DeepAir: A Multi-Agent Deep Reinforcement Learning Based Scheme for an Unknown User Location Problem

0

Sign in to get full access
Overview
- This paper presents a multi-agent deep reinforcement learning-based scheme called DeepAir for addressing the unknown user location problem in UAV (Unmanned Aerial Vehicle) networks.
- The goal is to efficiently allocate UAV resources to serve users with unknown locations using decentralized decision-making.
- The proposed approach leverages deep reinforcement learning to enable UAVs to learn optimal resource allocation policies without prior knowledge of user locations.
Plain English Explanation
The paper introduces a new system called DeepAir that uses multi-agent deep reinforcement learning to help UAVs efficiently serve users with unknown locations.
In a UAV network, the UAVs need to figure out the best way to allocate their resources (like network bandwidth) to provide service to users. Normally, the UAVs would need to know the locations of the users ahead of time to do this efficiently. However, in many real-world scenarios, the user locations are unknown.
DeepAir solves this problem by allowing the UAVs to learn how to optimally allocate resources through a process of trial-and-error, without needing to know the user locations in advance. Each UAV acts as an independent "agent" and uses deep reinforcement learning techniques to learn the best actions to take based on the current conditions. Over time, the UAVs get better and better at serving the users even when their locations are unknown.
Technical Explanation
The core of the DeepAir system is a multi-agent deep reinforcement learning framework. Each UAV is modeled as an independent agent that can observe the current state of the environment (e.g. network conditions, other UAV actions) and take actions (e.g. how to allocate resources) to maximize a reward signal (e.g. user satisfaction).
The agents use deep neural networks to map their observations to optimal actions. They learn these neural network policies through a process of trial-and-error, receiving feedback in the form of rewards that encourage them to take actions leading to better outcomes. Over many iterations, the agents converge on policies that allow them to efficiently serve users without knowing their locations in advance.
The paper evaluates DeepAir through simulations that compare its performance to other benchmark approaches. The results show that DeepAir can achieve significantly higher user satisfaction and resource utilization compared to schemes that require prior knowledge of user locations.
Critical Analysis
The paper provides a thoughtful and well-designed solution to the challenging problem of serving users with unknown locations in UAV networks. The use of multi-agent deep reinforcement learning is a clever approach that allows the UAVs to learn optimal policies in a decentralized manner.
However, the paper does not address a few potential limitations of the approach:
- The simulation environment may not fully capture the complexity of real-world UAV networks, which could impact the performance of DeepAir in practice.
- The training process for the deep neural networks could be computationally intensive, which may limit the scalability of the approach as the number of UAVs increases.
- There are open questions around the stability and convergence guarantees of the multi-agent reinforcement learning algorithms used in DeepAir.
Further research could explore these areas and investigate ways to make the DeepAir system more robust and scalable for real-world UAV network deployments.
Conclusion
This paper introduces DeepAir, a novel multi-agent deep reinforcement learning-based scheme for efficiently serving users with unknown locations in UAV networks. By allowing UAVs to learn optimal resource allocation policies through trial-and-error, DeepAir can achieve significantly better performance compared to approaches that require prior knowledge of user locations.
The technical contributions of the paper, as well as the potential limitations and areas for future research, provide a valuable foundation for further advancements in this important area of UAV network optimization. As UAV-based services continue to grow, solutions like DeepAir will become increasingly crucial for ensuring efficient and reliable connectivity, even in the face of uncertain and dynamic user environments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
DeepAir: A Multi-Agent Deep Reinforcement Learning Based Scheme for an Unknown User Location Problem
Baris Yamansavascilar, Atay Ozgovde, Cem Ersoy
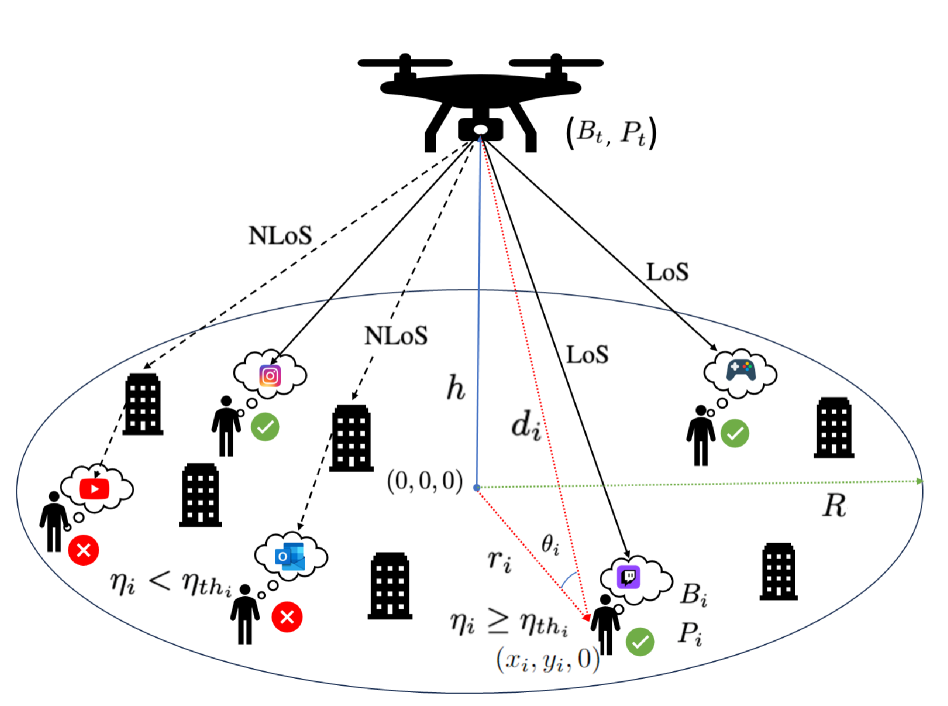
The deployment of unmanned aerial vehicles (UAVs) in many different settings has provided various solutions and strategies for networking paradigms. Therefore, it reduces the complexity of the developments for the existing problems, which otherwise require more sophisticated approaches. One of those existing problems is the unknown user locations in an infrastructure-less environment in which users cannot connect to any communication device or computation-providing server, which is essential to task offloading in order to achieve the required quality of service (QoS). Therefore, in this study, we investigate this problem thoroughly and propose a novel deep reinforcement learning (DRL) based scheme, DeepAir. DeepAir considers all of the necessary steps including sensing, localization, resource allocation, and multi-access edge computing (MEC) to achieve QoS requirements for the offloaded tasks without violating the maximum tolerable delay. To this end, we use two types of UAVs including detector UAVs, and serving UAVs. We utilize detector UAVs as DRL agents which ensure sensing, localization, and resource allocation. On the other hand, we utilize serving UAVs to provide MEC features. Our experiments show that DeepAir provides a high task success rate by deploying fewer detector UAVs in the environment, which includes different numbers of users and user attraction points, compared to benchmark methods.
Read more8/13/2024
0
A Novel Joint DRL-Based Utility Optimization for UAV Data Services
Xuli Cai, Poonam Lohan, Burak Kantarci
In this paper, we propose a novel joint deep reinforcement learning (DRL)-based solution to optimize the utility of an uncrewed aerial vehicle (UAV)-assisted communication network. To maximize the number of users served within the constraints of the UAV's limited bandwidth and power resources, we employ deep Q-Networks (DQN) and deep deterministic policy gradient (DDPG) algorithms for optimal resource allocation to ground users with heterogeneous data rate demands. The DQN algorithm dynamically allocates multiple bandwidth resource blocks to different users based on current demand and available resource states. Simultaneously, the DDPG algorithm manages power allocation, continuously adjusting power levels to adapt to varying distances and fading conditions, including Rayleigh fading for non-line-of-sight (NLoS) links and Rician fading for line-of-sight (LoS) links. Our joint DRL-based solution demonstrates an increase of up to 41% in the number of users served compared to scenarios with equal bandwidth and power allocation.
Read more6/18/2024

