Deep Reinforcement Learning for Time-Critical Wilderness Search And Rescue Using Drones

0
🤿
Sign in to get full access
Overview
- Traditional search and rescue methods in wilderness areas can be time-consuming and have limited coverage
- Drones offer a faster and more flexible solution, but optimizing their search paths is crucial
- This paper explores the use of deep reinforcement learning to create efficient search missions for drones in wilderness environments
Plain English Explanation
When people go missing in remote wilderness areas, the traditional methods used to find them can be slow and only cover a small area. Drones could be a better solution, as they can search much faster and over a wider region. However, figuring out the best flight paths for the drones to maximize the chances of finding the missing person is a complex problem.
This research looks at using a powerful AI technique called deep reinforcement learning to plan efficient search missions for drones in wilderness environments. The key idea is that the AI system can learn the optimal flight paths by considering information about the search area and the missing person's likely location, which is represented as a probability distribution map. By learning from this data, the AI can discover flight patterns that are much more effective at finding the missing person quickly compared to traditional search planning algorithms.
Technical Explanation
The paper proposes a deep reinforcement learning approach to plan search missions for drones in wilderness areas. The system leverages a priori data about the search region and the missing person's probable location, represented as a probability distribution map. This allows the deep reinforcement learning agent to learn flight paths that maximize the chances of finding the missing person as quickly as possible.
Unlike previous work, the approach utilizes a continuous action space enabled by cubature, which allows for more nuanced and flexible flight patterns. The experimental results show that the deep reinforcement learning method significantly outperforms traditional coverage planning and search planning algorithms, in some cases reducing search times by over 160%. This dramatic improvement could be the difference between life and death in real-world search and rescue operations.
Critical Analysis
The paper makes a compelling case for the benefits of using deep reinforcement learning to optimize drone search missions in wilderness areas. The experimental results demonstrating substantial improvements in search times compared to other algorithms are quite promising. However, the research does not address potential limitations or challenges that may arise when deploying such a system in real-world scenarios.
For example, the paper does not discuss how the system would handle dynamic changes in the environment, such as shifting weather conditions or the movement of the missing person. Coordinating multiple drones to work together efficiently is also an important consideration that is not explored. Additionally, the reliance on a priori data about the search area and missing person's location may not always be available in practice.
Further research is needed to address these practical concerns and validate the approach in more realistic search and rescue settings. Exploring the integration of this deep reinforcement learning technique with other path planning and routing algorithms could also lead to further improvements.
Conclusion
This paper presents a promising deep reinforcement learning approach for optimizing drone search missions in wilderness environments. By leveraging a priori data about the search area and missing person's likely location, the system can learn flight paths that significantly outperform traditional search planning algorithms, potentially saving valuable time in real-world search and rescue operations.
While the research demonstrates the potential of this technique, further work is needed to address practical deployment challenges and validate the approach in more realistic scenarios. Integrating the deep reinforcement learning method with other planning and coordination algorithms could lead to even more effective search and rescue solutions powered by AI.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤿
0
Deep Reinforcement Learning for Time-Critical Wilderness Search And Rescue Using Drones
Jan-Hendrik Ewers, David Anderson, Douglas Thomson
Traditional search and rescue methods in wilderness areas can be time-consuming and have limited coverage. Drones offer a faster and more flexible solution, but optimizing their search paths is crucial. This paper explores the use of deep reinforcement learning to create efficient search missions for drones in wilderness environments. Our approach leverages a priori data about the search area and the missing person in the form of a probability distribution map. This allows the deep reinforcement learning agent to learn optimal flight paths that maximize the probability of finding the missing person quickly. Experimental results show that our method achieves a significant improvement in search times compared to traditional coverage planning and search planning algorithms. In one comparison, deep reinforcement learning is found to outperform other algorithms by over $160%$, a difference that can mean life or death in real-world search operations. Additionally, unlike previous work, our approach incorporates a continuous action space enabled by cubature, allowing for more nuanced flight patterns.
