Deep Reinforcement Learning-Based Approach for a Single Vehicle Persistent Surveillance Problem with Fuel Constraints
2404.06423
0
0

Abstract
This article presents a deep reinforcement learning-based approach to tackle a persistent surveillance mission requiring a single unmanned aerial vehicle initially stationed at a depot with fuel or time-of-flight constraints to repeatedly visit a set of targets with equal priority. Owing to the vehicle's fuel or time-of-flight constraints, the vehicle must be regularly refueled, or its battery must be recharged at the depot. The objective of the problem is to determine an optimal sequence of visits to the targets that minimizes the maximum time elapsed between successive visits to any target while ensuring that the vehicle never runs out of fuel or charge. We present a deep reinforcement learning algorithm to solve this problem and present the results of numerical experiments that corroborate the effectiveness of this approach in comparison with common-sense greedy heuristics.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Explores a persistent surveillance problem with fuel constraints using deep reinforcement learning
- Presents an approach to optimize the trajectory of a single vehicle for surveillance while considering fuel limitations
- Investigates the trade-off between surveillance coverage and fuel consumption
Plain English Explanation
This research paper proposes a deep reinforcement learning-based approach to address a single vehicle persistent surveillance problem, where the vehicle must continuously monitor an area while accounting for fuel constraints. The key challenge is to find an optimal trajectory that maximizes the surveillance coverage while ensuring the vehicle has enough fuel to complete its mission.
The researchers developed a deep reinforcement learning model that can learn to navigate the vehicle efficiently, balancing the need for comprehensive surveillance with the limitations of the vehicle's fuel capacity. By using deep learning techniques, the model can analyze complex environmental factors and make informed decisions about the vehicle's movement to achieve the best overall performance.
The paper explores the trade-offs between maximizing surveillance coverage and minimizing fuel consumption, as these two objectives can sometimes conflict. The deep reinforcement learning approach allows the system to learn how to navigate this balance, finding solutions that provide effective surveillance while ensuring the vehicle can return to its starting point without running out of fuel.
Technical Explanation
The researchers formulated the persistent surveillance problem as a Markov Decision Process (MDP), where the agent (the single vehicle) must learn to navigate the environment and make decisions that optimize the surveillance coverage while respecting the fuel constraints. They designed a deep reinforcement learning algorithm to solve this MDP, utilizing a deep neural network to approximate the value function and policy.
The state of the MDP includes the vehicle's position, orientation, and fuel level, as well as the surveillance coverage of the environment. The action space consists of the vehicle's movement decisions, such as moving forward, turning left or right, or hovering in place. The reward function encourages the vehicle to maximize the surveillance coverage while minimizing fuel consumption.
The researchers trained the deep reinforcement learning model using a combination of techniques, including experience replay and target networks, to improve the stability and convergence of the learning process. They evaluated the performance of their approach through simulation experiments, comparing it to alternative methods and analyzing the trade-offs between surveillance coverage and fuel consumption.
Critical Analysis
The paper presents a compelling approach to addressing the persistent surveillance problem with fuel constraints, but it also acknowledges several limitations and areas for further research. One key limitation is the assumption of a single vehicle, which may not be realistic in many real-world scenarios where multiple vehicles or a fleet-based system would be more appropriate.
Additionally, the paper does not consider the potential for dynamic changes in the environment, such as the appearance of new obstacles or targets, which could require the vehicle to adapt its behavior in real-time. Exploring how the deep reinforcement learning model could handle such dynamic situations would be an important area for future research.
While the simulation results demonstrate the effectiveness of the proposed approach, it would be valuable to validate the findings through real-world experiments or field trials. This would help to assess the practical feasibility and scalability of the method, as well as identify any additional challenges that may arise in a physical implementation.
Conclusion
This research paper presents a novel deep reinforcement learning-based approach to address the persistent surveillance problem with fuel constraints. By formulating the problem as an MDP and developing a deep neural network-based solution, the researchers have demonstrated a promising way to optimize the trajectory of a single vehicle for effective surveillance while considering the limitations of its fuel capacity.
The findings of this study offer valuable insights for researchers and practitioners working on autonomous vehicle control, surveillance systems, and decision-making under uncertainty. The approach could have applications in a wide range of domains, from environmental monitoring to search and rescue operations, where the efficient use of limited resources is a critical concern.