0
DRAL: Deep Reinforcement Adaptive Learning for Multi-UAVs Navigation in Unknown Indoor Environment
Kangtong Mo, Linyue Chu, Xingyu Zhang, Xiran Su, Yang Qian, Yining Ou, Wian Pretorius
Autonomous indoor navigation of UAVs presents numerous challenges, primarily due to the limited precision of GPS in enclosed environments. Additionally, UAVs' limited capacity to carry heavy or power-intensive sensors, such as overheight packages, exacerbates the difficulty of achieving autonomous navigation indoors. This paper introduces an advanced system in which a drone autonomously navigates indoor spaces to locate a specific target, such as an unknown Amazon package, using only a single camera. Employing a deep learning approach, a deep reinforcement adaptive learning algorithm is trained to develop a control strategy that emulates the decision-making process of an expert pilot. We demonstrate the efficacy of our system through real-time simulations conducted in various indoor settings. We apply multiple visualization techniques to gain deeper insights into our trained network. Furthermore, we extend our approach to include an adaptive control algorithm for coordinating multiple drones to lift an object in an indoor environment collaboratively. Integrating our DRAL algorithm enables multiple UAVs to learn optimal control strategies that adapt to dynamic conditions and uncertainties. This innovation enhances the robustness and flexibility of indoor navigation and opens new possibilities for complex multi-drone operations in confined spaces. The proposed framework highlights significant advancements in adaptive control and deep reinforcement learning, offering robust solutions for complex multi-agent systems in real-world applications.
Read more9/9/2024
🏅
0
Multi-Agent Reinforcement Learning for Offloading Cellular Communications with Cooperating UAVs
Abhishek Mondal, Deepak Mishra, Ganesh Prasad, George C. Alexandropoulos, Azzam Alnahari, Riku Jantti
Effective solutions for intelligent data collection in terrestrial cellular networks are crucial, especially in the context of Internet of Things applications. The limited spectrum and coverage area of terrestrial base stations pose challenges in meeting the escalating data rate demands of network users. Unmanned aerial vehicles, known for their high agility, mobility, and flexibility, present an alternative means to offload data traffic from terrestrial BSs, serving as additional access points. This paper introduces a novel approach to efficiently maximize the utilization of multiple UAVs for data traffic offloading from terrestrial BSs. Specifically, the focus is on maximizing user association with UAVs by jointly optimizing UAV trajectories and users association indicators under quality of service constraints. Since, the formulated UAVs control problem is nonconvex and combinatorial, this study leverages the multi agent reinforcement learning framework. In this framework, each UAV acts as an independent agent, aiming to maintain inter UAV cooperative behavior. The proposed approach utilizes the finite state Markov decision process to account for UAVs velocity constraints and the relationship between their trajectories and state space. A low complexity distributed state action reward state action algorithm is presented to determine UAVs optimal sequential decision making policies over training episodes. The extensive simulation results validate the proposed analysis and offer valuable insights into the optimal UAV trajectories. The derived trajectories demonstrate superior average UAV association performance compared to benchmark techniques such as Q learning and particle swarm optimization.
Read more6/4/2024