Collision Avoidance and Navigation for a Quadrotor Swarm Using End-to-end Deep Reinforcement Learning
2309.13285
0
0

Abstract
End-to-end deep reinforcement learning (DRL) for quadrotor control promises many benefits -- easy deployment, task generalization and real-time execution capability. Prior end-to-end DRL-based methods have showcased the ability to deploy learned controllers onto single quadrotors or quadrotor teams maneuvering in simple, obstacle-free environments. However, the addition of obstacles increases the number of possible interactions exponentially, thereby increasing the difficulty of training RL policies. In this work, we propose an end-to-end DRL approach to control quadrotor swarms in environments with obstacles. We provide our agents a curriculum and a replay buffer of the clipped collision episodes to improve performance in obstacle-rich environments. We implement an attention mechanism to attend to the neighbor robots and obstacle interactions - the first successful demonstration of this mechanism on policies for swarm behavior deployed on severely compute-constrained hardware. Our work is the first work that demonstrates the possibility of learning neighbor-avoiding and obstacle-avoiding control policies trained with end-to-end DRL that transfers zero-shot to real quadrotors. Our approach scales to 32 robots with 80% obstacle density in simulation and 8 robots with 20% obstacle density in physical deployment. Video demonstrations are available on the project website at: https://sites.google.com/view/obst-avoid-swarm-rl.
Create account to get full access
Overview
- This paper explores the use of end-to-end deep reinforcement learning to enable collision avoidance and navigation for a swarm of quadrotors.
- The researchers developed a deep neural network model that can directly map raw sensor data to control actions, allowing the quadrotors to learn complex navigation behaviors without the need for explicit modeling or hand-engineered controllers.
- The proposed approach was evaluated in simulation and demonstrated successful collision avoidance and goal-directed navigation in crowded environments.
Plain English Explanation
In this research, the authors investigated how to enable a group of small flying robots called quadrotors to navigate safely while avoiding collisions with each other and obstacles in their environment. Traditionally, programming these types of robots to navigate complex spaces required carefully designing and tuning control algorithms based on a detailed understanding of the robot's dynamics and the environment.
Instead, the researchers took a different approach called deep reinforcement learning. They trained a deep neural network model to directly map the sensor data from the quadrotors (like camera images and distance measurements) to the control actions needed to fly the robots. This allowed the quadrotors to learn effective navigation strategies through trial and error, without requiring explicit programmed rules.
The key advantage of this end-to-end deep reinforcement learning approach is that the neural network can discover complex, adaptive behaviors that are difficult to anticipate and program manually. The researchers found that their trained model enabled the quadrotor swarm to successfully navigate through crowded virtual environments, avoiding collisions while still reaching their target destinations.
Technical Explanation
The authors proposed an end-to-end deep reinforcement learning framework for collision avoidance and navigation of a quadrotor swarm. They used a deep neural network to directly map raw sensor inputs (e.g., camera images, distance measurements) to the control actions needed to fly the quadrotors, without relying on explicitly programmed navigation algorithms.
The neural network was trained using a reinforcement learning approach, where the quadrotors learned effective behaviors through trial-and-error exploration in a simulated environment. The reward function encouraged the quadrotors to reach their goal destinations while avoiding collisions with each other and static obstacles.
The researchers evaluated their approach in simulation, testing the quadrotor swarm's ability to navigate through crowded environments with varying obstacle densities. They found that the end-to-end deep reinforcement learning model enabled the quadrotors to successfully avoid collisions and reach their targets, outperforming a baseline approach that used a more traditional, hand-engineered control system.
Critical Analysis
The authors acknowledge several caveats and limitations of their work. First, the experiments were conducted solely in simulation, and further testing would be needed to validate the approach in real-world conditions. Additionally, the researchers note that their model was trained on a specific environment and task, and it is unclear how well it would generalize to more diverse or complex scenarios.
Another potential issue is the "black box" nature of the deep neural network model, which can make it challenging to understand and interpret the learned navigation strategies. This lack of interpretability could be a concern for safety-critical applications, where the rationale behind the robots' decisions needs to be more transparent.
Finally, the authors do not address the computational and energy requirements of running the deep neural network on the quadrotors themselves. In a real-world deployment, these resource constraints would be an important practical consideration.
