Deep Domain Specialisation for single-model multi-domain learning to rank

0

Sign in to get full access
Overview
- This paper presents a new approach called "Deep Domain Specialisation" for training a single machine learning model to perform well on multiple different types of data (domains).
- The key idea is to have the model learn specialized representations for each domain, while also learning shared features that are useful across all domains.
- The authors demonstrate the effectiveness of their approach on the task of "learning to rank" - where the goal is to rank search results or recommendations in order of relevance.
Plain English Explanation
When you're building a machine learning model, you often want it to work well on many different types of data or "domains". For example, you might want a single model that can rank search results for both electronics and fashion. This is similar to the goals of the research in "Retrievable Domain-Sensitive Feature Memory for Multi-Domain Recommendation" and the work on "Large-Scale Multi-Domain Recommendation with Automatic Domain Selection".
The challenge is that different domains often have very different characteristics, so a single "one-size-fits-all" model may not perform well across all of them. The key insight in this paper is to have the model learn specialized representations for each domain, while also finding shared features that work well across all the domains.
The authors call this approach "Deep Domain Specialisation" and show that it leads to better performance than previous methods on the task of "learning to rank" - which is all about putting search results or recommendations in the right order of relevance. This relates to the ideas explored in "More is Better: Deep Domain Adaptation for Multi-Source Transfer Learning" and "Maximal Domain-Independent Representations Improve Transfer Learning".
Technical Explanation
The authors propose a novel neural network architecture that has separate "specialized" components for each domain, as well as "shared" components that capture cross-domain features. During training, the model learns to balance the specialized and shared representations in a way that optimizes performance across all the domains.
Specifically, the architecture has:
- Domain-specific "expert" networks that learn specialized features for each domain
- A shared "generalist" network that learns features common across all domains
- A gating mechanism that dynamically combines the expert and generalist representations for each input example
The authors evaluate this "Deep Domain Specialisation" approach on several standard "learning to rank" benchmark datasets spanning different domains like web search, e-commerce, and question answering. They show that it outperforms both single-domain models and prior multi-domain techniques.
Critical Analysis
The authors provide a thorough empirical evaluation demonstrating the effectiveness of their approach. However, they don't deeply explore the limitations or potential downsides.
One potential issue is the computational overhead of maintaining separate expert networks for each domain. This could make the model less efficient or harder to deploy in real-world settings. The authors also don't investigate how well the approach would scale to a very large number of domains.
Additionally, the paper doesn't provide much insight into how the model is actually learning to balance the specialized and shared representations. A more detailed analysis of the internal workings and learned features could yield useful insights.
Overall, this is a promising piece of research that advances the state-of-the-art in multi-domain machine learning. But as with any study, there are opportunities for further refinement and investigation.
Conclusion
This paper presents a novel "Deep Domain Specialisation" approach that allows a single machine learning model to perform well across multiple different data domains. By learning both specialized and shared representations, the model can leverage domain-specific insights while also capturing cross-domain patterns.
The authors demonstrate the effectiveness of this technique on the "learning to rank" task, where it outperforms previous methods. This work has implications for building more robust and versatile AI systems that can adapt to a variety of real-world applications and datasets.
While the paper has some limitations, it represents an important step forward in the quest to create machine learning models that are truly "multi-talented" - able to excel at diverse tasks without sacrificing performance. Further research in this direction could yield transformative advances in artificial intelligence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Deep Domain Specialisation for single-model multi-domain learning to rank
Paul Missault, Abdelmaseeh Felfel
Information Retrieval (IR) practitioners often train separate ranking models for different domains (geographic regions, languages, stores, websites,...) as it is believed that exclusively training on in-domain data yields the best performance when sufficient data is available. Despite their performance gains, training multiple models comes at a higher cost to train, maintain and update compared to having only a single model responsible for all domains. Our work explores consolidated ranking models that serve multiple domains. Specifically, we propose a novel architecture of Deep Domain Specialisation (DDS) to consolidate multiple domains into a single model. We compare our proposal against Deep Domain Adaptation (DDA) and a set of baseline for multi-domain models. In our experiments, DDS performed the best overall while requiring fewer parameters per domain as other baselines. We show the efficacy of our method both with offline experimentation and on a large-scale online experiment on Amazon customer traffic.
Read more7/2/2024
🖼️
0
Multi-domain improves out-of-distribution and data-limited scenarios for medical image analysis
Ece Ozkan, Xavier Boix
Current machine learning methods for medical image analysis primarily focus on developing models tailored for their specific tasks, utilizing data within their target domain. These specialized models tend to be data-hungry and often exhibit limitations in generalizing to out-of-distribution samples. In this work, we show that employing models that incorporate multiple domains instead of specialized ones significantly alleviates the limitations observed in specialized models. We refer to this approach as multi-domain model and compare its performance to that of specialized models. For this, we introduce the incorporation of diverse medical image domains, including different imaging modalities like X-ray, MRI, CT, and ultrasound images, as well as various viewpoints such as axial, coronal, and sagittal views. Our findings underscore the superior generalization capabilities of multi-domain models, particularly in scenarios characterized by limited data availability and out-of-distribution, frequently encountered in healthcare applications. The integration of diverse data allows multi-domain models to utilize information across domains, enhancing the overall outcomes substantially. To illustrate, for organ recognition, multi-domain model can enhance accuracy by up to 8% compared to conventional specialized models.
