify relevant visual features driving its selectivity by modelling responses to images based on latent activations of a deep neural network. Given an out-of-category image which strongly activates the neuron, our method first identifies a reference image from the preferred category yielding a similar feature activation pattern. We then backpropagate latent activations of both images to the pixel level, while enhancing the identified shared dimensions and attenuating non-shared features. The procedure highlights image regions containing shared features driving responses of the model neuron. We apply the algorithm to novel recordings from body-selective regions in macaque IT cortex in order to understand why some images of objects excite these neurons. Visualizations reveal object parts which resemble parts of a macaque body, shedding light on neural preference of these objects.
Read more5/17/2024