Selective Exploration and Information Gathering in Search and Rescue Using Hierarchical Learning Guided by Natural Language Input

0
Sign in to get full access
Overview
- Presents a hierarchical learning approach to guide search and rescue operations using natural language instructions
- Leverages large language models to interpret high-level instructions and translate them into low-level actions for robotic agents
- Enables selective exploration and information gathering to efficiently locate and rescue targets
Plain English Explanation
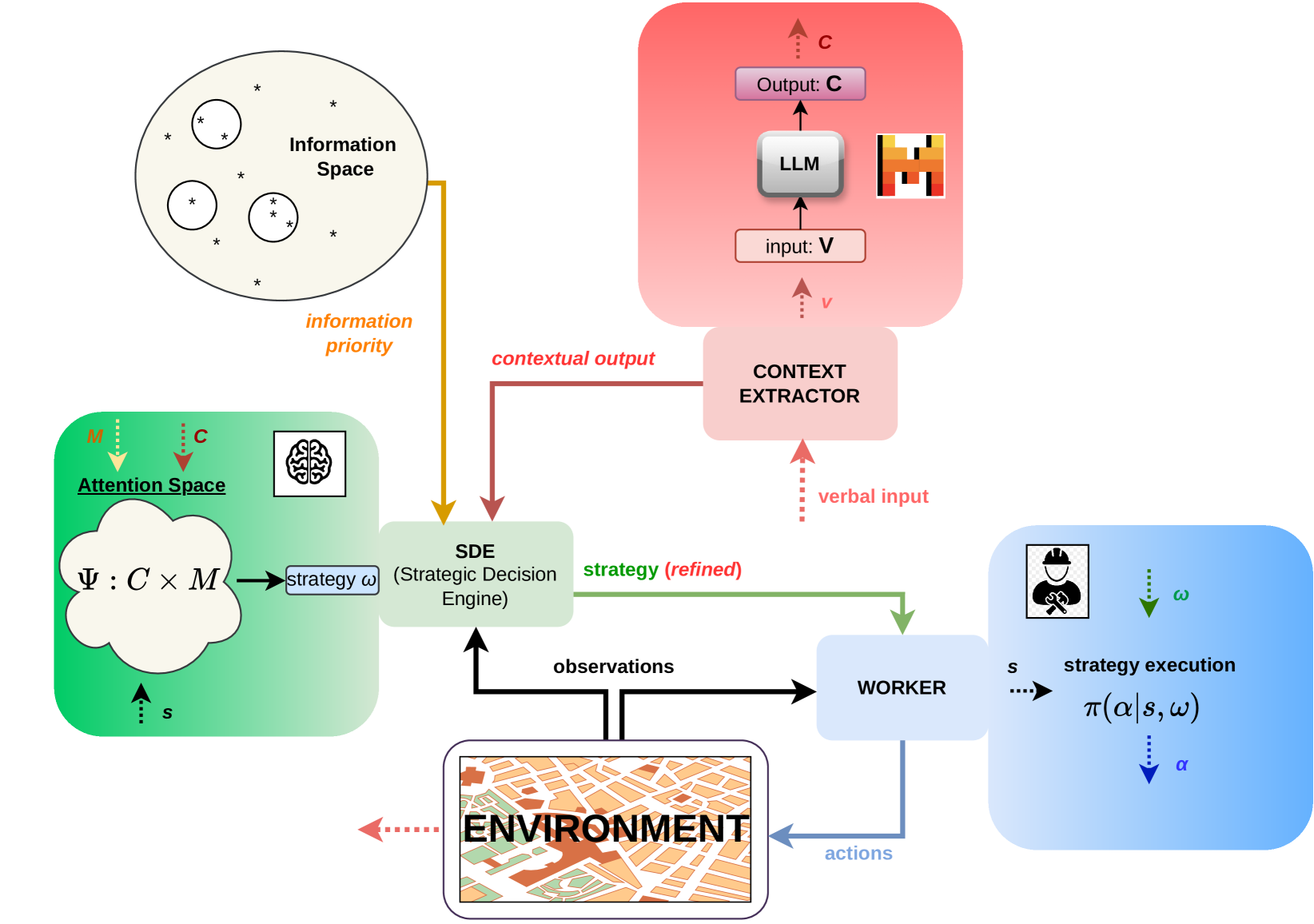
This research paper introduces a novel approach to guide search and rescue operations using a hierarchical learning system. The key idea is to leverage the power of large language models to interpret high-level natural language instructions and translate them into specific low-level actions for robotic agents.