Read more5/24/2024

0
Optimizing Search and Rescue UAV Connectivity in Challenging Terrain through Multi Q-Learning
Mohammed M. H. Qazzaz, Syed A. R. Zaidi, Desmond C. McLernon, Abdelaziz Salama, Aubida A. Al-Hameed
Using Unmanned Aerial Vehicles (UAVs) in Search and rescue operations (SAR) to navigate challenging terrain while maintaining reliable communication with the cellular network is a promising approach. This paper suggests a novel technique employing a reinforcement learning multi Q-learning algorithm to optimize UAV connectivity in such scenarios. We introduce a Strategic Planning Agent for efficient path planning and collision awareness and a Real-time Adaptive Agent to maintain optimal connection with the cellular base station. The agents trained in a simulated environment using multi Q-learning, encouraging them to learn from experience and adjust their decision-making to diverse terrain complexities and communication scenarios. Evaluation results reveal the significance of the approach, highlighting successful navigation in environments with varying obstacle densities and the ability to perform optimal connectivity using different frequency bands. This work paves the way for enhanced UAV autonomy and enhanced communication reliability in search and rescue operations.
Read more5/17/2024
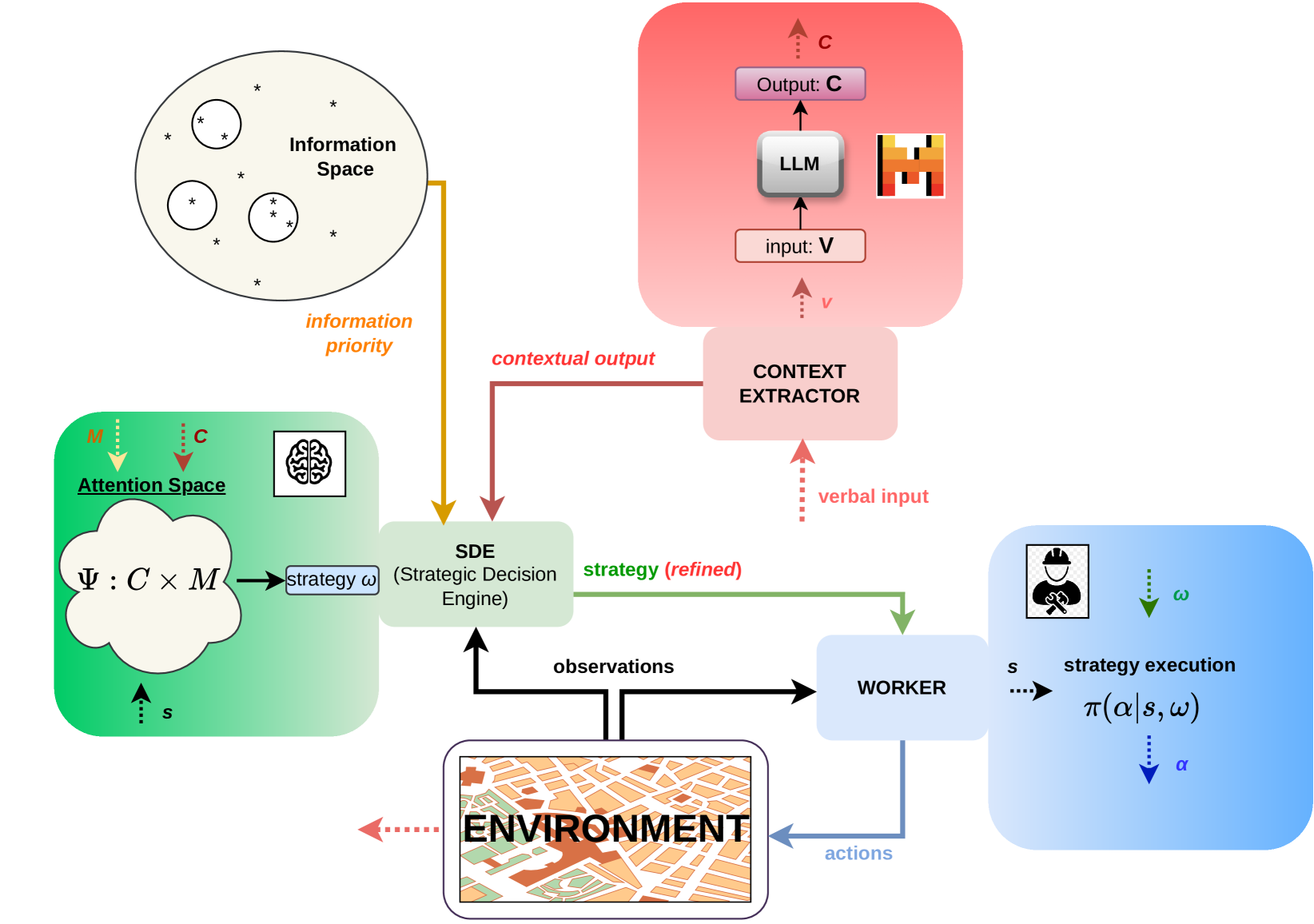
0
Selective Exploration and Information Gathering in Search and Rescue Using Hierarchical Learning Guided by Natural Language Input
Dimitrios Panagopoulos, Adoldo Perrusquia, Weisi Guo
In recent years, robots and autonomous systems have become increasingly integral to our daily lives, offering solutions to complex problems across various domains. Their application in search and rescue (SAR) operations, however, presents unique challenges. Comprehensively exploring the disaster-stricken area is often infeasible due to the vastness of the terrain, transformed environment, and the time constraints involved. Traditional robotic systems typically operate on predefined search patterns and lack the ability to incorporate and exploit ground truths provided by human stakeholders, which can be the key to speeding up the learning process and enhancing triage. Addressing this gap, we introduce a system that integrates social interaction via large language models (LLMs) with a hierarchical reinforcement learning (HRL) framework. The proposed system is designed to translate