Deeper Understanding of Black-box Predictions via Generalized Influence Functions
2312.05586
0
0
Abstract
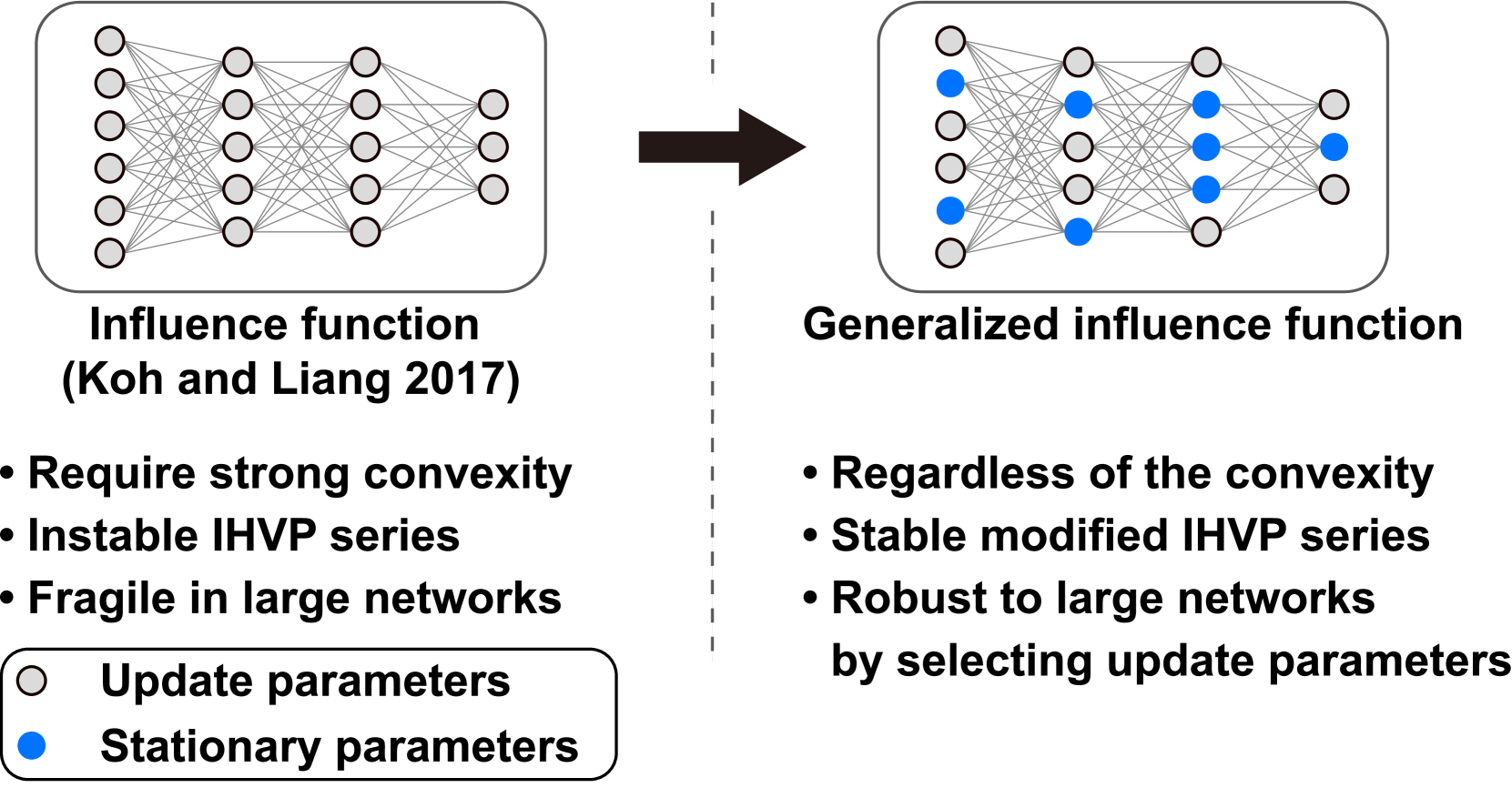
Influence functions (IFs) elucidate how training data changes model behavior. However, the increasing size and non-convexity in large-scale models make IFs inaccurate. We suspect that the fragility comes from the first-order approximation which may cause nuisance changes in parameters irrelevant to the examined data. However, simply computing influence from the chosen parameters can be misleading, as it fails to nullify the hidden effects of unselected parameters on the analyzed data. Thus, our approach introduces generalized IFs, precisely estimating target parameters' influence while nullifying nuisance gradient changes on fixed parameters. We identify target update parameters closely associated with the input data by the output- and gradient-based parameter selection methods. We verify the generalized IFs with various alternatives of IFs on the class removal and label change tasks. The experiments align with the less is more philosophy, demonstrating that updating only 5% of the model produces more accurate results than other influence functions across all tasks. We believe our proposal works as a foundational tool for optimizing models, conducting data analysis, and enhancing AI interpretability beyond the limitation of IFs. Codes are available at https://github.com/hslyu/GIF.