The system works by first understanding the overall mission and objectives conveyed through natural language input. It then breaks down these high-level instructions into a hierarchy of sub-tasks that the robotic agents can execute. This allows the system to selectively explore the environment and gather information in a targeted and efficient manner, rather than blindly searching the entire area.
By bridging the gap between human-provided directives and the actual robot behaviors, this approach enables more effective and coordinated search and rescue operations. The robotic agents can dynamically adjust their exploration and information gathering strategies based on the evolving situation, guided by the natural language feedback from human operators.
Technical Explanation
The core of this research is a hierarchical learning framework that combines large language models with reinforcement learning techniques. The high-level natural language input is first processed by a language model to extract the key objectives and constraints of the search and rescue mission.
This information is then used to guide a hierarchical reinforcement learning agent, which breaks down the overall task into a series of sub-goals. The agents can selectively explore the environment, gather relevant information, and coordinate their actions to efficiently locate and rescue targets.
The natural language understanding capabilities of the system allow it to adapt to changing circumstances and dynamically adjust the exploration and information gathering strategies based on real-time feedback from human operators.
Critical Analysis
The authors acknowledge several limitations and areas for future research. For example, the current system relies on a centralized planning approach, which may not scale well to large-scale, distributed search and rescue operations. Additionally, the natural language understanding capabilities of the system are still limited, and more work is needed to handle complex, ambiguous, or context-dependent instructions.
Furthermore, the paper does not address potential issues related to the safety and reliability of the robotic agents in real-world search and rescue scenarios, where unpredictable environmental conditions and unforeseen obstacles may pose significant challenges.
Conclusion
This research presents a promising approach to enhance the efficiency and effectiveness of search and rescue operations by leveraging hierarchical learning and natural language processing. By bridging the gap between high-level human instructions and low-level robot behaviors, the system can guide robotic agents to selectively explore the environment and gather relevant information in a coordinated manner.
While the current implementation has some limitations, the underlying concepts and techniques hold significant potential for further development and real-world deployment. As natural language understanding and hierarchical reinforcement learning continue to advance, this type of integrated system could become an invaluable tool for first responders and search and rescue teams in the future.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Selective Exploration and Information Gathering in Search and Rescue Using Hierarchical Learning Guided by Natural Language Input
Dimitrios Panagopoulos, Adoldo Perrusquia, Weisi Guo
In recent years, robots and autonomous systems have become increasingly integral to our daily lives, offering solutions to complex problems across various domains. Their application in search and rescue (SAR) operations, however, presents unique challenges. Comprehensively exploring the disaster-stricken area is often infeasible due to the vastness of the terrain, transformed environment, and the time constraints involved. Traditional robotic systems typically operate on predefined search patterns and lack the ability to incorporate and exploit ground truths provided by human stakeholders, which can be the key to speeding up the learning process and enhancing triage. Addressing this gap, we introduce a system that integrates social interaction via large language models (LLMs) with a hierarchical reinforcement learning (HRL) framework. The proposed system is designed to translate verbal inputs from human stakeholders into actionable RL insights and adjust its search strategy. By leveraging human-provided information through LLMs and structuring task execution through HRL, our approach not only bridges the gap between autonomous capabilities and human intelligence but also significantly improves the agent's learning efficiency and decision-making process in environments characterised by long horizons and sparse rewards.