Conclusion
This research demonstrates the potential of end-to-end deep reinforcement learning to enable complex navigation behaviors for a swarm of quadrotors, without the need for explicit programming of collision avoidance and path planning algorithms. By directly mapping sensor inputs to control actions, the deep neural network model was able to discover effective strategies for safely navigating crowded environments and reaching target destinations.
While the results are promising, further research is needed to address the limitations of the current approach, such as validating the system in real-world conditions, improving the interpretability of the learned behaviors, and optimizing the computational requirements. Nonetheless, this work represents an important step forward in the development of autonomous swarm robotics systems that can adapt to dynamic and uncertain environments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
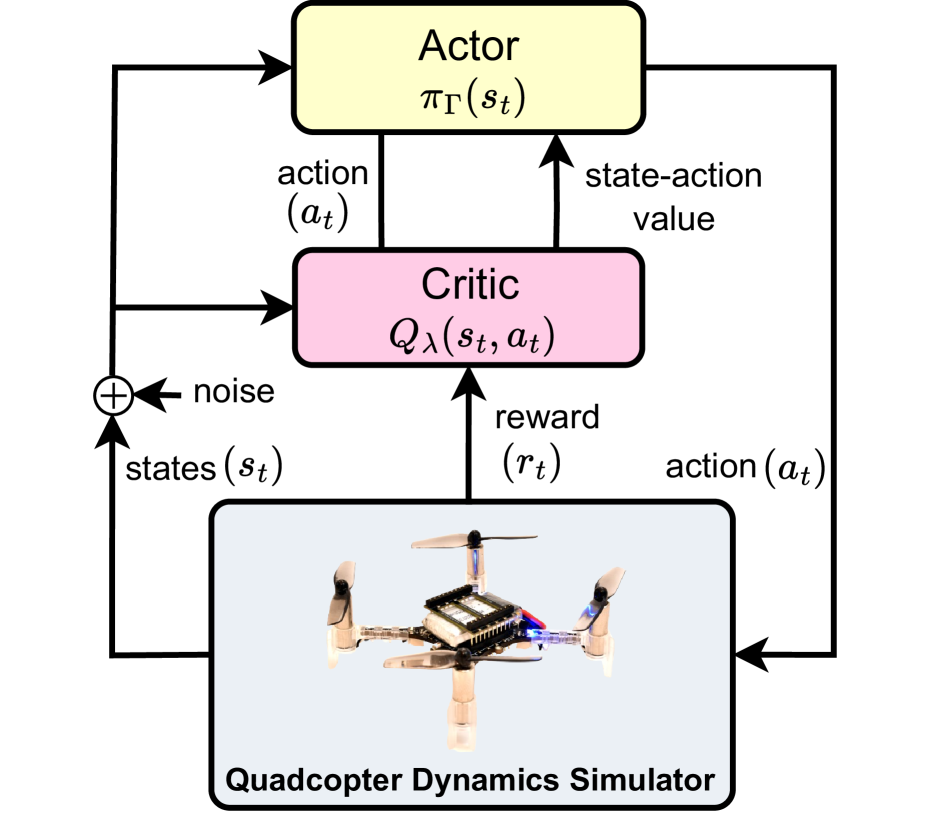
Deep Reinforcement Learning-based Quadcopter Controller: A Practical Approach and Experiments
Truong-Dong Do, Nguyen Xuan Mung, Sung Kyung Hong
0
0
Quadcopters have been studied for decades thanks to their maneuverability and capability of operating in a variety of circumstances. However, quadcopters suffer from dynamical nonlinearity, actuator saturation, as well as sensor noise that make it challenging and time consuming to obtain accurate dynamic models and achieve satisfactory control performance. Fortunately, deep reinforcement learning came and has shown significant potential in system modelling and control of autonomous multirotor aerial vehicles, with recent advancements in deployment, performance enhancement, and generalization. In this paper, an end-to-end deep reinforcement learning-based controller for quadcopters is proposed that is secure for real-world implementation, data-efficient, and free of human gain adjustments. First, a novel actor-critic-based architecture is designed to map the robot states directly to the motor outputs. Then, a quadcopter dynamics-based simulator was devised to facilitate the training of the controller policy. Finally, the trained policy is deployed on a real Crazyflie nano quadrotor platform, without any additional fine-tuning process. Experimental results show that the quadcopter exhibits satisfactory performance as it tracks a given complicated trajectory, which demonstrates the effectiveness and feasibility of the proposed method and signifies its capability in filling the simulation-to-reality gap.
