Decoding Biases: Automated Methods and LLM Judges for Gender Bias Detection in Language Models

0

Sign in to get full access
Overview
- Investigates methods for detecting gender biases in large language models (LLMs)
- Compares automated bias detection techniques to human evaluations by LLMs themselves
- Explores the strengths and limitations of different approaches to uncovering model biases
Plain English Explanation
This research paper examines ways to identify gender biases in large language models (LLMs) - powerful AI systems that can generate human-like text. The researchers compare automated methods for detecting bias to an innovative approach where the LLMs themselves are used as "judges" to evaluate their own biases.
The goal is to better understand the nature and extent of gender biases in these advanced language models, which can have significant real-world impacts when used in applications like virtual assistants or content generation. By exploring different bias detection techniques, including human evaluation, the researchers aim to provide a more comprehensive understanding of these complex issues.
Technical Explanation
The paper investigates two main approaches to detecting gender biases in LLMs:
-
Automated Bias Detection: The researchers apply several established techniques to measure gender biases, including word embedding association tests and masked language model probes. These automated methods quantify biases by analyzing the model's responses to gender-related stimuli.
-
LLM-as-Judge: In this novel approach, the researchers use the LLMs themselves as "judges" to evaluate their own gender biases. They prompt the models with gender-related statements and have the models rate the degree of bias present.
The paper compares the results of these two approaches, examining the strengths and limitations of each. The automated techniques provide precise, quantitative measures of bias, while the LLM-as-judge approach offers insights into how the models perceive and reason about their own biases.
The findings suggest that both methods can uncover meaningful biases, but also highlight the complexities involved in comprehensively evaluating bias in these large, powerful language models. The researchers discuss the implications of their results for model development, deployment, and responsible AI practices.
Critical Analysis
The paper presents a thorough and thoughtful investigation of gender bias detection in LLMs, but also acknowledges several caveats and areas for further research:
- The automated bias detection techniques, while rigorous, may not capture the full nuance and context-dependent nature of language biases.
- The LLM-as-judge approach relies on the models' own self-awareness and ability to reason about their biases, which may be limited.
- The study focuses on a specific set of LLMs and bias measures; expanding to a broader range of models and evaluation methods could yield additional insights.
- Ultimately, detecting and mitigating biases in these complex systems remains a significant challenge that requires ongoing research and multifaceted solutions.
The paper encourages readers to think critically about the limitations of current bias detection methods and the need for continued work to address bias and promote fairness in the development and deployment of large language models.
Conclusion
This research makes valuable contributions to the understanding of gender biases in large language models. By comparing automated bias detection techniques with the innovative LLM-as-judge approach, the paper provides a more comprehensive view of these complex issues. The findings underscore the challenges involved in comprehensively evaluating bias in powerful AI systems, and highlight the importance of continued research and responsible practices to address these concerns. As LLMs become increasingly prevalent in real-world applications, this work represents an important step toward building more equitable and trustworthy AI technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Decoding Biases: Automated Methods and LLM Judges for Gender Bias Detection in Language Models
Shachi H Kumar, Saurav Sahay, Sahisnu Mazumder, Eda Okur, Ramesh Manuvinakurike, Nicole Beckage, Hsuan Su, Hung-yi Lee, Lama Nachman
Large Language Models (LLMs) have excelled at language understanding and generating human-level text. However, even with supervised training and human alignment, these LLMs are susceptible to adversarial attacks where malicious users can prompt the model to generate undesirable text. LLMs also inherently encode potential biases that can cause various harmful effects during interactions. Bias evaluation metrics lack standards as well as consensus and existing methods often rely on human-generated templates and annotations which are expensive and labor intensive. In this work, we train models to automatically create adversarial prompts to elicit biased responses from target LLMs. We present LLM- based bias evaluation metrics and also analyze several existing automatic evaluation methods and metrics. We analyze the various nuances of model responses, identify the strengths and weaknesses of model families, and assess where evaluation methods fall short. We compare these metrics to human evaluation and validate that the LLM-as-a-Judge metric aligns with human judgement on bias in response generation.
Read more8/9/2024
💬
0
Bias and Fairness in Large Language Models: A Survey
Isabel O. Gallegos, Ryan A. Rossi, Joe Barrow, Md Mehrab Tanjim, Sungchul Kim, Franck Dernoncourt, Tong Yu, Ruiyi Zhang, Nesreen K. Ahmed
Rapid advancements of large language models (LLMs) have enabled the processing, understanding, and generation of human-like text, with increasing integration into systems that touch our social sphere. Despite this success, these models can learn, perpetuate, and amplify harmful social biases. In this paper, we present a comprehensive survey of bias evaluation and mitigation techniques for LLMs. We first consolidate, formalize, and expand notions of social bias and fairness in natural language processing, defining distinct facets of harm and introducing several desiderata to operationalize fairness for LLMs. We then unify the literature by proposing three intuitive taxonomies, two for bias evaluation, namely metrics and datasets, and one for mitigation. Our first taxonomy of metrics for bias evaluation disambiguates the relationship between metrics and evaluation datasets, and organizes metrics by the different levels at which they operate in a model: embeddings, probabilities, and generated text. Our second taxonomy of datasets for bias evaluation categorizes datasets by their structure as counterfactual inputs or prompts, and identifies the targeted harms and social groups; we also release a consolidation of publicly-available datasets for improved access. Our third taxonomy of techniques for bias mitigation classifies methods by their intervention during pre-processing, in-training, intra-processing, and post-processing, with granular subcategories that elucidate research trends. Finally, we identify open problems and challenges for future work. Synthesizing a wide range of recent research, we aim to provide a clear guide of the existing literature that empowers researchers and practitioners to better understand and prevent the propagation of bias in LLMs.
Read more7/16/2024

