Outlier Gradient Analysis: Efficiently Improving Deep Learning Model Performance via Hessian-Free Influence Functions
2405.03869
0
0

Abstract
Influence functions offer a robust framework for assessing the impact of each training data sample on model predictions, serving as a prominent tool in data-centric learning. Despite their widespread use in various tasks, the strong convexity assumption on the model and the computational cost associated with calculating the inverse of the Hessian matrix pose constraints, particularly when analyzing large deep models. This paper focuses on a classical data-centric scenario--trimming detrimental samples--and addresses both challenges within a unified framework. Specifically, we establish an equivalence transformation between identifying detrimental training samples via influence functions and outlier gradient detection. This transformation not only presents a straightforward and Hessian-free formulation but also provides profound insights into the role of the gradient in sample impact. Moreover, it relaxes the convexity assumption of influence functions, extending their applicability to non-convex deep models. Through systematic empirical evaluations, we first validate the correctness of our proposed outlier gradient analysis on synthetic datasets and then demonstrate its effectiveness in detecting mislabeled samples in vision models, selecting data samples for improving performance of transformer models for natural language processing, and identifying influential samples for fine-tuned Large Language Models.
Create account to get full access
Overview
- This paper introduces a novel approach called "Outlier Gradient Analysis" (OGA) that can efficiently improve the performance of deep learning models.
- OGA leverages Hessian-free influence functions to identify and prioritize the most influential training samples, allowing for targeted model improvements.
- The method is shown to outperform existing techniques for sample selection and fine-tuning, leading to significant gains in model accuracy.
Plain English Explanation
Deep learning models are powerful tools for various tasks, but they can be complex and difficult to understand. Outlier Gradient Analysis: Efficiently Improving Deep Learning Model Performance via Hessian-Free Influence Functions introduces a new technique called Outlier Gradient Analysis (OGA) that can help improve the performance of these models in a more efficient way.
The key idea behind OGA is to identify the most influential training samples, or "outliers," that have a significant impact on the model's learning process. By focusing on these important samples, the researchers can fine-tune the model in a targeted manner, leading to better overall performance.
To identify the influential samples, OGA uses a mathematical concept called "Hessian-free influence functions." This allows the method to efficiently calculate the impact of each training sample on the model's predictions, without the need for computationally expensive techniques like Unifying Low-Dimensional Observations in Deep Learning Through Convex Optimization or High-Dimensional Analysis Reveals Conservative Sharpening of Stochastic Gradient Descent.
The researchers show that OGA outperforms existing methods for sample selection and fine-tuning, resulting in significant improvements in model accuracy across various datasets and tasks. This suggests that the technique could be a valuable tool for researchers and practitioners working with deep learning models, helping them to optimize model performance in a more efficient and targeted way.
Technical Explanation
The paper introduces a novel approach called "Outlier Gradient Analysis" (OGA) that can efficiently improve the performance of deep learning models. The key idea behind OGA is to leverage Hessian-free influence functions to identify the most influential training samples, or "outliers," and then use this information to fine-tune the model in a targeted manner.
The researchers first formulate the problem of identifying influential training samples as an optimization problem, where the goal is to find the samples that have the largest impact on the model's predictions. They then show that this problem can be solved efficiently using Hessian-free influence functions, which allow for the computation of the gradient of the model's output with respect to each training sample without the need for expensive techniques like Distilled Data-Model Reverse Gradient Matching or Inverse-Free Fast Natural Gradient Descent Method.
The researchers evaluate the performance of OGA on a variety of deep learning tasks and datasets, and show that it outperforms existing methods for sample selection and fine-tuning. They demonstrate that by focusing on the most influential training samples, OGA can lead to significant improvements in model accuracy, often outperforming state-of-the-art approaches.
Critical Analysis
The paper presents a compelling and well-designed study, but there are a few potential limitations and areas for further research:
-
Computational Complexity: While the Hessian-free influence functions used in OGA are more efficient than traditional techniques, the computation may still be computationally demanding, especially for large-scale models and datasets. It would be useful to explore ways to further optimize the algorithm or provide guidance on when OGA is most applicable.
