LLM-based Hierarchical Concept Decomposition for Interpretable Fine-Grained Image Classification

0

Sign in to get full access
Overview
- This paper presents a hierarchical concept decomposition approach using large language models (LLMs) for fine-grained image classification.
- The method aims to improve the interpretability of image classification models by breaking down the classification process into a hierarchy of learned concepts.
- The authors demonstrate the effectiveness of their approach on several fine-grained image datasets, showing improvements in both classification accuracy and interpretability.
Plain English Explanation
When we look at an image, we can often identify and understand the individual elements or concepts that make up the overall scene. For example, in a picture of a dog, we might recognize the dog's head, body, legs, and tail as distinct concepts. This ability to decompose an image into its underlying components is an essential part of how humans perceive and make sense of visual information.
However, many modern image classification models, while highly accurate, operate as "black boxes" - they can predict the correct label for an image, but they don't provide any insight into the specific visual features or concepts that led to that prediction. This lack of interpretability can make it difficult to understand how these models work and to trust their decisions, especially in critical applications.
The researchers in this paper propose a new approach to address this challenge. They develop a hierarchical concept decomposition model that uses large language models (LLMs) - powerful AI systems trained on vast amounts of text data - to learn a hierarchy of visual concepts. This hierarchy can then be used to break down the classification process for a given image, providing a more interpretable and explainable way of arriving at the final prediction.
By linking the visual features of an image to a structured set of learned concepts, the researchers hope to make image classification models more transparent and trustworthy, while also potentially improving their overall performance on fine-grained tasks. This work builds on recent advancements in using LLMs for visual understanding, as well as prior research on using LLMs to induce and reason about conceptual knowledge.
Technical Explanation
The core of the researchers' approach is a hierarchical concept decomposition model that leverages the power of large language models (LLMs) to learn a structured hierarchy of visual concepts. This hierarchy is then used to guide the image classification process, providing a more interpretable and explainable pathway to the final prediction.
The model is trained in two stages. First, the researchers use an LLM-based concept induction process to learn a set of visual concepts and their relationships, forming a hierarchical concept tree. This concept tree is then used to guide the second stage of the model, where a convolutional neural network (CNN) is trained to classify images by mapping them to the relevant concepts in the hierarchy.
The hierarchical concept decomposition approach has several key advantages over traditional "black box" image classification models. By explicitly modeling the underlying visual concepts, the researchers are able to enhance the fine-grained classification performance of their model, as well as provide detailed explanations for its predictions. Additionally, the hierarchical structure of the concepts allows the model to reason about images at multiple levels of abstraction, similar to how humans perceive and understand visual information.
The researchers evaluate their approach on several fine-grained image classification datasets, demonstrating its effectiveness in both improving classification accuracy and providing interpretable explanations for the model's predictions. They also conduct user studies to assess the model's ability to enhance human understanding and trust in the image classification process.
Critical Analysis
While the hierarchical concept decomposition approach presented in this paper represents an interesting and promising step towards more interpretable image classification, there are a few potential limitations and areas for future research:
-
Scalability and Generalization: The current implementation relies on an LLM-based concept induction process, which may become computationally expensive and difficult to scale as the number of visual concepts grows. Exploring more efficient or automated ways of constructing the concept hierarchy could help improve the model's scalability and generalizability to a wider range of visual domains.
-
Robustness and Reliability: The researchers primarily evaluate their model on standard fine-grained image classification benchmarks, but it's unclear how it would perform in more challenging or adversarial settings. Assessing the model's robustness to noise, occlusions, or other real-world variations would be an important next step in validating its practical utility.
-
Human-AI Collaboration: While the paper emphasizes the model's ability to enhance human understanding and trust, it does not delve deeply into the specific mechanisms or user interfaces that could facilitate effective human-AI collaboration. Further research exploring how to best integrate this type of interpretable model into real-world decision-making workflows would be valuable.
-
Broader Societal Implications: As with any advanced AI system, it's important to carefully consider the potential societal implications of deploying a hierarchical concept decomposition model, particularly in sensitive domains such as medical diagnosis or criminal justice. Proactive steps to ensure the fairness, accountability, and transparency of these systems will be crucial.
Overall, the work presented in this paper represents an important step towards more interpretable and trustworthy image classification models. By leveraging the conceptual knowledge encoded in large language models, the researchers have developed a novel approach that could have significant implications for a wide range of visual AI applications.
Conclusion
This paper introduces a hierarchical concept decomposition approach that uses large language models to improve the interpretability of fine-grained image classification. By learning a structured hierarchy of visual concepts and then using this hierarchy to guide the classification process, the researchers have developed a more explainable and trustworthy model compared to traditional "black box" image classifiers.