Create account to get full access
Overview
- This paper introduces a generalized approach to understanding the influence of individual data points on the predictions made by black-box machine learning models.
- The proposed method, called Generalized Influence Functions (GIF), extends the concept of influence functions from linear models to more complex, non-linear models.
- GIF can be used to quantify the impact of individual data points on a model's predictions, providing insights into the model's decision-making process.
Plain English Explanation
Machine learning models, especially complex "black-box" models, can be difficult to understand. Influence functions are a technique that can help explain how individual data points affect a model's predictions, but they were previously limited to simpler, linear models.
This paper introduces a new approach called Generalized Influence Functions (GIF) that extends the influence function concept to more complex, non-linear models. GIF allows you to see how changing a specific data point would affect the model's predictions, even for sophisticated models like neural networks.
By understanding which data points have the most influence on a model's decisions, you can gain insights into how the model is working and potentially identify biases or issues in the data or model. This can be particularly useful for high-stakes applications, where it's important to understand and trust the model's behavior.
The paper demonstrates the use of GIF on various machine learning tasks, showing how it can provide a "deeper understanding" of black-box model predictions. Overall, GIF is a powerful tool for interpreting and debugging complex machine learning models.
Technical Explanation
The paper starts by introducing the concept of influence functions, which quantify the effect of a single data point on a model's parameters or predictions. Influence functions were previously limited to linear models, but the authors propose a generalized approach called Generalized Influence Functions (GIF) that can be applied to more complex, non-linear models.
The key idea behind GIF is to approximate the change in a model's predictions when a single data point is modified, without having to retrain the entire model. This is done by computing the gradient of the model's predictions with respect to the data point in question, and then using a first-order Taylor expansion to estimate the change in predictions.
The paper presents several algorithms for efficiently computing GIF, including a general-purpose method that can be applied to any differentiable model, as well as specialized techniques for linear models and deep neural networks. The authors also discuss how GIF can be used to identify influential data points, analyze model biases, and perform other model interpretation tasks.
The performance of GIF is evaluated on a variety of machine learning tasks, including image classification, language modeling, and recommender systems. The results show that GIF can provide valuable insights into the behavior of black-box models, and that it outperforms existing model interpretation methods in many scenarios.
Critical Analysis
The paper presents a compelling and well-executed approach for understanding the behavior of complex machine learning models. The key strengths of the GIF method are its generality (it can be applied to a wide range of models) and its computational efficiency (it avoids the need to retrain models to assess the influence of individual data points).
However, the paper also acknowledges several limitations and areas for further research. For example, the authors note that GIF relies on a first-order Taylor approximation, which may not be accurate for large perturbations to the data. Additionally, the paper does not address the potential for GIF to be misused or misinterpreted, which is an important consideration for any model interpretation technique.
It would also be interesting to see the authors explore the relationship between GIF and other model interpretation methods, such as feature importance or counterfactual explanations. Combining GIF with these other techniques could provide even deeper insights into the inner workings of black-box models.
Overall, the Generalized Influence Functions approach presented in this paper represents a significant advance in the field of model interpretability. While there are some open questions and areas for future research, the authors have made an important contribution to our understanding of complex machine learning models.
Conclusion
This paper introduces a novel approach called Generalized Influence Functions (GIF) that extends the concept of influence functions to enable a deeper understanding of the predictions made by complex, black-box machine learning models. GIF provides a computationally efficient way to quantify the impact of individual data points on a model's outputs, which can be valuable for tasks like identifying biases, debugging model behavior, and increasing trust in high-stakes applications.