While the paper highlights several areas for further research, the overall contribution of this work lies in its innovative use of deep reinforcement learning to address a complex real-world problem, offering a potential pathway towards more robust and efficient autonomous surveillance systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
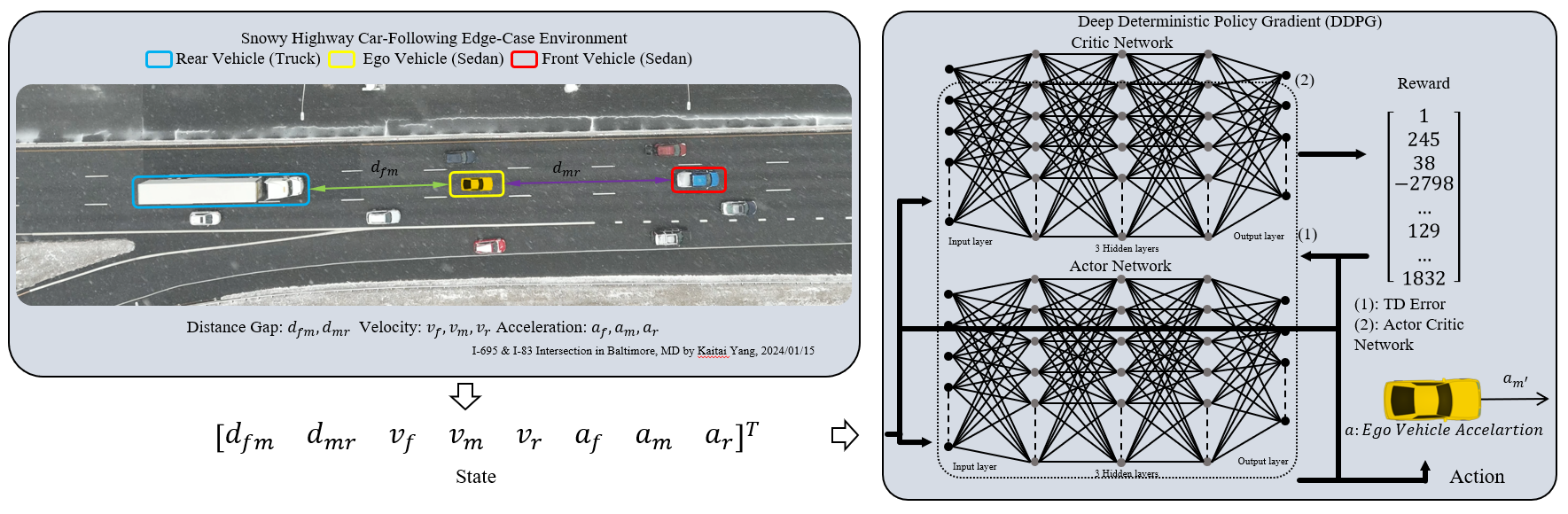
Deep Reinforcement Learning for Advanced Longitudinal Control and Collision Avoidance in High-Risk Driving Scenarios
Dianwei Chen, Yaobang Gong, Xianfeng Yang
0
0
Existing Advanced Driver Assistance Systems primarily focus on the vehicle directly ahead, often overlooking potential risks from following vehicles. This oversight can lead to ineffective handling of high risk situations, such as high speed, closely spaced, multi vehicle scenarios where emergency braking by one vehicle might trigger a pile up collision. To overcome these limitations, this study introduces a novel deep reinforcement learning based algorithm for longitudinal control and collision avoidance. This proposed algorithm effectively considers the behavior of both leading and following vehicles. Its implementation in simulated high risk scenarios, which involve emergency braking in dense traffic where traditional systems typically fail, has demonstrated the algorithm ability to prevent potential pile up collisions, including those involving heavy duty vehicles.