-
Generalization Across Domains: The paper evaluates OGA on a range of tasks and datasets, but it would be valuable to see how well the method generalizes to even more diverse problem domains, particularly those with different data modalities or more complex model architectures.
-
Interpretability and Transparency: The paper does not delve deeply into the interpretability of the outliers identified by OGA or the insights they provide about the model's decision-making process. Exploring ways to make the method more transparent and provide meaningful explanations could further enhance its usefulness.
-
Potential Biases: While OGA aims to improve model performance, it is important to consider whether the method could inadvertently introduce or exacerbate biases in the model, particularly when dealing with sensitive or high-stakes applications. Further research on the fairness and robustness implications of OGA would be valuable.
Overall, the Outlier Gradient Analysis method presented in this paper represents a promising approach for improving deep learning model performance, and the researchers have demonstrated its effectiveness through rigorous experimentation. However, continued exploration of the method's limitations and potential refinements could further enhance its utility and impact.
Conclusion
The paper introduces a novel technique called Outlier Gradient Analysis (OGA) that can efficiently improve the performance of deep learning models. By leveraging Hessian-free influence functions to identify the most influential training samples, OGA allows for targeted model fine-tuning, leading to significant gains in accuracy across a variety of tasks and datasets.
The work demonstrates the value of developing advanced techniques for understanding and optimizing the behavior of complex deep learning models. By focusing on the most impactful training samples, OGA represents a promising approach for researchers and practitioners looking to enhance the performance and robustness of their deep learning systems. As the field of deep learning continues to evolve, methods like OGA will likely play an increasingly important role in unlocking the full potential of these powerful AI models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Revisit, Extend, and Enhance Hessian-Free Influence Functions
Ziao Yang, Han Yue, Jian Chen, Hongfu Liu
0
0
Influence functions serve as crucial tools for assessing sample influence in model interpretation, subset training set selection, noisy label detection, and more. By employing the first-order Taylor extension, influence functions can estimate sample influence without the need for expensive model retraining. However, applying influence functions directly to deep models presents challenges, primarily due to the non-convex nature of the loss function and the large size of model parameters. This difficulty not only makes computing the inverse of the Hessian matrix costly but also renders it non-existent in some cases. Various approaches, including matrix decomposition, have been explored to expedite and approximate the inversion of the Hessian matrix, with the aim of making influence functions applicable to deep models. In this paper, we revisit a specific, albeit naive, yet effective approximation method known as TracIn. This method substitutes the inverse of the Hessian matrix with an identity matrix. We provide deeper insights into why this simple approximation method performs well. Furthermore, we extend its applications beyond measuring model utility to include considerations of fairness and robustness. Finally, we enhance TracIn through an ensemble strategy. To validate its effectiveness, we conduct experiments on synthetic data and extensive evaluations on noisy label detection, sample selection for large language model fine-tuning, and defense against adversarial attacks.