verbal inputs from human stakeholders into actionable RL insights and adjust its search strategy. By leveraging human-provided information through LLMs and structuring task execution through HRL, our approach not only bridges the gap between autonomous capabilities and human intelligence but also significantly improves the agent's learning efficiency and decision-making process in environments characterised by long horizons and sparse rewards.
Read more9/23/2024

0
Navigation in a simplified Urban Flow through Deep Reinforcement Learning
Federica Tonti, Jean Rabault, Ricardo Vinuesa
The increasing number of unmanned aerial vehicles (UAVs) in urban environments requires a strategy to minimize their environmental impact, both in terms of energy efficiency and noise reduction. In order to reduce these concerns, novel strategies for developing prediction models and optimization of flight planning, for instance through deep reinforcement learning (DRL), are needed. Our goal is to develop DRL algorithms capable of enabling the autonomous navigation of UAVs in urban environments, taking into account the presence of buildings and other UAVs, optimizing the trajectories in order to reduce both energetic consumption and noise. This is achieved using fluid-flow simulations which represent the environment in which UAVs navigate and training the UAV as an agent interacting with an urban environment. In this work, we consider a domain domain represented by a two-dimensional flow field with obstacles, ideally representing buildings, extracted from a three-dimensional high-fidelity numerical simulation. The presented methodology, using PPO+LSTM cells, was validated by reproducing a simple but fundamental problem in navigation, namely the Zermelo's problem, which deals with a vessel navigating in a turbulent flow, travelling from a starting point to a target location, optimizing the trajectory. The current method shows a significant improvement with respect to both a simple PPO and a TD3 algorithm, with a success rate (SR) of the PPO+LSTM trained policy of 98.7%, and a crash rate (CR) of 0.1%, outperforming both PPO (SR = 75.6%, CR=18.6%) and TD3 (SR=77.4% and CR=14.5%). This is the first step towards DRL strategies which will guide UAVs in a three-dimensional flow field using real-time signals, making the navigation efficient in terms of flight time and avoiding damages to the vehicle.
Read more9/27/2024