Read more7/8/2024
✨
0
Retrievable Domain-Sensitive Feature Memory for Multi-Domain Recommendation
Yuang Zhao, Zhaocheng Du, Qinglin Jia, Linxuan Zhang, Zhenhua Dong, Ruiming Tang
With the increase in the business scale and number of domains in online advertising, multi-domain ad recommendation has become a mainstream solution in the industry. The core of multi-domain recommendation is effectively modeling the commonalities and distinctions among domains. Existing works are dedicated to designing model architectures for implicit multi-domain modeling while overlooking an in-depth investigation from a more fundamental perspective of feature distributions. This paper focuses on features with significant differences across various domains in both distributions and effects on model predictions. We refer to these features as domain-sensitive features, which serve as carriers of domain distinctions and are crucial for multi-domain modeling. Experiments demonstrate that existing multi-domain modeling methods may neglect domain-sensitive features, indicating insufficient learning of domain distinctions. To avoid this neglect, we propose a domain-sensitive feature attribution method to identify features that best reflect domain distinctions from the feature set. Further, we design a memory architecture that extracts domain-specific information from domain-sensitive features for the model to retrieve and integrate, thereby enhancing the awareness of domain distinctions. Extensive offline and online experiments demonstrate the superiority of our method in capturing domain distinctions and improving multi-domain recommendation performance.
Read more5/22/2024
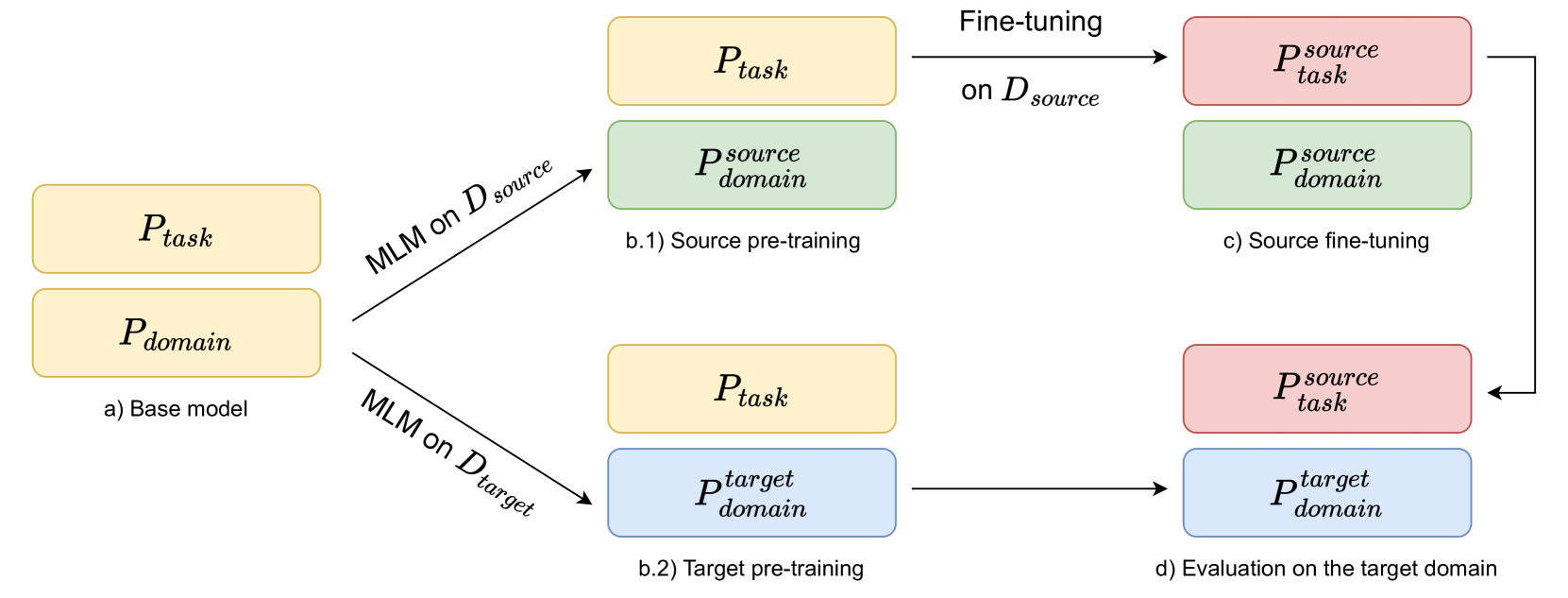
0
Simple Domain Adaptation for Sparse Retrievers
Mathias Vast, Yuxuan Zong, Basile Van Cooten, Benjamin Piwowarski, Laure Soulier
In Information Retrieval, and more generally in Natural Language Processing, adapting models to specific domains is conducted through fine-tuning. Despite the successes achieved by this method and its versatility, the need for human-curated and labeled data makes it impractical to transfer to new tasks, domains, and/or languages when training data doesn't exist. Using the model without training (zero-shot) is another option that however suffers an effectiveness cost, especially in the case of first-stage retrievers. Numerous research directions have emerged to tackle these issues, most of them in the context of adapting to a task or a language. However, the literature is scarcer for domain (or topic) adaptation. In this paper, we address this issue of cross-topic discrepancy for a sparse first-stage retriever by transposing a method initially designed for language adaptation. By leveraging pre-training on the target data to learn domain-specific knowledge, this technique alleviates the need for annotated data and expands the scope of domain adaptation. Despite their relatively good generalization ability, we show that even sparse retrievers can benefit from our simple domain adaptation method.
Read more7/8/2024