5/29/2024
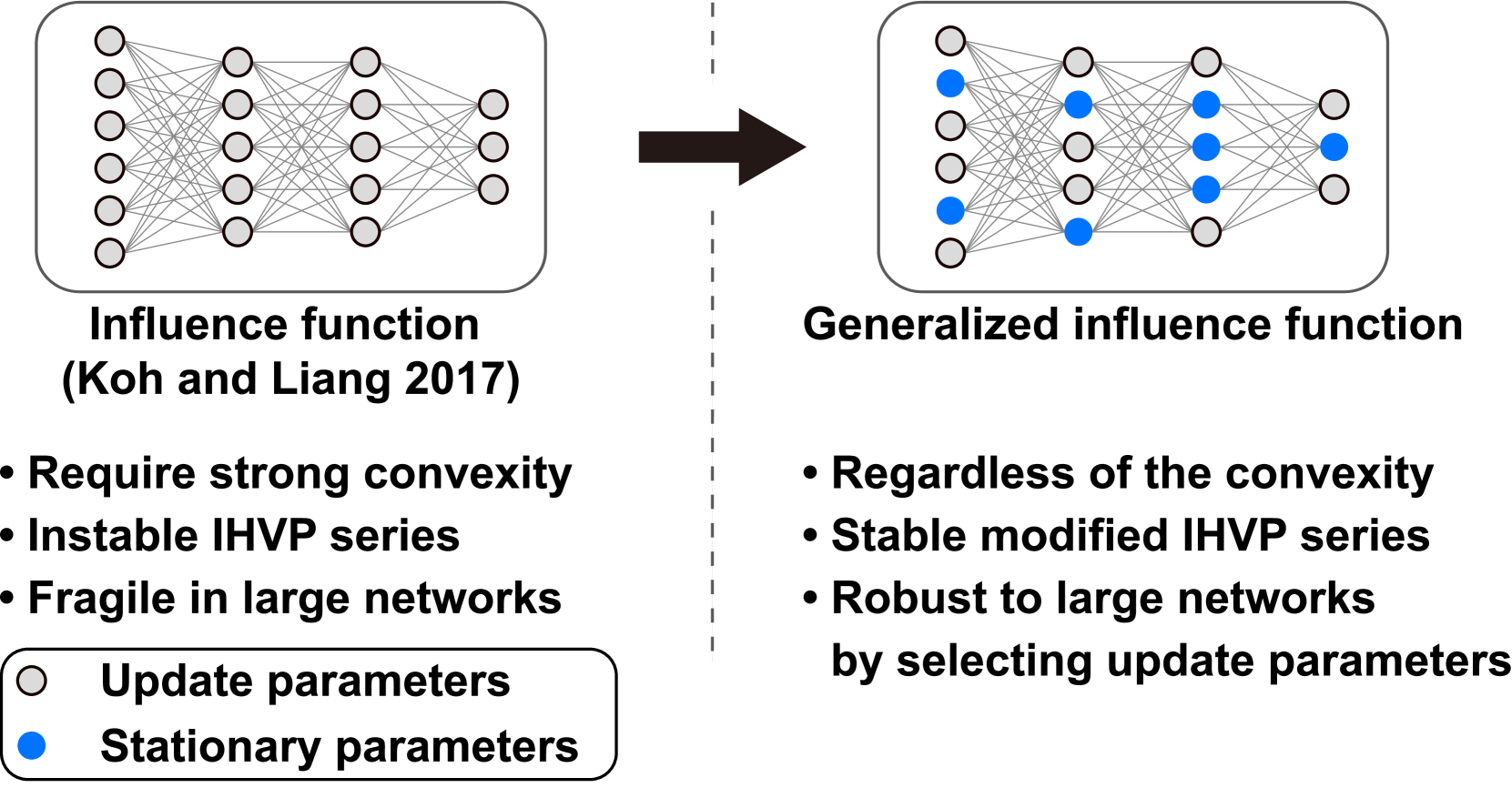
Deeper Understanding of Black-box Predictions via Generalized Influence Functions
Hyeonsu Lyu, Jonggyu Jang, Sehyun Ryu, Hyun Jong Yang
0
0
Influence functions (IFs) elucidate how training data changes model behavior. However, the increasing size and non-convexity in large-scale models make IFs inaccurate. We suspect that the fragility comes from the first-order approximation which may cause nuisance changes in parameters irrelevant to the examined data. However, simply computing influence from the chosen parameters can be misleading, as it fails to nullify the hidden effects of unselected parameters on the analyzed data. Thus, our approach introduces generalized IFs, precisely estimating target parameters' influence while nullifying nuisance gradient changes on fixed parameters. We identify target update parameters closely associated with the input data by the output- and gradient-based parameter selection methods. We verify the generalized IFs with various alternatives of IFs on the class removal and label change tasks. The experiments align with the less is more philosophy, demonstrating that updating only 5% of the model produces more accurate results than other influence functions across all tasks. We believe our proposal works as a foundational tool for optimizing models, conducting data analysis, and enhancing AI interpretability beyond the limitation of IFs. Codes are available at https://github.com/hslyu/GIF.
