Towards Understanding In-Context Learning with Contrastive Demonstrations and Saliency Maps
2307.05052
0
0

Abstract
We investigate the role of various demonstration components in the in-context learning (ICL) performance of large language models (LLMs). Specifically, we explore the impacts of ground-truth labels, input distribution, and complementary explanations, particularly when these are altered or perturbed. We build on previous work, which offers mixed findings on how these elements influence ICL. To probe these questions, we employ explainable NLP (XNLP) methods and utilize saliency maps of contrastive demonstrations for both qualitative and quantitative analysis. Our findings reveal that flipping ground-truth labels significantly affects the saliency, though it's more noticeable in larger LLMs. Our analysis of the input distribution at a granular level reveals that changing sentiment-indicative terms in a sentiment analysis task to neutral ones does not have as substantial an impact as altering ground-truth labels. Finally, we find that the effectiveness of complementary explanations in boosting ICL performance is task-dependent, with limited benefits seen in sentiment analysis tasks compared to symbolic reasoning tasks. These insights are critical for understanding the functionality of LLMs and guiding the development of effective demonstrations, which is increasingly relevant in light of the growing use of LLMs in applications such as ChatGPT. Our research code is publicly available at https://github.com/paihengxu/XICL.
Create account to get full access
Overview
- This paper explores a technique called "in-context learning" where language models learn new tasks by observing a few example demonstrations.
- The researchers use "contrastive demonstrations" - showing both good and bad examples - to help the model better understand the task.
- They also use "saliency maps" to visualize which parts of the input the model is focusing on when making predictions.
- The goal is to gain a deeper understanding of how in-context learning works and how it can be improved.
Plain English Explanation
In-context learning is a powerful technique where AI models can learn new skills just by looking at a few examples. This paper tries to understand this process better by using some clever tricks.
First, the researchers show the model both good and bad examples of the task. This "contrastive" approach helps the model learn what to do and what not to do. It's like teaching a child by giving them examples of right and wrong.
Next, they use "saliency maps" to visualize what parts of the input the model is focusing on when making its predictions. This reveals which information the model is using to learn the new task. It's like watching where a student's eyes move when they're solving a problem.
By using these techniques, the researchers hope to get a clearer picture of how in-context learning works under the hood. This knowledge could lead to improving the way language models learn and make them even more powerful and versatile.
Technical Explanation
The paper investigates the process of in-context learning, where language models can rapidly learn new tasks by observing a small number of example demonstrations. The researchers use contrastive demonstrations - showing both positive and negative examples - to help the model better understand the desired behavior.
Additionally, they employ saliency maps to visualize which parts of the input the model is attending to when making predictions. This provides insight into the model's reasoning process and the key information it uses to learn the new task.
The experiments are conducted on a range of language understanding and generation tasks, including text summarization, question answering, and code completion. The results demonstrate that the contrastive demonstration approach can indeed improve in-context learning performance compared to standard demonstration-only methods.
The saliency maps reveal that models trained with contrastive demonstrations tend to focus on more task-relevant features of the input, indicating a better grasp of the underlying concepts. This suggests that this technique could be a promising direction for enhancing the robustness and generalization of in-context learning systems.
Critical Analysis
The paper provides valuable insights into the mechanics of in-context learning, but it also acknowledges several limitations and areas for future research.
One key caveat is that the experiments were conducted on a relatively narrow set of tasks, and it's unclear how well the findings would generalize to a broader range of domains. Additionally, the paper does not delve into the computational and memory overhead associated with the contrastive demonstration approach, which could be an important practical consideration.
Further research is needed to better understand the tradeoffs and optimal strategies for incorporating contrastive information into in-context learning. It would also be interesting to explore how these techniques interact with other recent advancements, such as prompt engineering and meta-learning approaches.
Overall, this paper represents an important step towards a deeper comprehension of in-context learning and points to promising directions for enhancing the flexibility and transparency of these powerful AI systems.
Conclusion
This paper presents a novel approach to understanding in-context learning, a technique where language models can rapidly acquire new skills by observing just a few example demonstrations. By incorporating contrastive demonstrations and using saliency maps, the researchers gain valuable insights into how these models learn and make predictions.
The findings suggest that the contrastive approach helps the models focus on more relevant features of the input, leading to improved performance on a variety of language tasks. This work contributes to our understanding of how in-context learning works and points to promising directions for further enhancing the robustness and generalization of these systems.