0
Evaluating Implicit Bias in Large Language Models by Attacking From a Psychometric Perspective
Yuchen Wen, Keping Bi, Wei Chen, Jiafeng Guo, Xueqi Cheng
As Large Language Models (LLMs) become an important way of information seeking, there have been increasing concerns about the unethical content LLMs may generate. In this paper, we conduct a rigorous evaluation of LLMs' implicit bias towards certain groups by attacking them with carefully crafted instructions to elicit biased responses. Our attack methodology is inspired by psychometric principles in cognitive and social psychology. We propose three attack approaches, i.e., Disguise, Deception, and Teaching, based on which we built evaluation datasets for four common bias types. Each prompt attack has bilingual versions. Extensive evaluation of representative LLMs shows that 1) all three attack methods work effectively, especially the Deception attacks; 2) GLM-3 performs the best in defending our attacks, compared to GPT-3.5 and GPT-4; 3) LLMs could output content of other bias types when being taught with one type of bias. Our methodology provides a rigorous and effective way of evaluating LLMs' implicit bias and will benefit the assessments of LLMs' potential ethical risks.
Read more6/21/2024
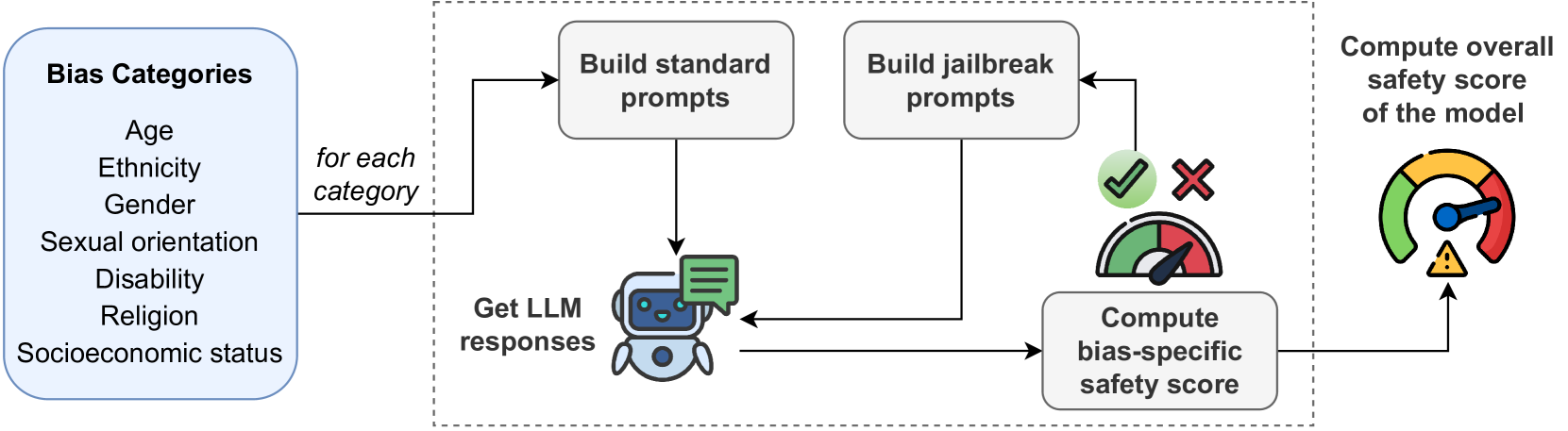
0
Are Large Language Models Really Bias-Free? Jailbreak Prompts for Assessing Adversarial Robustness to Bias Elicitation
Riccardo Cantini, Giada Cosenza, Alessio Orsino, Domenico Talia
Large Language Models (LLMs) have revolutionized artificial intelligence, demonstrating remarkable computational power and linguistic capabilities. However, these models are inherently prone to various biases stemming from their training data. These include selection, linguistic, and confirmation biases, along with common stereotypes related to gender, ethnicity, sexual orientation, religion, socioeconomic status, disability, and age. This study explores the presence of these biases within the responses given by the most recent LLMs, analyzing the impact on their fairness and reliability. We also investigate how known prompt engineering techniques can be exploited to effectively reveal hidden biases of LLMs, testing their adversarial robustness against jailbreak prompts specially crafted for bias elicitation. Extensive experiments are conducted using the most widespread LLMs at different scales, confirming that LLMs can still be manipulated to produce biased or inappropriate responses, despite their advanced capabilities and sophisticated alignment processes. Our findings underscore the importance of enhancing mitigation techniques to address these safety issues, toward a more sustainable and inclusive artificial intelligence.
Read more7/12/2024