The authors demonstrate the effectiveness of GIF on a range of machine learning tasks, showing how it outperforms existing model interpretation methods. While the approach has some limitations, it represents an important step forward in the field of model interpretability and opens up new avenues for understanding the decision-making processes of sophisticated AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Outlier Gradient Analysis: Efficiently Improving Deep Learning Model Performance via Hessian-Free Influence Functions
Anshuman Chhabra, Bo Li, Jian Chen, Prasant Mohapatra, Hongfu Liu
0
0
Influence functions offer a robust framework for assessing the impact of each training data sample on model predictions, serving as a prominent tool in data-centric learning. Despite their widespread use in various tasks, the strong convexity assumption on the model and the computational cost associated with calculating the inverse of the Hessian matrix pose constraints, particularly when analyzing large deep models. This paper focuses on a classical data-centric scenario--trimming detrimental samples--and addresses both challenges within a unified framework. Specifically, we establish an equivalence transformation between identifying detrimental training samples via influence functions and outlier gradient detection. This transformation not only presents a straightforward and Hessian-free formulation but also provides profound insights into the role of the gradient in sample impact. Moreover, it relaxes the convexity assumption of influence functions, extending their applicability to non-convex deep models. Through systematic empirical evaluations, we first validate the correctness of our proposed outlier gradient analysis on synthetic datasets and then demonstrate its effectiveness in detecting mislabeled samples in vision models, selecting data samples for improving performance of transformer models for natural language processing, and identifying influential samples for fine-tuned Large Language Models.
5/14/2024
Revisit, Extend, and Enhance Hessian-Free Influence Functions
Ziao Yang, Han Yue, Jian Chen, Hongfu Liu
0
0
Influence functions serve as crucial tools for assessing sample influence in model interpretation, subset training set selection, noisy label detection, and more. By employing the first-order Taylor extension, influence functions can estimate sample influence without the need for expensive model retraining. However, applying influence functions directly to deep models presents challenges, primarily due to the non-convex nature of the loss function and the large size of model parameters. This difficulty not only makes computing the inverse of the Hessian matrix costly but also renders it non-existent in some cases. Various approaches, including matrix decomposition, have been explored to expedite and approximate the inversion of the Hessian matrix, with the aim of making influence functions applicable to deep models. In this paper, we revisit a specific, albeit naive, yet effective approximation method known as TracIn. This method substitutes the inverse of the Hessian matrix with an identity matrix. We provide deeper insights into why this simple approximation method performs well. Furthermore, we extend its applications beyond measuring model utility to include considerations of fairness and robustness. Finally, we enhance TracIn through an ensemble strategy. To validate its effectiveness, we conduct experiments on synthetic data and extensive evaluations on noisy label detection, sample selection for large language model fine-tuning, and defense against adversarial attacks.
5/29/2024
📊
Measuring Stochastic Data Complexity with Boltzmann Influence Functions
Nathan Ng, Roger Grosse, Marzyeh Ghassemi
0
0
Estimating the uncertainty of a model's prediction on a test point is a crucial part of ensuring reliability and calibration under distribution shifts. A minimum description length approach to this problem uses the predictive normalized maximum likelihood (pNML) distribution, which considers every possible label for a data point, and decreases confidence in a prediction if other labels are also consistent with the model and training data. In this work we propose IF-COMP, a scalable and efficient approximation of the pNML distribution that linearizes the model with a temperature-scaled Boltzmann influence function. IF-COMP can be used to produce well-calibrated predictions on test points as well as measure complexity in both labelled and unlabelled settings. We experimentally validate IF-COMP on uncertainty calibration, mislabel detection, and OOD detection tasks, where it consistently matches or beats strong baseline methods.
6/6/2024
🔍
Individual Fairness Through Reweighting and Tuning
Abdoul Jalil Djiberou Mahamadou, Lea Goetz, Russ Altman
0
0
Inherent bias within society can be amplified and perpetuated by artificial intelligence (AI) systems. To address this issue, a wide range of solutions have been proposed to identify and mitigate bias and enforce fairness for individuals and groups. Recently, Graph Laplacian Regularizer (GLR), a regularization technique from the semi-supervised learning literature has been used as a substitute for the common Lipschitz condition to enhance individual fairness. Notable prior work has shown that enforcing individual fairness through a GLR can improve the transfer learning accuracy of AI models under covariate shifts. However, the prior work defines a GLR on the source and target data combined, implicitly assuming that the target data are available at train time, which might not hold in practice. In this work, we investigated whether defining a GLR independently on the train and target data could maintain similar accuracy. Furthermore, we introduced the Normalized Fairness Gain score (NFG) to measure individual fairness by measuring the amount of gained fairness when a GLR is used versus not. We evaluated the new and original methods under NFG, the Prediction Consistency (PC), and traditional classification metrics on the German Credit Approval dataset. The results showed that the two models achieved similar statistical mean performances over five-fold cross-validation. Furthermore, the proposed metric showed that PC scores can be misleading as the scores can be high and statistically similar to fairness-enhanced models while NFG scores are small. This work therefore provides new insights into when a GLR effectively enhances individual fairness and the pitfalls of PC.
5/9/2024