Decomposing Label Space, Format and Discrimination: Rethinking How LLMs Respond and Solve Tasks via In-Context Learning
2404.07546
0
0
🤖
Abstract
In-context Learning (ICL) has emerged as a powerful capability alongside the development of scaled-up large language models (LLMs). By instructing LLMs using few-shot demonstrative examples, ICL enables them to perform a wide range of tasks without updating millions of parameters. However, the precise contributions of demonstrations towards improving end-task performance have not been thoroughly investigated in recent analytical studies. In this paper, we empirically decompose the overall performance of ICL into three dimensions, label space, format, and discrimination, and we evaluate four general-purpose LLMs across a diverse range of tasks. Counter-intuitively, we find that the demonstrations have a marginal impact on provoking discriminative knowledge of language models. However, ICL exhibits significant efficacy in regulating the label space and format which helps LLMs to respond in desired label words. We then demonstrate this ability functions similar to detailed instructions for LLMs to follow. We additionally provide an in-depth analysis of the mechanism of retrieval helping with ICL and find that retrieving the most semantically similar examples notably boosts model's discriminative capability.
Create account to get full access
Overview
- In-context Learning (ICL) allows large language models (LLMs) to perform a wide range of tasks without updating millions of parameters, by using few-shot demonstrative examples.
- This paper aims to empirically decompose the overall performance of ICL into three dimensions: label space, format, and discrimination.
- The paper evaluates four general-purpose LLMs across a diverse range of tasks and finds that demonstrations have a marginal impact on provoking discriminative knowledge in language models.
- However, ICL is shown to be effective in regulating the label space and format, helping LLMs respond with desired label words, similar to detailed instructions.
- The paper also analyzes the mechanism of retrieval in ICL, finding that retrieving the most semantically similar examples boosts the model's discriminative capability.
Plain English Explanation
In-context Learning (ICL) is a powerful capability that allows large language models (LLMs) to perform a wide range of tasks without having to update millions of parameters. This is done by providing the LLM with a few examples that demonstrate how to complete a specific task. [https://aimodels.fyi/papers/arxiv/take-one-step-at-time-to-know]
However, the precise ways in which these demonstrations improve the LLM's performance on the end task have not been thoroughly investigated. This paper aims to break down the overall performance of ICL into three key aspects: the label space (the set of possible output labels), the format of the outputs, and the model's ability to discriminate between different options (its "discriminative knowledge").
The researchers evaluated four different LLMs on a variety of tasks and found some surprising results. Contrary to what one might expect, the demonstrations had only a marginal impact on the models' discriminative knowledge. [https://aimodels.fyi/papers/arxiv/context-learning-generalizes-but-not-always-robustly]
However, ICL was very effective at helping the LLMs regulate the label space and output format, allowing them to respond with the desired words or format. This suggests that ICL functions a bit like detailed instructions for the LLM to follow, rather than primarily improving its underlying understanding.
The paper also examines the role of retrieval in ICL, finding that retrieving the most semantically similar examples can significantly boost the model's discriminative capability. [https://aimodels.fyi/papers/arxiv/rectifying-demonstration-shortcut-context-learning]
Technical Explanation
This paper empirically decomposes the overall performance of In-context Learning (ICL) into three key dimensions: label space, format, and discrimination.
The researchers evaluate four general-purpose large language models (LLMs) on a diverse set of tasks, using few-shot demonstrations to enable the models to perform these tasks. They find that, counter-intuitively, the demonstrations have only a marginal impact on provoking discriminative knowledge in the language models. [https://aimodels.fyi/papers/arxiv/supervised-knowledge-makes-large-language-models-better]
However, the paper demonstrates that ICL is highly effective at regulating the label space and format of the model's outputs, helping the LLMs respond with the desired label words. This suggests that ICL functions more like detailed instructions for the model to follow, rather than primarily improving its underlying understanding.