6/19/2024
↗️
Integrating DeepRL with Robust Low-Level Control in Robotic Manipulators for Non-Repetitive Reaching Tasks
Mehdi Heydari Shahna, Seyed Adel Alizadeh Kolagar, Jouni Mattila
0
0
In robotics, contemporary strategies are learning-based, characterized by a complex black-box nature and a lack of interpretability, which may pose challenges in ensuring stability and safety. To address these issues, we propose integrating a collision-free trajectory planner based on deep reinforcement learning (DRL) with a novel auto-tuning low-level control strategy, all while actively engaging in the learning phase through interactions with the environment. This approach circumvents the control performance and complexities associated with computations while addressing nonrepetitive reaching tasks in the presence of obstacles. First, a model-free DRL agent is employed to plan velocity-bounded motion for a manipulator with 'n' degrees of freedom (DoF), ensuring collision avoidance for the end-effector through joint-level reasoning. The generated reference motion is then input into a robust subsystem-based adaptive controller, which produces the necessary torques, while the cuckoo search optimization (CSO) algorithm enhances control gains to minimize the stabilization and tracking error in the steady state. This approach guarantees robustness and uniform exponential convergence in an unfamiliar environment, despite the presence of uncertainties and disturbances. Theoretical assertions are validated through the presentation of simulation outcomes.
5/16/2024
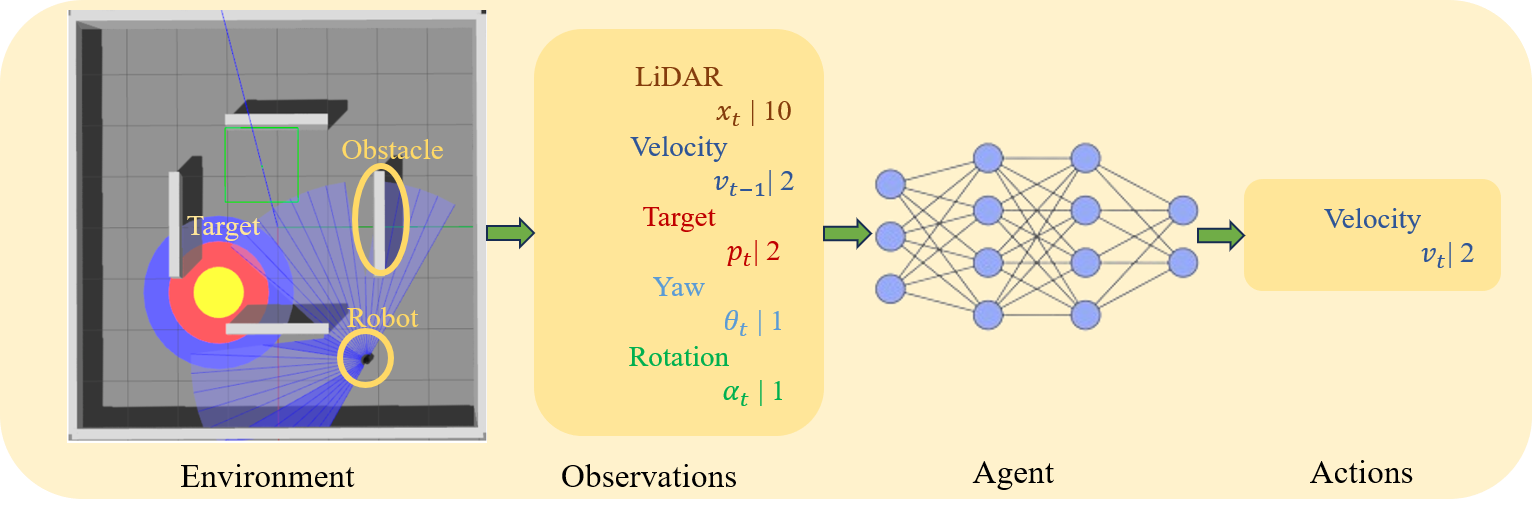
Deep Reinforcement Learning with Enhanced PPO for Safe Mobile Robot Navigation
Hamid Taheri, Seyed Rasoul Hosseini
0
0
Collision-free motion is essential for mobile robots. Most approaches to collision-free and efficient navigation with wheeled robots require parameter tuning by experts to obtain good navigation behavior. This study investigates the application of deep reinforcement learning to train a mobile robot for autonomous navigation in a complex environment. The robot utilizes LiDAR sensor data and a deep neural network to generate control signals guiding it toward a specified target while avoiding obstacles. We employ two reinforcement learning algorithms in the Gazebo simulation environment: Deep Deterministic Policy Gradient and proximal policy optimization. The study introduces an enhanced neural network structure in the Proximal Policy Optimization algorithm to boost performance, accompanied by a well-designed reward function to improve algorithm efficacy. Experimental results conducted in both obstacle and obstacle-free environments underscore the effectiveness of the proposed approach. This research significantly contributes to the advancement of autonomous robotics in complex environments through the application of deep reinforcement learning.