5/7/2024

The Mirrored Influence Hypothesis: Efficient Data Influence Estimation by Harnessing Forward Passes
Myeongseob Ko, Feiyang Kang, Weiyan Shi, Ming Jin, Zhou Yu, Ruoxi Jia
0
0
Large-scale black-box models have become ubiquitous across numerous applications. Understanding the influence of individual training data sources on predictions made by these models is crucial for improving their trustworthiness. Current influence estimation techniques involve computing gradients for every training point or repeated training on different subsets. These approaches face obvious computational challenges when scaled up to large datasets and models. In this paper, we introduce and explore the Mirrored Influence Hypothesis, highlighting a reciprocal nature of influence between training and test data. Specifically, it suggests that evaluating the influence of training data on test predictions can be reformulated as an equivalent, yet inverse problem: assessing how the predictions for training samples would be altered if the model were trained on specific test samples. Through both empirical and theoretical validations, we demonstrate the wide applicability of our hypothesis. Inspired by this, we introduce a new method for estimating the influence of training data, which requires calculating gradients for specific test samples, paired with a forward pass for each training point. This approach can capitalize on the common asymmetry in scenarios where the number of test samples under concurrent examination is much smaller than the scale of the training dataset, thus gaining a significant improvement in efficiency compared to existing approaches. We demonstrate the applicability of our method across a range of scenarios, including data attribution in diffusion models, data leakage detection, analysis of memorization, mislabeled data detection, and tracing behavior in language models. Our code will be made available at https://github.com/ruoxi-jia-group/Forward-INF.
6/21/2024
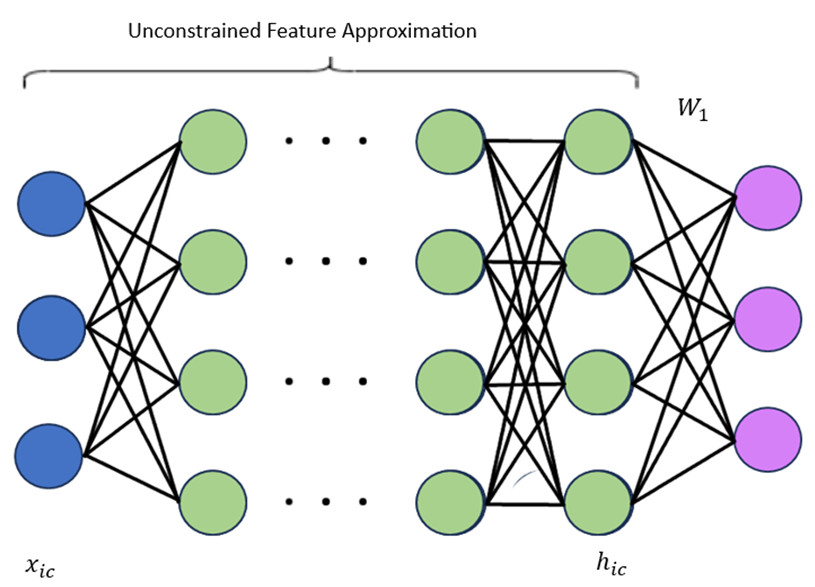
Unifying Low Dimensional Observations in Deep Learning Through the Deep Linear Unconstrained Feature Model
Connall Garrod, Jonathan P. Keating
0
0
Modern deep neural networks have achieved high performance across various tasks. Recently, researchers have noted occurrences of low-dimensional structure in the weights, Hessian's, gradients, and feature vectors of these networks, spanning different datasets and architectures when trained to convergence. In this analysis, we theoretically demonstrate these observations arising, and show how they can be unified within a generalized unconstrained feature model that can be considered analytically. Specifically, we consider a previously described structure called Neural Collapse, and its multi-layer counterpart, Deep Neural Collapse, which emerges when the network approaches global optima. This phenomenon explains the other observed low-dimensional behaviours on a layer-wise level, such as the bulk and outlier structure seen in Hessian spectra, and the alignment of gradient descent with the outlier eigenspace of the Hessian. Empirical results in both the deep linear unconstrained feature model and its non-linear equivalent support these predicted observations.
4/10/2024