As AI models become increasingly capable and integrated into our daily lives, research like this will be crucial for ensuring they behave in predictable and trustworthy ways. By continuing to explore the inner workings of in-context learning, we can unlock new possibilities for building more transparent and adaptable AI assistants.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌿
In-Context Learning Demonstration Selection via Influence Analysis
Vinay M. S., Minh-Hao Van, Xintao Wu
0
0
Large Language Models (LLMs) have showcased their In-Context Learning (ICL) capabilities, enabling few-shot learning without the need for gradient updates. Despite its advantages, the effectiveness of ICL heavily depends on the choice of demonstrations. Selecting the most effective demonstrations for ICL remains a significant research challenge. To tackle this issue, we propose a demonstration selection method named InfICL, which utilizes influence functions to analyze impacts of training samples. By identifying the most influential training samples as demonstrations, InfICL aims to enhance the ICL generalization performance. To keep InfICL cost-effective, we only use the LLM to generate sample input embeddings, avoiding expensive fine-tuning. Through empirical studies on various real-world datasets, we demonstrate advantages of InfICL compared to state-of-the-art baselines.
6/19/2024
🤖
Decomposing Label Space, Format and Discrimination: Rethinking How LLMs Respond and Solve Tasks via In-Context Learning
Quanyu Long, Yin Wu, Wenya Wang, Sinno Jialin Pan
0
0
In-context Learning (ICL) has emerged as a powerful capability alongside the development of scaled-up large language models (LLMs). By instructing LLMs using few-shot demonstrative examples, ICL enables them to perform a wide range of tasks without updating millions of parameters. However, the precise contributions of demonstrations towards improving end-task performance have not been thoroughly investigated in recent analytical studies. In this paper, we empirically decompose the overall performance of ICL into three dimensions, label space, format, and discrimination, and we evaluate four general-purpose LLMs across a diverse range of tasks. Counter-intuitively, we find that the demonstrations have a marginal impact on provoking discriminative knowledge of language models. However, ICL exhibits significant efficacy in regulating the label space and format which helps LLMs to respond in desired label words. We then demonstrate this ability functions similar to detailed instructions for LLMs to follow. We additionally provide an in-depth analysis of the mechanism of retrieval helping with ICL and find that retrieving the most semantically similar examples notably boosts model's discriminative capability.
4/12/2024
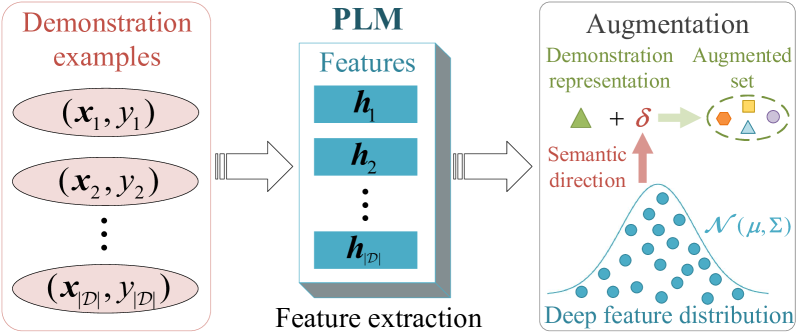
Enhancing In-Context Learning via Implicit Demonstration Augmentation
Xiaoling Zhou, Wei Ye, Yidong Wang, Chaoya Jiang, Zhemg Lee, Rui Xie, Shikun Zhang
0
0
The emergence of in-context learning (ICL) enables large pre-trained language models (PLMs) to make predictions for unseen inputs without updating parameters. Despite its potential, ICL's effectiveness heavily relies on the quality, quantity, and permutation of demonstrations, commonly leading to suboptimal and unstable performance. In this paper, we tackle this challenge for the first time from the perspective of demonstration augmentation. Specifically, we start with enriching representations of demonstrations by leveraging their deep feature distribution. We then theoretically reveal that when the number of augmented copies approaches infinity, the augmentation is approximately equal to a novel logit calibration mechanism integrated with specific statistical properties. This insight results in a simple yet highly efficient method that significantly improves the average and worst-case accuracy across diverse PLMs and tasks. Moreover, our method effectively reduces performance variance among varying demonstrations, permutations, and templates, and displays the capability to address imbalanced class distributions.
7/2/2024
🌿
A Survey on In-context Learning
Qingxiu Dong, Lei Li, Damai Dai, Ce Zheng, Jingyuan Ma, Rui Li, Heming Xia, Jingjing Xu, Zhiyong Wu, Baobao Chang, Xu Sun, Lei Li, Zhifang Sui
0
0
With the increasing capabilities of large language models (LLMs), in-context learning (ICL) has emerged as a new paradigm for natural language processing (NLP), where LLMs make predictions based on contexts augmented with a few examples. It has been a significant trend to explore ICL to evaluate and extrapolate the ability of LLMs. In this paper, we aim to survey and summarize the progress and challenges of ICL. We first present a formal definition of ICL and clarify its correlation to related studies. Then, we organize and discuss advanced techniques, including training strategies, prompt designing strategies, and related analysis. Additionally, we explore various ICL application scenarios, such as data engineering and knowledge updating. Finally, we address the challenges of ICL and suggest potential directions for further research. We hope that our work can encourage more research on uncovering how ICL works and improving ICL.
6/19/2024