5/28/2024
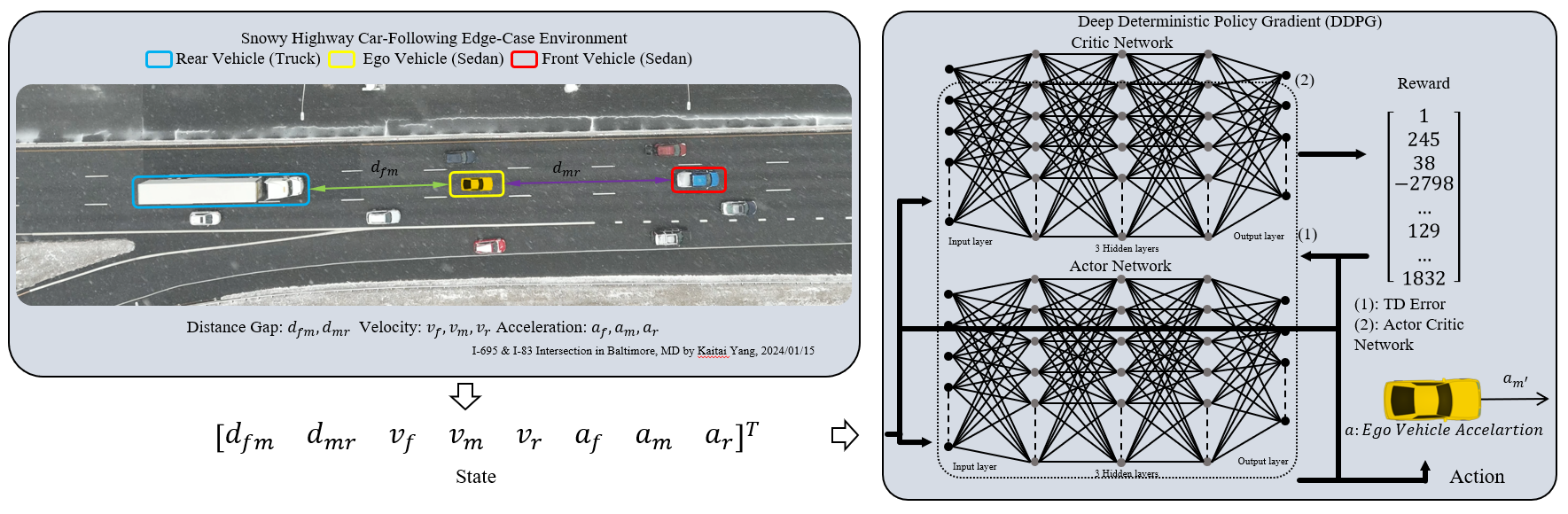
Deep Reinforcement Learning for Advanced Longitudinal Control and Collision Avoidance in High-Risk Driving Scenarios
Dianwei Chen, Yaobang Gong, Xianfeng Yang
0
0
Existing Advanced Driver Assistance Systems primarily focus on the vehicle directly ahead, often overlooking potential risks from following vehicles. This oversight can lead to ineffective handling of high risk situations, such as high speed, closely spaced, multi vehicle scenarios where emergency braking by one vehicle might trigger a pile up collision. To overcome these limitations, this study introduces a novel deep reinforcement learning based algorithm for longitudinal control and collision avoidance. This proposed algorithm effectively considers the behavior of both leading and following vehicles. Its implementation in simulated high risk scenarios, which involve emergency braking in dense traffic where traditional systems typically fail, has demonstrated the algorithm ability to prevent potential pile up collisions, including those involving heavy duty vehicles.
5/1/2024