Read more9/23/2024
💬
0
How Can Large Language Models Enable Better Socially Assistive Human-Robot Interaction: A Brief Survey
Zhonghao Shi, Ellen Landrum, Amy O' Connell, Mina Kian, Leticia Pinto-Alva, Kaleen Shrestha, Xiaoyuan Zhu, Maja J Matari'c
Socially assistive robots (SARs) have shown great success in providing personalized cognitive-affective support for user populations with special needs such as older adults, children with autism spectrum disorder (ASD), and individuals with mental health challenges. The large body of work on SAR demonstrates its potential to provide at-home support that complements clinic-based interventions delivered by mental health professionals, making these interventions more effective and accessible. However, there are still several major technical challenges that hinder SAR-mediated interactions and interventions from reaching human-level social intelligence and efficacy. With the recent advances in large language models (LLMs), there is an increased potential for novel applications within the field of SAR that can significantly expand the current capabilities of SARs. However, incorporating LLMs introduces new risks and ethical concerns that have not yet been encountered, and must be carefully be addressed to safely deploy these more advanced systems. In this work, we aim to conduct a brief survey on the use of LLMs in SAR technologies, and discuss the potentials and risks of applying LLMs to the following three major technical challenges of SAR: 1) natural language dialog; 2) multimodal understanding; 3) LLMs as robot policies.
Read more4/9/2024
🌿
0
Scaling Up Natural Language Understanding for Multi-Robots Through the Lens of Hierarchy
Shaojun Xu, Xusheng Luo, Yutong Huang, Letian Leng, Ruixuan Liu, Changliu Liu
Long-horizon planning is hindered by challenges such as uncertainty accumulation, computational complexity, delayed rewards and incomplete information. This work proposes an approach to exploit the task hierarchy from human instructions to facilitate multi-robot planning. Using Large Language Models (LLMs), we propose a two-step approach to translate multi-sentence instructions into a structured language, Hierarchical Linear Temporal Logic (LTL), which serves as a formal representation for planning. Initially, LLMs transform the instructions into a hierarchical representation defined as Hierarchical Task Tree, capturing the logical and temporal relations among tasks. Following this, a domain-specific fine-tuning of LLM translates sub-tasks of each task into flat LTL formulas, aggregating them to form hierarchical LTL specifications. These specifications are then leveraged for planning using off-the-shelf planners. Our framework not only bridges the gap between instructions and algorithmic planning but also showcases the potential of LLMs in harnessing hierarchical reasoning to automate multi-robot task planning. Through evaluations in both simulation and real-world experiments involving human participants, we demonstrate that our method can handle more complex instructions compared to existing methods. The results indicate that our approach achieves higher success rates and lower costs in multi-robot task allocation and plan generation. Demos videos are available at https://youtu.be/7WOrDKxIMIs .
Read more8/16/2024

0
LGR2: Language Guided Reward Relabeling for Accelerating Hierarchical Reinforcement Learning
Utsav Singh, Pramit Bhattacharyya, Vinay P. Namboodiri
Developing interactive systems that leverage natural language instructions to solve complex robotic control tasks has been a long-desired goal in the robotics community. Large Language Models (LLMs) have demonstrated exceptional abilities in handling complex tasks, including logical reasoning, in-context learning, and code generation. However, predicting low-level robotic actions using LLMs poses significant challenges. Additionally, the complexity of such tasks usually demands the acquisition of policies to execute diverse subtasks and combine them to attain the ultimate objective. Hierarchical Reinforcement Learning (HRL) is an elegant approach for solving such tasks, which provides the intuitive benefits of temporal abstraction and improved exploration. However, HRL faces the recurring issue of non-stationarity due to unstable lower primitive behaviour. In this work, we propose LGR2, a novel HRL framework that leverages language instructions to generate a stationary reward function for the higher-level policy. Since the language-guided reward is unaffected by the lower primitive behaviour, LGR2 mitigates non-stationarity and is thus an elegant method for leveraging language instructions to solve robotic control tasks. To analyze the efficacy of our approach, we perform empirical analysis and demonstrate that LGR2 effectively alleviates non-stationarity in HRL. Our approach attains success rates exceeding 70$%$ in challenging, sparse-reward robotic navigation and manipulation environments where the baselines fail to achieve any significant progress. Additionally, we conduct real-world robotic manipulation experiments and demonstrate that CRISP shows impressive generalization in real-world scenarios.
Read more6/18/2024