5/1/2024
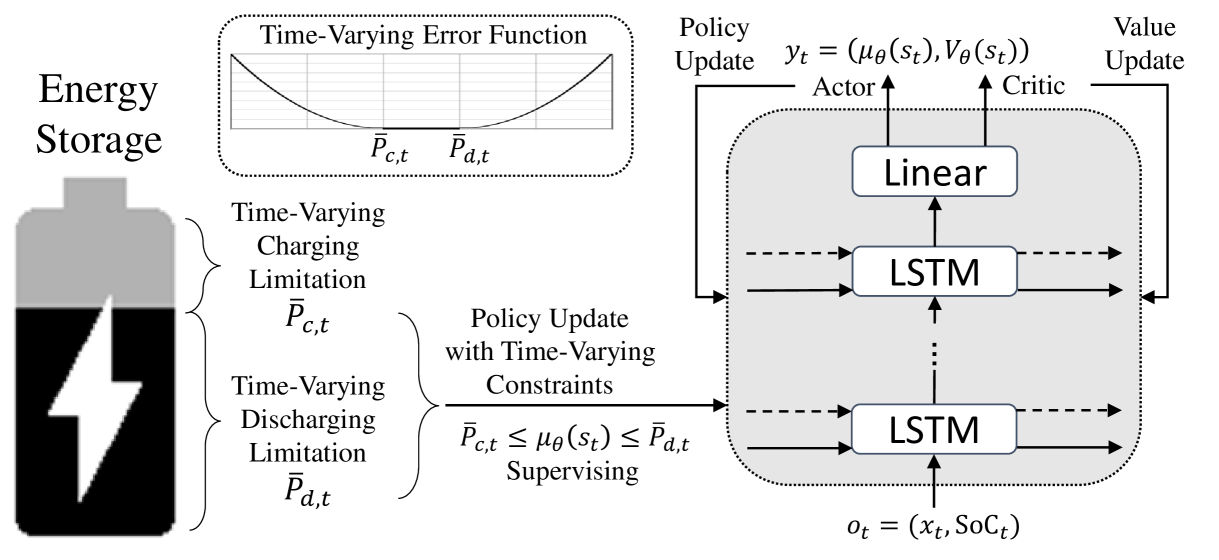
New!Time-Varying Constraint-Aware Reinforcement Learning for Energy Storage Control
Jaeik Jeong, Tai-Yeon Ku, Wan-Ki Park
0
0
Energy storage devices, such as batteries, thermal energy storages, and hydrogen systems, can help mitigate climate change by ensuring a more stable and sustainable power supply. To maximize the effectiveness of such energy storage, determining the appropriate charging and discharging amounts for each time period is crucial. Reinforcement learning is preferred over traditional optimization for the control of energy storage due to its ability to adapt to dynamic and complex environments. However, the continuous nature of charging and discharging levels in energy storage poses limitations for discrete reinforcement learning, and time-varying feasible charge-discharge range based on state of charge (SoC) variability also limits the conventional continuous reinforcement learning. In this paper, we propose a continuous reinforcement learning approach that takes into account the time-varying feasible charge-discharge range. An additional objective function was introduced for learning the feasible action range for each time period, supplementing the objectives of training the actor for policy learning and the critic for value learning. This actively promotes the utilization of energy storage by preventing them from getting stuck in suboptimal states, such as continuous full charging or discharging. This is achieved through the enforcement of the charging and discharging levels into the feasible action range. The experimental results demonstrated that the proposed method further maximized the effectiveness of energy storage by actively enhancing its utilization.
5/20/2024
SmartPathfinder: Pushing the Limits of Heuristic Solutions for Vehicle Routing Problem with Drones Using Reinforcement Learning
Navid Mohammad Imran, Myounggyu Won
0
0
The Vehicle Routing Problem with Drones (VRPD) seeks to optimize the routing paths for both trucks and drones, where the trucks are responsible for delivering parcels to customer locations, and the drones are dispatched from these trucks for parcel delivery, subsequently being retrieved by the trucks. Given the NP-Hard complexity of VRPD, numerous heuristic approaches have been introduced. However, improving solution quality and reducing computation time remain significant challenges. In this paper, we conduct a comprehensive examination of heuristic methods designed for solving VRPD, distilling and standardizing them into core elements. We then develop a novel reinforcement learning (RL) framework that is seamlessly integrated with the heuristic solution components, establishing a set of universal principles for incorporating the RL framework with heuristic strategies in an aim to improve both the solution quality and computation speed. This integration has been applied to a state-of-the-art heuristic solution for VRPD, showcasing the substantial benefits of incorporating the RL framework. Our evaluation results demonstrated that the heuristic solution incorporated with our RL framework not only elevated the quality of solutions but also achieved rapid computation speeds, especially when dealing with extensive customer locations.