The authors also provide an in-depth analysis of the retrieval mechanism underlying ICL. They find that retrieving the most semantically similar demonstration examples can notably boost the model's discriminative capability. [https://aimodels.fyi/papers/arxiv/how-does-multi-task-training-affect-transformer]
Critical Analysis
The paper provides valuable insights into the specific mechanisms by which In-context Learning (ICL) can improve the performance of large language models (LLMs) on a wide range of tasks. The finding that demonstrations have a marginal impact on the models' discriminative knowledge is particularly counterintuitive and worth further investigation.
One potential limitation of the study is the specific set of tasks and LLMs evaluated. It would be interesting to see if the same patterns hold across an even broader range of tasks and model architectures. Additionally, the paper does not delve into the potential reasons why demonstrations have a limited impact on discriminative knowledge, which could be an area for future research.
The analysis of the retrieval mechanism is a strength of the paper, as it provides a potential avenue for further improving the effectiveness of ICL. However, the authors do not explore how the retrieved examples could be optimized or selected to maximize the boost in discriminative capability.
Overall, this paper makes an important contribution to our understanding of how ICL works and the specific ways in which it can enhance LLM performance. The findings challenge some common assumptions and point to areas for further exploration that could lead to even more powerful and effective language models.
Conclusion
This paper provides a detailed empirical investigation into the mechanisms underlying In-context Learning (ICL) and its impact on the performance of large language models (LLMs). The key findings are:
- Demonstrations have a marginal impact on provoking discriminative knowledge in LLMs, counter to expectations.
- However, ICL is highly effective at regulating the label space and output format, helping LLMs respond with desired label words.
- Retrieving the most semantically similar demonstration examples can notably boost the model's discriminative capability.
These insights challenge some common assumptions about ICL and point to new directions for further research and development of even more powerful language models. By understanding the specific ways in which ICL works, researchers and practitioners can work to optimize and enhance this important capability.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Unifying Demonstration Selection and Compression for In-Context Learning
Jun Gao, Ziqiang Cao, Wenjie Li
0
0
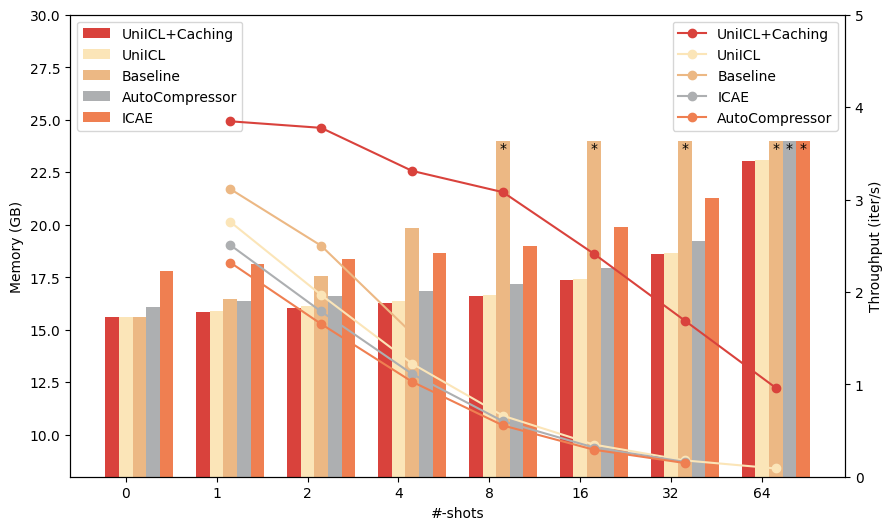
In-context learning (ICL) facilitates large language models (LLMs) exhibiting spectacular emergent capabilities in various scenarios. Unfortunately, introducing demonstrations easily makes the prompt length explode, bringing a significant burden to hardware. In addition, random demonstrations usually achieve limited improvements in ICL, necessitating demonstration selection among accessible candidates. Previous studies introduce extra modules to perform demonstration compression or selection independently. In this paper, we propose an ICL framework UniICL, which Unifies demonstration selection and compression, and final response generation via a single frozen LLM. Specifically, UniICL first projects actual demonstrations and inference text inputs into short virtual tokens, respectively. Then, virtual tokens are applied to select suitable demonstrations by measuring semantic similarity within latent space among candidate demonstrations and inference input. Finally, inference text inputs together with selected virtual demonstrations are fed into the same frozen LLM for response generation. Notably, UniICL is a parameter-efficient framework that only contains 17M trainable parameters originating from the projection layer. We conduct experiments and analysis over in- and out-domain datasets of both generative and understanding tasks, encompassing ICL scenarios with plentiful and limited demonstration candidates. Results show that UniICL effectively unifies $12 times$ compression, demonstration selection, and response generation, efficiently scaling up the baseline from 4-shot to 64-shot ICL in IMDb with 24 GB CUDA allocation