The key innovation of this work is the integration of LLM-based concept induction and hierarchical reasoning to bridge the gap between the high-level conceptual understanding of humans and the low-level visual features recognized by machine learning models. This allows the model to provide detailed explanations for its predictions, while also potentially enhancing its overall classification performance on fine-grained tasks.
As AI systems become increasingly prevalent in real-world decision-making, the ability to understand and trust the reasoning behind these systems will be crucial. The hierarchical concept decomposition approach presented in this paper represents an important step towards this goal, with the potential to significantly impact a wide range of visual AI applications, from medical diagnosis to autonomous driving.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
LLM-based Hierarchical Concept Decomposition for Interpretable Fine-Grained Image Classification
Renyi Qu, Mark Yatskar
(Renyi Qu's Master's Thesis) Recent advancements in interpretable models for vision-language tasks have achieved competitive performance; however, their interpretability often suffers due to the reliance on unstructured text outputs from large language models (LLMs). This introduces randomness and compromises both transparency and reliability, which are essential for addressing safety issues in AI systems. We introduce texttt{Hi-CoDe} (Hierarchical Concept Decomposition), a novel framework designed to enhance model interpretability through structured concept analysis. Our approach consists of two main components: (1) We use GPT-4 to decompose an input image into a structured hierarchy of visual concepts, thereby forming a visual concept tree. (2) We then employ an ensemble of simple linear classifiers that operate on concept-specific features derived from CLIP to perform classification. Our approach not only aligns with the performance of state-of-the-art models but also advances transparency by providing clear insights into the decision-making process and highlighting the importance of various concepts. This allows for a detailed analysis of potential failure modes and improves model compactness, therefore setting a new benchmark in interpretability without compromising the accuracy.
Read more6/4/2024

0
Image-Text Co-Decomposition for Text-Supervised Semantic Segmentation
Ji-Jia Wu, Andy Chia-Hao Chang, Chieh-Yu Chuang, Chun-Pei Chen, Yu-Lun Liu, Min-Hung Chen, Hou-Ning Hu, Yung-Yu Chuang, Yen-Yu Lin
This paper addresses text-supervised semantic segmentation, aiming to learn a model capable of segmenting arbitrary visual concepts within images by using only image-text pairs without dense annotations. Existing methods have demonstrated that contrastive learning on image-text pairs effectively aligns visual segments with the meanings of texts. We notice that there is a discrepancy between text alignment and semantic segmentation: A text often consists of multiple semantic concepts, whereas semantic segmentation strives to create semantically homogeneous segments. To address this issue, we propose a novel framework, Image-Text Co-Decomposition (CoDe), where the paired image and text are jointly decomposed into a set of image regions and a set of word segments, respectively, and contrastive learning is developed to enforce region-word alignment. To work with a vision-language model, we present a prompt learning mechanism that derives an extra representation to highlight an image segment or a word segment of interest, with which more effective features can be extracted from that segment. Comprehensive experimental results demonstrate that our method performs favorably against existing text-supervised semantic segmentation methods on six benchmark datasets.