4/23/2024
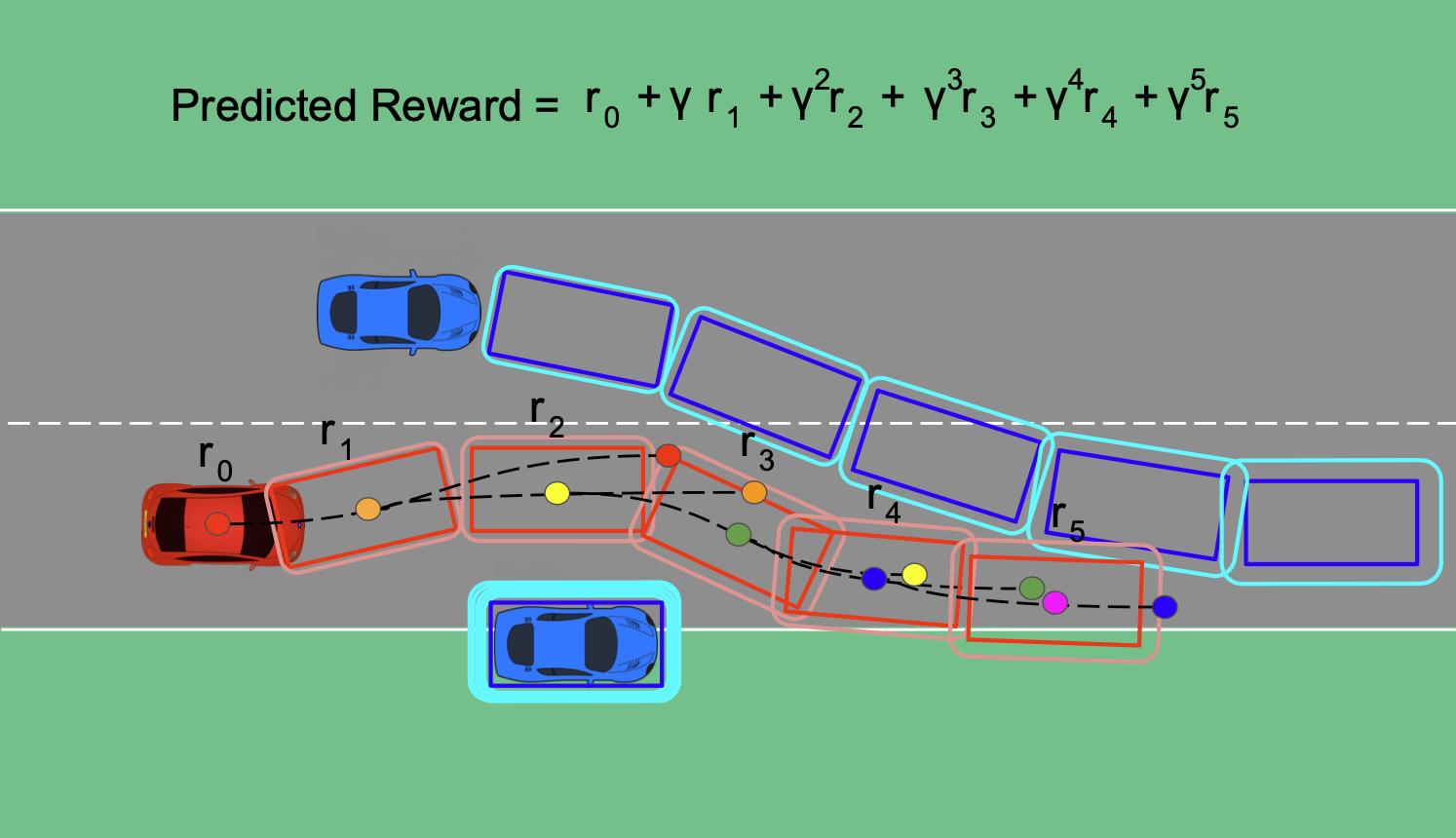
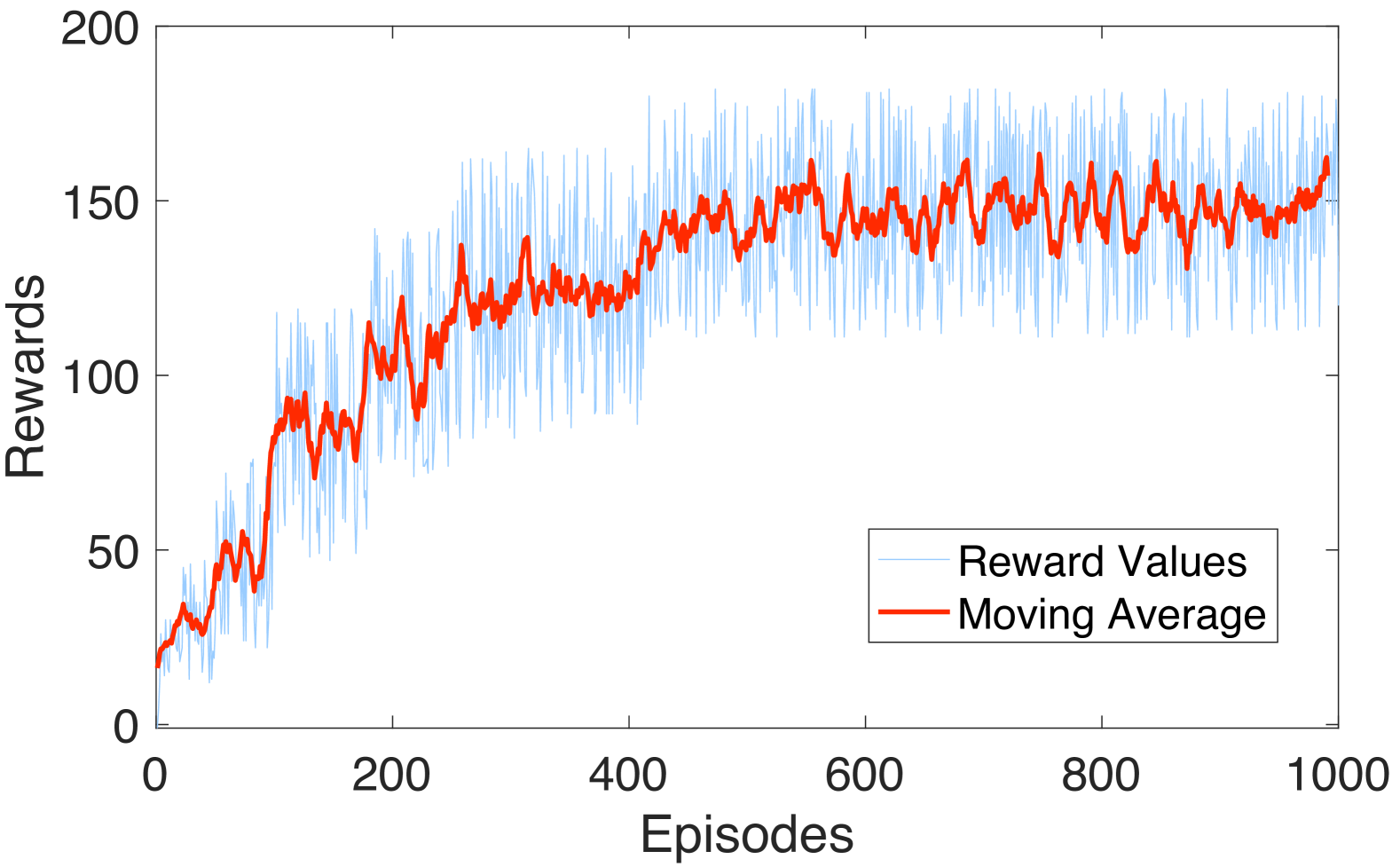
Trajectory Planning for Autonomous Vehicle Using Iterative Reward Prediction in Reinforcement Learning
Hyunwoo Park
0
0
Traditional trajectory planning methods for autonomous vehicles have several limitations. For example, heuristic and explicit simple rules limit generalizability and hinder complex motions. These limitations can be addressed using reinforcement learning-based trajectory planning. However, reinforcement learning suffers from unstable learning, and existing reinforcement learning-based trajectory planning methods do not consider the uncertainties. Thus, this paper, proposes a reinforcement learning-based trajectory planning method for autonomous vehicles. The proposed method involves an iterative reward prediction approach that iteratively predicts expectations of future states. These predicted states are then used to forecast rewards and integrated into the learning process to enhance stability. Additionally, a method is proposed that utilizes uncertainty propagation to make the reinforcement learning agent aware of uncertainties. The proposed method was evaluated using the CARLA simulator. Compared to the baseline methods, the proposed method reduced the collision rate by 60.17 %, and increased the average reward by 30.82 times. A video of the proposed method is available at https://www.youtube.com/watch?v=PfDbaeLfcN4.
5/14/2024