6/18/2024

Towards Understanding In-Context Learning with Contrastive Demonstrations and Saliency Maps
Fuxiao Liu, Paiheng Xu, Zongxia Li, Yue Feng, Hyemi Song
0
0
We investigate the role of various demonstration components in the in-context learning (ICL) performance of large language models (LLMs). Specifically, we explore the impacts of ground-truth labels, input distribution, and complementary explanations, particularly when these are altered or perturbed. We build on previous work, which offers mixed findings on how these elements influence ICL. To probe these questions, we employ explainable NLP (XNLP) methods and utilize saliency maps of contrastive demonstrations for both qualitative and quantitative analysis. Our findings reveal that flipping ground-truth labels significantly affects the saliency, though it's more noticeable in larger LLMs. Our analysis of the input distribution at a granular level reveals that changing sentiment-indicative terms in a sentiment analysis task to neutral ones does not have as substantial an impact as altering ground-truth labels. Finally, we find that the effectiveness of complementary explanations in boosting ICL performance is task-dependent, with limited benefits seen in sentiment analysis tasks compared to symbolic reasoning tasks. These insights are critical for understanding the functionality of LLMs and guiding the development of effective demonstrations, which is increasingly relevant in light of the growing use of LLMs in applications such as ChatGPT. Our research code is publicly available at https://github.com/paihengxu/XICL.
4/29/2024
🌿
A Survey on In-context Learning
Qingxiu Dong, Lei Li, Damai Dai, Ce Zheng, Jingyuan Ma, Rui Li, Heming Xia, Jingjing Xu, Zhiyong Wu, Baobao Chang, Xu Sun, Lei Li, Zhifang Sui
0
0
With the increasing capabilities of large language models (LLMs), in-context learning (ICL) has emerged as a new paradigm for natural language processing (NLP), where LLMs make predictions based on contexts augmented with a few examples. It has been a significant trend to explore ICL to evaluate and extrapolate the ability of LLMs. In this paper, we aim to survey and summarize the progress and challenges of ICL. We first present a formal definition of ICL and clarify its correlation to related studies. Then, we organize and discuss advanced techniques, including training strategies, prompt designing strategies, and related analysis. Additionally, we explore various ICL application scenarios, such as data engineering and knowledge updating. Finally, we address the challenges of ICL and suggest potential directions for further research. We hope that our work can encourage more research on uncovering how ICL works and improving ICL.
6/19/2024
💬
What Do Language Models Learn in Context? The Structured Task Hypothesis
Jiaoda Li, Yifan Hou, Mrinmaya Sachan, Ryan Cotterell
0
0
Large language models (LLMs) exhibit an intriguing ability to learn a novel task from in-context examples presented in a demonstration, termed in-context learning (ICL). Understandably, a swath of research has been dedicated to uncovering the theories underpinning ICL. One popular hypothesis explains ICL by task selection. LLMs identify the task based on the demonstration and generalize it to the prompt. Another popular hypothesis is that ICL is a form of meta-learning, i.e., the models learn a learning algorithm at pre-training time and apply it to the demonstration. Finally, a third hypothesis argues that LLMs use the demonstration to select a composition of tasks learned during pre-training to perform ICL. In this paper, we empirically explore these three hypotheses that explain LLMs' ability to learn in context with a suite of experiments derived from common text classification tasks. We invalidate the first two hypotheses with counterexamples and provide evidence in support of the last hypothesis. Our results suggest an LLM could learn a novel task in context via composing tasks learned during pre-training.
6/11/2024