Read more4/8/2024
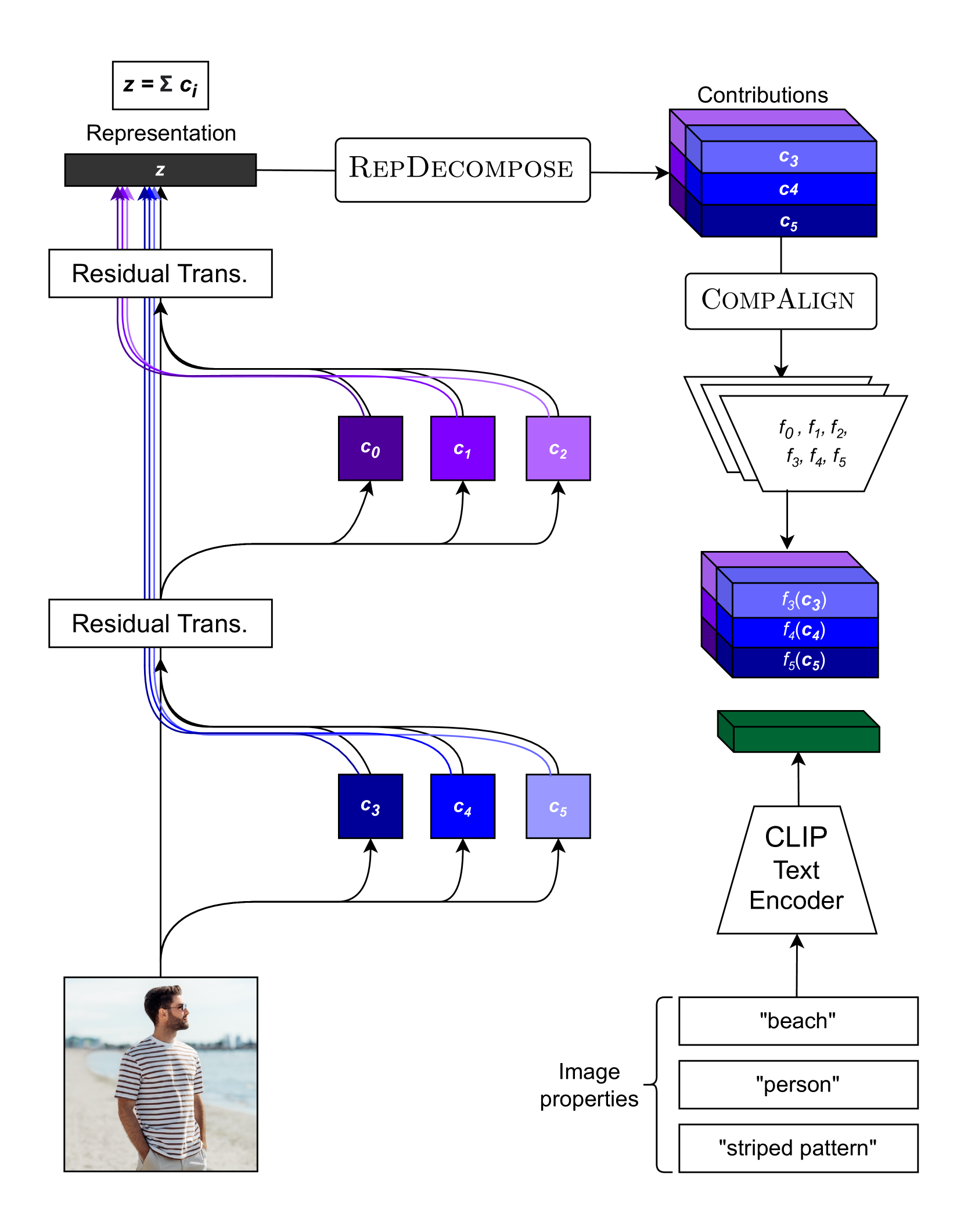
0
Decomposing and Interpreting Image Representations via Text in ViTs Beyond CLIP
Sriram Balasubramanian, Samyadeep Basu, Soheil Feizi
Recent works have explored how individual components of the CLIP-ViT model contribute to the final representation by leveraging the shared image-text representation space of CLIP. These components, such as attention heads and MLPs, have been shown to capture distinct image features like shape, color or texture. However, understanding the role of these components in arbitrary vision transformers (ViTs) is challenging. To this end, we introduce a general framework which can identify the roles of various components in ViTs beyond CLIP. Specifically, we (a) automate the decomposition of the final representation into contributions from different model components, and (b) linearly map these contributions to CLIP space to interpret them via text. Additionally, we introduce a novel scoring function to rank components by their importance with respect to specific features. Applying our framework to various ViT variants (e.g. DeiT, DINO, DINOv2, Swin, MaxViT), we gain insights into the roles of different components concerning particular image features.These insights facilitate applications such as image retrieval using text descriptions or reference images, visualizing token importance heatmaps, and mitigating spurious correlations.
Read more6/4/2024

0
Self-supervised Interpretable Concept-based Models for Text Classification
Francesco De Santis, Philippe Bich, Gabriele Ciravegna, Pietro Barbiero, Danilo Giordano, Tania Cerquitelli
Despite their success, Large-Language Models (LLMs) still face criticism as their lack of interpretability limits their controllability and reliability. Traditional post-hoc interpretation methods, based on attention and gradient-based analysis, offer limited insight into the model's decision-making processes. In the image field, Concept-based models have emerged as explainable-by-design architectures, employing human-interpretable features as intermediate representations. However, these methods have not been yet adapted to textual data, mainly because they require expensive concept annotations, which are impractical for real-world text data. This paper addresses this challenge by proposing a self-supervised Interpretable Concept Embedding Models (ICEMs). We leverage the generalization abilities of LLMs to predict the concepts labels in a self-supervised way, while we deliver the final predictions with an interpretable function. The results of our experiments show that ICEMs can be trained in a self-supervised way achieving similar performance to fully supervised concept-based models and end-to-end black-box ones. Additionally, we show that our models are (i) interpretable, offering meaningful logical explanations for their predictions; (ii) interactable, allowing humans to modify intermediate predictions through concept interventions; and (iii) controllable, guiding the LLMs' decoding process to follow a required decision-making path.
Read more6/21/2024